 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProCap: Projection-Aware Captioning for Spatial Augmented Reality
Apr 01, 2026Spatial augmented reality (SAR) directly projects digital content onto physical scenes using projectors, creating immersive experience without head-mounted displays. However, for SAR to support intelligent interaction, such as reasoning about the scene or answering user queries, it must semantically distinguish between the physical scene and the projected content. Standard Vision Language Models (VLMs) struggle with this virtual-physical ambiguity, often confusing the two contexts. To address this issue, we introduce ProCap, a novel framework that explicitly decouples projected content from physical scenes. ProCap employs a two-stage pipeline: first it visually isolates virtual and physical layers via automated segmentation; then it uses region-aware retrieval to avoid ambiguous semantic context due to projection distortion. To support this, we present RGBP (RGB + Projections), the first large-scale SAR semantic benchmark dataset, featuring 65 diverse physical scenes and over 180,000 projections with dense, decoupled annotations. Finally, we establish a dual-captioning evaluation protocol using task-specific tokens to assess physical scene and projection descriptions independently. Our experiments show that ProCap provides a robust semantic foundation for future SAR research. The source code, pre-trained models and the RGBP dataset are available on the project page: https://ZimoCao.github.io/ProCap/.
LAPIG: Language Guided Projector Image Generation with Surface Adaptation and Stylization
Mar 15, 2025
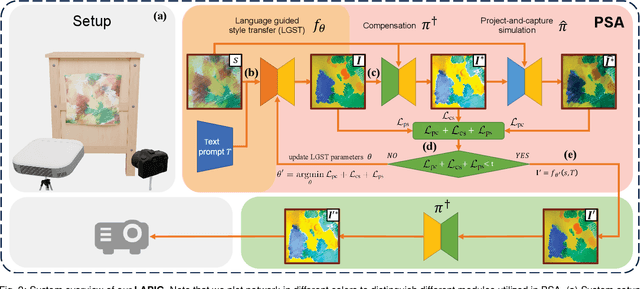

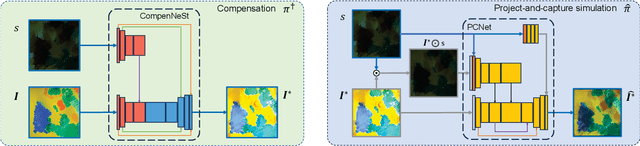
We propose LAPIG, a language guided projector image generation method with surface adaptation and stylization. LAPIG consists of a projector-camera system and a target textured projection surface. LAPIG takes the user text prompt as input and aims to transform the surface style using the projector. LAPIG's key challenge is that due to the projector's physical brightness limitation and the surface texture, the viewer's perceived projection may suffer from color saturation and artifacts in both dark and bright regions, such that even with the state-of-the-art projector compensation techniques, the viewer may see clear surface texture-related artifacts. Therefore, how to generate a projector image that follows the user's instruction while also displaying minimum surface artifacts is an open problem. To address this issue, we propose projection surface adaptation (PSA) that can generate compensable surface stylization. We first train two networks to simulate the projector compensation and project-and-capture processes, this allows us to find a satisfactory projector image without real project-and-capture and utilize gradient descent for fast convergence. Then, we design content and saturation losses to guide the projector image generation, such that the generated image shows no clearly perceivable artifacts when projected. Finally, the generated image is projected for visually pleasing surface style morphing effects. The source code and video are available on the project page: https://Yu-chen-Deng.github.io/LAPIG/.
Multi-Modal One-Shot Federated Ensemble Learning for Medical Data with Vision Large Language Model
Jan 06, 2025



Federated learning (FL) has attracted considerable interest in the medical domain due to its capacity to facilitate collaborative model training while maintaining data privacy. However, conventional FL methods typically necessitate multiple communication rounds, leading to significant communication overhead and delays, especially in environments with limited bandwidth. One-shot federated learning addresses these issues by conducting model training and aggregation in a single communication round, thereby reducing communication costs while preserving privacy. Among these, one-shot federated ensemble learning combines independently trained client models using ensemble techniques such as voting, further boosting performance in non-IID data scenarios. On the other hand, existing machine learning methods in healthcare predominantly use unimodal data (e.g., medical images or textual reports), which restricts their diagnostic accuracy and comprehensiveness. Therefore, the integration of multi-modal data is proposed to address these shortcomings. In this paper, we introduce FedMME, an innovative one-shot multi-modal federated ensemble learning framework that utilizes multi-modal data for medical image analysis. Specifically, FedMME capitalizes on vision large language models to produce textual reports from medical images, employs a BERT model to extract textual features from these reports, and amalgamates these features with visual features to improve diagnostic accuracy. Experimental results show that our method demonstrated superior performance compared to existing one-shot federated learning methods in healthcare scenarios across four datasets with various data distributions. For instance, it surpasses existing one-shot federated learning approaches by more than 17.5% in accuracy on the RSNA dataset when applying a Dirichlet distribution with ($\alpha$ = 0.3).
Data-Free Federated Class Incremental Learning with Diffusion-Based Generative Memory
May 22, 2024Federated Class Incremental Learning (FCIL) is a critical yet largely underexplored issue that deals with the dynamic incorporation of new classes within federated learning (FL). Existing methods often employ generative adversarial networks (GANs) to produce synthetic images to address privacy concerns in FL. However, GANs exhibit inherent instability and high sensitivity, compromising the effectiveness of these methods. In this paper, we introduce a novel data-free federated class incremental learning framework with diffusion-based generative memory (DFedDGM) to mitigate catastrophic forgetting by generating stable, high-quality images through diffusion models. We design a new balanced sampler to help train the diffusion models to alleviate the common non-IID problem in FL, and introduce an entropy-based sample filtering technique from an information theory perspective to enhance the quality of generative samples. Finally, we integrate knowledge distillation with a feature-based regularization term for better knowledge transfer. Our framework does not incur additional communication costs compared to the baseline FedAvg method. Extensive experiments across multiple datasets demonstrate that our method significantly outperforms existing baselines, e.g., over a 4% improvement in average accuracy on the Tiny-ImageNet dataset.
One-Shot Sequential Federated Learning for Non-IID Data by Enhancing Local Model Diversity
Apr 18, 2024Traditional federated learning mainly focuses on parallel settings (PFL), which can suffer significant communication and computation costs. In contrast, one-shot and sequential federated learning (SFL) have emerged as innovative paradigms to alleviate these costs. However, the issue of non-IID (Independent and Identically Distributed) data persists as a significant challenge in one-shot and SFL settings, exacerbated by the restricted communication between clients. In this paper, we improve the one-shot sequential federated learning for non-IID data by proposing a local model diversity-enhancing strategy. Specifically, to leverage the potential of local model diversity for improving model performance, we introduce a local model pool for each client that comprises diverse models generated during local training, and propose two distance measurements to further enhance the model diversity and mitigate the effect of non-IID data. Consequently, our proposed framework can improve the global model performance while maintaining low communication costs. Extensive experiments demonstrate that our method exhibits superior performance to existing one-shot PFL methods and achieves better accuracy compared with state-of-the-art one-shot SFL methods on both label-skew and domain-shift tasks (e.g., 6%+ accuracy improvement on the CIFAR-10 dataset).