 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSetup-Independent Full Projector Compensation
Apr 02, 2026Projector compensation seeks to correct geometric and photometric distortions that occur when images are projected onto nonplanar or textured surfaces. However, most existing methods are highly setup-dependent, requiring fine-tuning or retraining whenever the surface, lighting, or projector-camera pose changes. Progress has been limited by two key challenges: (1) the absence of large, diverse training datasets and (2) existing geometric correction models are typically constrained by specific spatial setups; without further retraining or fine-tuning, they often fail to generalize directly to novel geometric configurations. We introduce SIComp, the first Setup-Independent framework for full projector Compensation, capable of generalizing to unseen setups without fine-tuning or retraining. To enable this, we construct a large-scale real-world dataset spanning 277 distinct projector-camera setups. SIComp adopts a co-adaptive design that decouples geometry and photometry: A carefully tailored optical flow module performs online geometric correction, while a novel photometric network handles photometric compensation. To further enhance robustness under varying illumination, we integrate intensity-varying surface priors into the network design. Extensive experiments demonstrate that SIComp consistently produces high-quality compensation across diverse unseen setups, substantially outperforming existing methods in terms of generalization ability and establishing the first generalizable solution to projector compensation. The code and dataset are available on our project page: https://hai-bo-li.github.io/SIComp/
ProCap: Projection-Aware Captioning for Spatial Augmented Reality
Apr 01, 2026Spatial augmented reality (SAR) directly projects digital content onto physical scenes using projectors, creating immersive experience without head-mounted displays. However, for SAR to support intelligent interaction, such as reasoning about the scene or answering user queries, it must semantically distinguish between the physical scene and the projected content. Standard Vision Language Models (VLMs) struggle with this virtual-physical ambiguity, often confusing the two contexts. To address this issue, we introduce ProCap, a novel framework that explicitly decouples projected content from physical scenes. ProCap employs a two-stage pipeline: first it visually isolates virtual and physical layers via automated segmentation; then it uses region-aware retrieval to avoid ambiguous semantic context due to projection distortion. To support this, we present RGBP (RGB + Projections), the first large-scale SAR semantic benchmark dataset, featuring 65 diverse physical scenes and over 180,000 projections with dense, decoupled annotations. Finally, we establish a dual-captioning evaluation protocol using task-specific tokens to assess physical scene and projection descriptions independently. Our experiments show that ProCap provides a robust semantic foundation for future SAR research. The source code, pre-trained models and the RGBP dataset are available on the project page: https://ZimoCao.github.io/ProCap/.
LAPIG: Language Guided Projector Image Generation with Surface Adaptation and Stylization
Mar 15, 2025
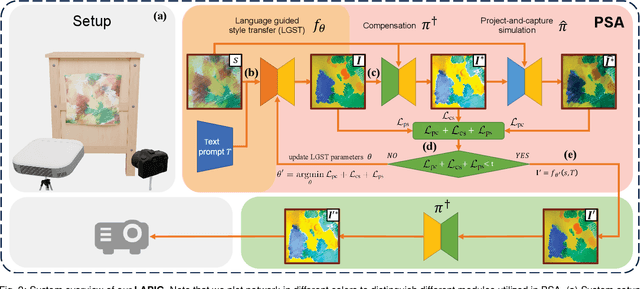

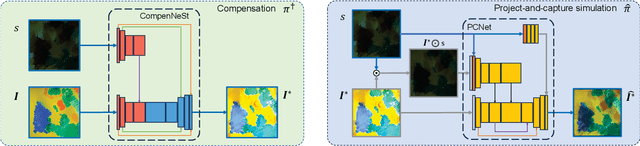
We propose LAPIG, a language guided projector image generation method with surface adaptation and stylization. LAPIG consists of a projector-camera system and a target textured projection surface. LAPIG takes the user text prompt as input and aims to transform the surface style using the projector. LAPIG's key challenge is that due to the projector's physical brightness limitation and the surface texture, the viewer's perceived projection may suffer from color saturation and artifacts in both dark and bright regions, such that even with the state-of-the-art projector compensation techniques, the viewer may see clear surface texture-related artifacts. Therefore, how to generate a projector image that follows the user's instruction while also displaying minimum surface artifacts is an open problem. To address this issue, we propose projection surface adaptation (PSA) that can generate compensable surface stylization. We first train two networks to simulate the projector compensation and project-and-capture processes, this allows us to find a satisfactory projector image without real project-and-capture and utilize gradient descent for fast convergence. Then, we design content and saturation losses to guide the projector image generation, such that the generated image shows no clearly perceivable artifacts when projected. Finally, the generated image is projected for visually pleasing surface style morphing effects. The source code and video are available on the project page: https://Yu-chen-Deng.github.io/LAPIG/.
DPCS: Path Tracing-Based Differentiable Projector-Camera Systems
Mar 15, 2025Projector-camera systems (ProCams) simulation aims to model the physical project-and-capture process and associated scene parameters of a ProCams, and is crucial for spatial augmented reality (SAR) applications such as ProCams relighting and projector compensation. Recent advances use an end-to-end neural network to learn the project-and-capture process. However, these neural network-based methods often implicitly encapsulate scene parameters, such as surface material, gamma, and white balance in the network parameters, and are less interpretable and hard for novel scene simulation. Moreover, neural networks usually learn the indirect illumination implicitly in an image-to-image translation way which leads to poor performance in simulating complex projection effects such as soft-shadow and interreflection. In this paper, we introduce a novel path tracing-based differentiable projector-camera systems (DPCS), offering a differentiable ProCams simulation method that explicitly integrates multi-bounce path tracing. Our DPCS models the physical project-and-capture process using differentiable physically-based rendering (PBR), enabling the scene parameters to be explicitly decoupled and learned using much fewer samples. Moreover, our physically-based method not only enables high-quality downstream ProCams tasks, such as ProCams relighting and projector compensation, but also allows novel scene simulation using the learned scene parameters. In experiments, DPCS demonstrates clear advantages over previous approaches in ProCams simulation, offering better interpretability, more efficient handling of complex interreflection and shadow, and requiring fewer training samples.
NeuroPump: Simultaneous Geometric and Color Rectification for Underwater Images
Dec 20, 2024

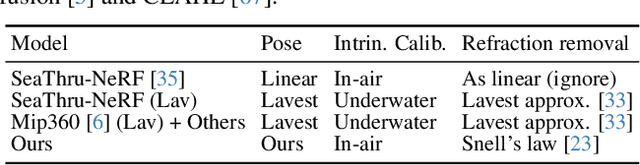
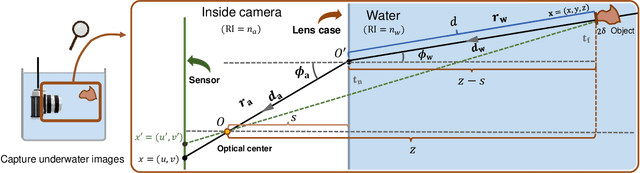
Underwater image restoration aims to remove geometric and color distortions due to water refraction, absorption and scattering. Previous studies focus on restoring either color or the geometry, but to our best knowledge, not both. However, in practice it may be cumbersome to address the two rectifications one-by-one. In this paper, we propose NeuroPump, a self-supervised method to simultaneously optimize and rectify underwater geometry and color as if water were pumped out. The key idea is to explicitly model refraction, absorption and scattering in Neural Radiance Field (NeRF) pipeline, such that it not only performs simultaneous geometric and color rectification, but also enables to synthesize novel views and optical effects by controlling the decoupled parameters. In addition, to address issue of lack of real paired ground truth images, we propose an underwater 360 benchmark dataset that has real paired (i.e., with and without water) images. Our method clearly outperforms other baselines both quantitatively and qualitatively.
GS-ProCams: Gaussian Splatting-based Projector-Camera Systems
Dec 16, 2024



We present GS-ProCams, the first Gaussian Splatting-based framework for projector-camera systems (ProCams). GS-ProCams significantly enhances the efficiency of projection mapping (PM) that requires establishing geometric and radiometric mappings between the projector and the camera. Previous CNN-based ProCams are constrained to a specific viewpoint, limiting their applicability to novel perspectives. In contrast, NeRF-based ProCams support view-agnostic projection mapping, however, they require an additional colocated light source and demand significant computational and memory resources. To address this issue, we propose GS-ProCams that employs 2D Gaussian for scene representations, and enables efficient view-agnostic ProCams applications. In particular, we explicitly model the complex geometric and photometric mappings of ProCams using projector responses, the target surface's geometry and materials represented by Gaussians, and global illumination component. Then, we employ differentiable physically-based rendering to jointly estimate them from captured multi-view projections. Compared to state-of-the-art NeRF-based methods, our GS-ProCams eliminates the need for additional devices, achieving superior ProCams simulation quality. It is also 600 times faster and uses only 1/10 of the GPU memory.
CompenHR: Efficient Full Compensation for High-resolution Projector
Nov 28, 2023



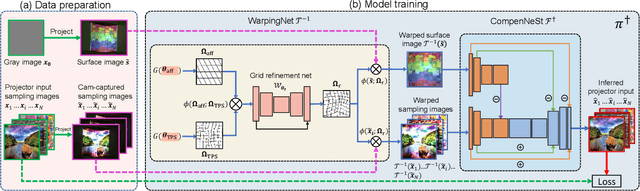
Full projector compensation is a practical task of projector-camera systems. It aims to find a projector input image, named compensation image, such that when projected it cancels the geometric and photometric distortions due to the physical environment and hardware. State-of-the-art methods use deep learning to address this problem and show promising performance for low-resolution setups. However, directly applying deep learning to high-resolution setups is impractical due to the long training time and high memory cost. To address this issue, this paper proposes a practical full compensation solution. Firstly, we design an attention-based grid refinement network to improve geometric correction quality. Secondly, we integrate a novel sampling scheme into an end-to-end compensation network to alleviate computation and introduce attention blocks to preserve key features. Finally, we construct a benchmark dataset for high-resolution projector full compensation. In experiments, our method demonstrates clear advantages in both efficiency and quality.
Modeling Deep Learning Based Privacy Attacks on Physical Mail
Dec 22, 2020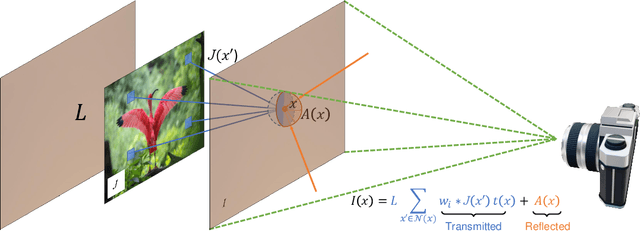

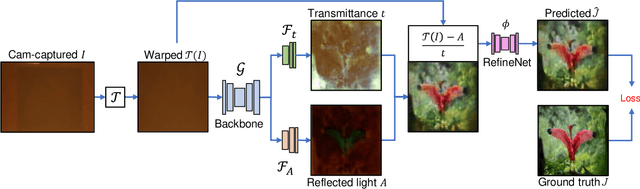

Mail privacy protection aims to prevent unauthorized access to hidden content within an envelope since normal paper envelopes are not as safe as we think. In this paper, for the first time, we show that with a well designed deep learning model, the hidden content may be largely recovered without opening the envelope. We start by modeling deep learning-based privacy attacks on physical mail content as learning the mapping from the camera-captured envelope front face image to the hidden content, then we explicitly model the mapping as a combination of perspective transformation, image dehazing and denoising using a deep convolutional neural network, named Neural-STE (See-Through-Envelope). We show experimentally that hidden content details, such as texture and image structure, can be clearly recovered. Finally, our formulation and model allow us to design envelopes that can counter deep learning-based privacy attacks on physical mail.
SPAA: Stealthy Projector-based Adversarial Attacks on Deep Image Classifiers
Dec 10, 2020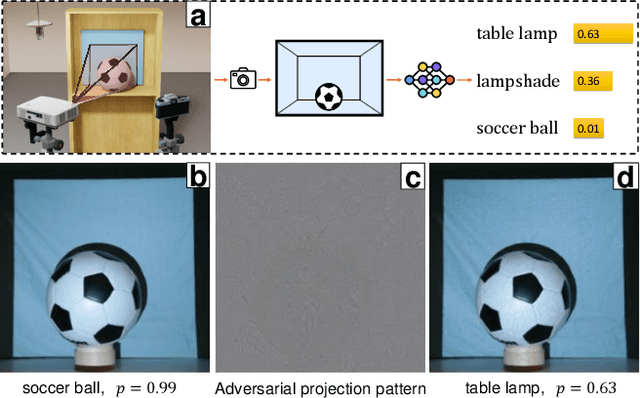
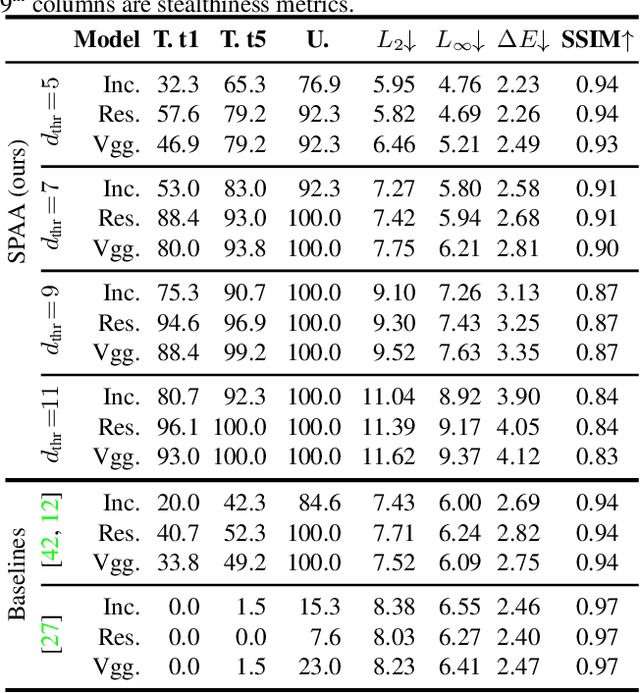

Light-based adversarial attacks aim to fool deep learning-based image classifiers by altering the physical light condition using a controllable light source, e.g., a projector. Compared with physical attacks that place carefully designed stickers or printed adversarial objects, projector-based ones obviate modifying the physical entities. Moreover, projector-based attacks can be performed transiently and dynamically by altering the projection pattern. However, existing approaches focus on projecting adversarial patterns that result in clearly perceptible camera-captured perturbations, while the more interesting yet challenging goal, stealthy projector-based attack, remains an open problem. In this paper, for the first time, we formulate this problem as an end-to-end differentiable process and propose Stealthy Projector-based Adversarial Attack (SPAA). In SPAA, we approximate the real project-and-capture operation using a deep neural network named PCNet, then we include PCNet in the optimization of projector-based attacks such that the generated adversarial projection is physically plausible. Finally, to generate robust and stealthy adversarial projections, we propose an optimization algorithm that uses minimum perturbation and adversarial confidence thresholds to alternate between the adversarial loss and stealthiness loss optimization. Our experimental evaluations show that the proposed SPAA clearly outperforms other methods by achieving higher attack success rates and meanwhile being stealthier.
End-to-end Full Projector Compensation
Aug 04, 2020


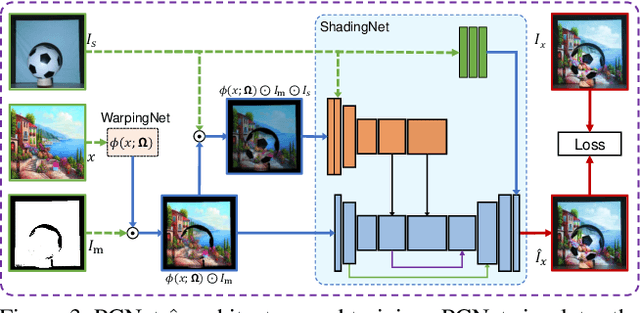
Full projector compensation aims to modify a projector input image to compensate for both geometric and photometric disturbance of the projection surface. Traditional methods usually solve the two parts separately and may suffer from suboptimal solutions. In this paper, we propose the first end-to-end differentiable solution, named CompenNeSt++, to solve the two problems jointly. First, we propose a novel geometric correction subnet, named WarpingNet, which is designed with a cascaded coarse-to-fine structure to learn the sampling grid directly from sampling images. Second, we propose a novel photometric compensation subnet, named CompenNeSt, which is designed with a siamese architecture to capture the photometric interactions between the projection surface and the projected images, and to use such information to compensate the geometrically corrected images. By concatenating WarpingNet with CompenNeSt, CompenNeSt++ accomplishes full projector compensation and is end-to-end trainable. Third, to improve practicability, we propose a novel synthetic data-based pre-training strategy to significantly reduce the number of training images and training time. Moreover, we construct the first setup-independent full compensation benchmark to facilitate future studies. In thorough experiments, our method shows clear advantages over prior art with promising compensation quality and meanwhile being practically convenient.