 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSatFusion: A Unified Framework for Enhancing Satellite IoT Images via Multi-Temporal and Multi-Source Data Fusion
Oct 09, 2025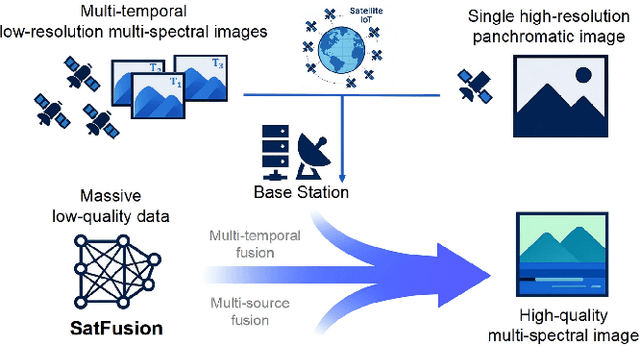
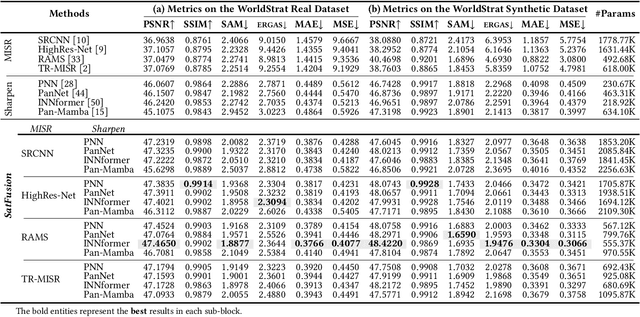
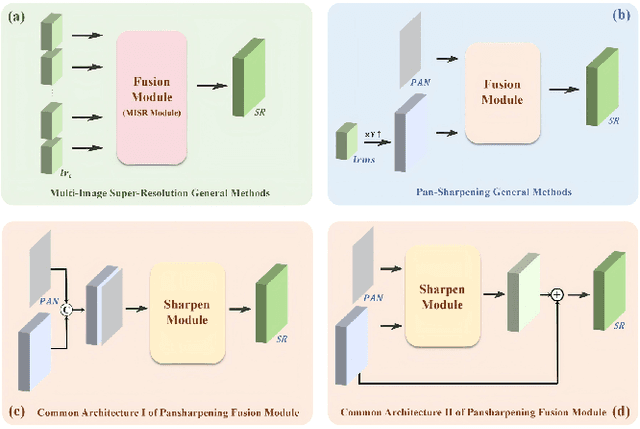
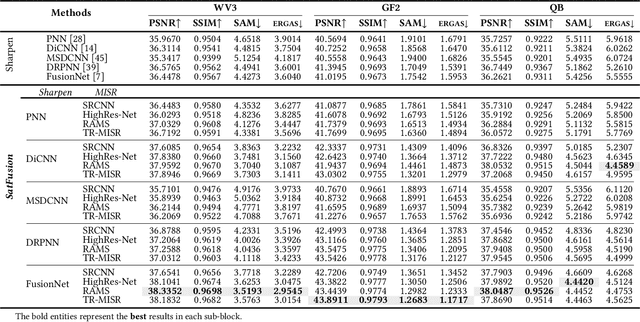
With the rapid advancement of the digital society, the proliferation of satellites in the Satellite Internet of Things (Sat-IoT) has led to the continuous accumulation of large-scale multi-temporal and multi-source images across diverse application scenarios. However, existing methods fail to fully exploit the complementary information embedded in both temporal and source dimensions. For example, Multi-Image Super-Resolution (MISR) enhances reconstruction quality by leveraging temporal complementarity across multiple observations, yet the limited fine-grained texture details in input images constrain its performance. Conversely, pansharpening integrates multi-source images by injecting high-frequency spatial information from panchromatic data, but typically relies on pre-interpolated low-resolution inputs and assumes noise-free alignment, making it highly sensitive to noise and misregistration. To address these issues, we propose SatFusion: A Unified Framework for Enhancing Satellite IoT Images via Multi-Temporal and Multi-Source Data Fusion. Specifically, SatFusion first employs a Multi-Temporal Image Fusion (MTIF) module to achieve deep feature alignment with the panchromatic image. Then, a Multi-Source Image Fusion (MSIF) module injects fine-grained texture information from the panchromatic data. Finally, a Fusion Composition module adaptively integrates the complementary advantages of both modalities while dynamically refining spectral consistency, supervised by a weighted combination of multiple loss functions. Extensive experiments on the WorldStrat, WV3, QB, and GF2 datasets demonstrate that SatFusion significantly improves fusion quality, robustness under challenging conditions, and generalizability to real-world Sat-IoT scenarios. The code is available at: https://github.com/dllgyufei/SatFusion.git.
Piccolo2: General Text Embedding with Multi-task Hybrid Loss Training
May 11, 2024



In this report, we introduce Piccolo2, an embedding model that surpasses other models in the comprehensive evaluation over 6 tasks on CMTEB benchmark, setting a new state-of-the-art. Piccolo2 primarily leverages an efficient multi-task hybrid loss training approach, effectively harnessing textual data and labels from diverse downstream tasks. In addition, Piccolo2 scales up the embedding dimension and uses MRL training to support more flexible vector dimensions. The latest information of piccolo models can be accessed via: https://huggingface.co/sensenova/
GLaMa: Joint Spatial and Frequency Loss for General Image Inpainting
May 15, 2022

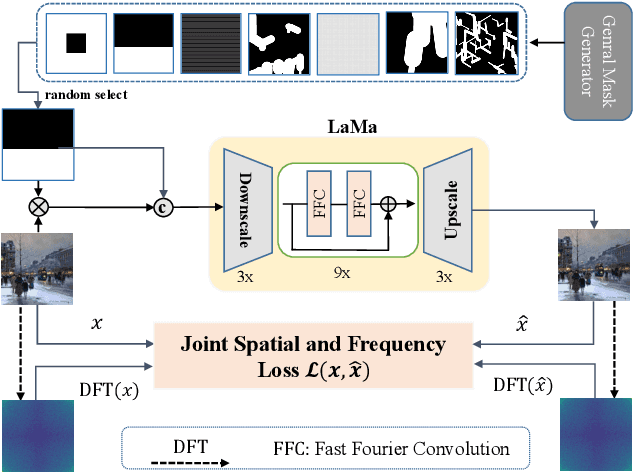
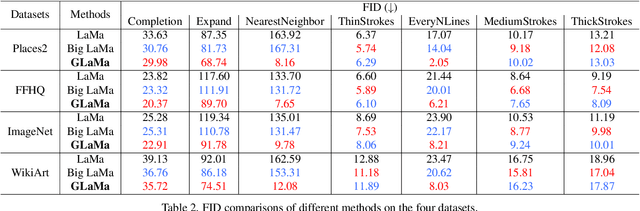
The purpose of image inpainting is to recover scratches and damaged areas using context information from remaining parts. In recent years, thanks to the resurgence of convolutional neural networks (CNNs), image inpainting task has made great breakthroughs. However, most of the work consider insufficient types of mask, and their performance will drop dramatically when encountering unseen masks. To combat these challenges, we propose a simple yet general method to solve this problem based on the LaMa image inpainting framework, dubbed GLaMa. Our proposed GLaMa can better capture different types of missing information by using more types of masks. By incorporating more degraded images in the training phase, we can expect to enhance the robustness of the model with respect to various masks. In order to yield more reasonable results, we further introduce a frequency-based loss in addition to the traditional spatial reconstruction loss and adversarial loss. In particular, we introduce an effective reconstruction loss both in the spatial and frequency domain to reduce the chessboard effect and ripples in the reconstructed image. Extensive experiments demonstrate that our method can boost the performance over the original LaMa method for each type of mask on FFHQ, ImageNet, Places2 and WikiArt dataset. The proposed GLaMa was ranked first in terms of PSNR, LPIPS and SSIM in the NTIRE 2022 Image Inpainting Challenge Track 1 Unsupervised.
One to Transfer All: A Universal Transfer Framework for Vision Foundation Model with Few Data
Nov 24, 2021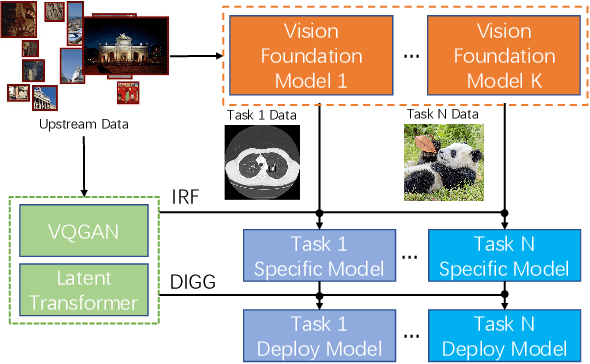
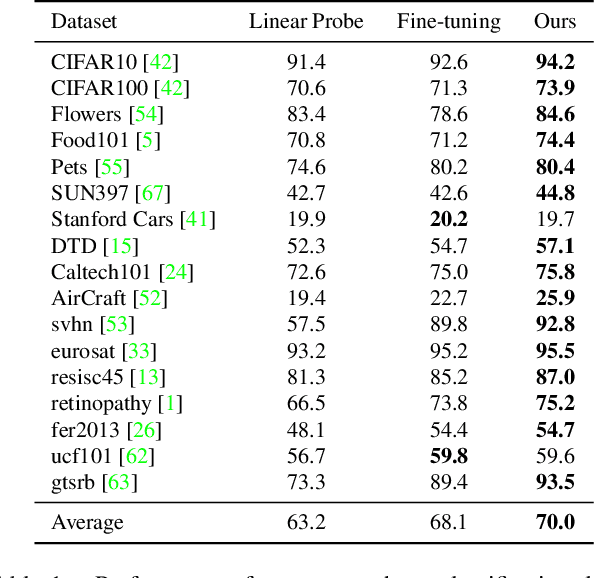
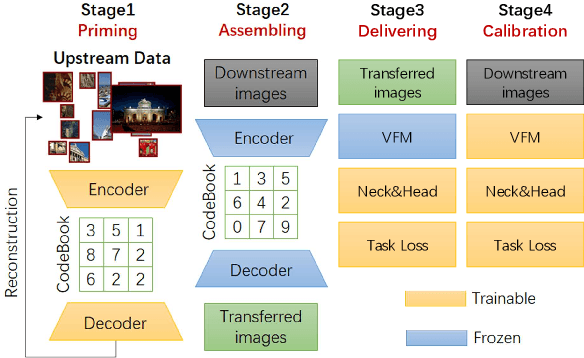

The foundation model is not the last chapter of the model production pipeline. Transferring with few data in a general way to thousands of downstream tasks is becoming a trend of the foundation model's application. In this paper, we proposed a universal transfer framework: One to Transfer All (OTA) to transfer any Vision Foundation Model (VFM) to any downstream tasks with few downstream data. We first transfer a VFM to a task-specific model by Image Re-representation Fine-tuning (IRF) then distilling knowledge from a task-specific model to a deployed model with data produced by Downstream Image-Guided Generation (DIGG). OTA has no dependency on upstream data, VFM, and downstream tasks when transferring. It also provides a way for VFM researchers to release their upstream information for better transferring but not leaking data due to privacy requirements. Massive experiments validate the effectiveness and superiority of our methods in few data setting. Our code will be released.