 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLaMa: Joint Spatial and Frequency Loss for General Image Inpainting
Paper and Code
May 15, 2022

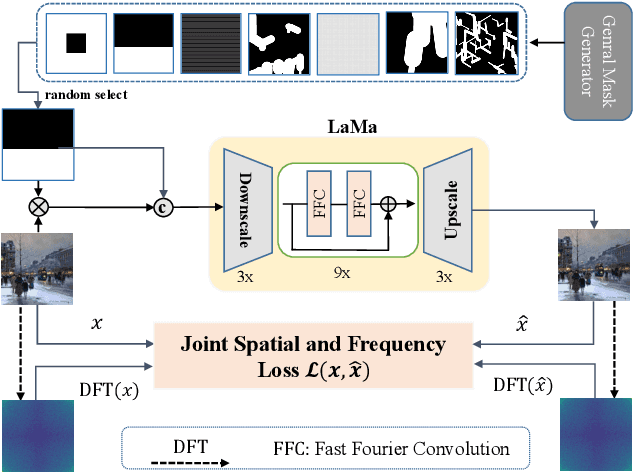
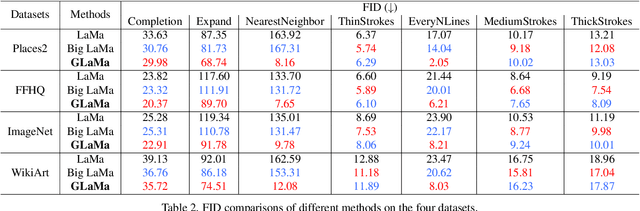
The purpose of image inpainting is to recover scratches and damaged areas using context information from remaining parts. In recent years, thanks to the resurgence of convolutional neural networks (CNNs), image inpainting task has made great breakthroughs. However, most of the work consider insufficient types of mask, and their performance will drop dramatically when encountering unseen masks. To combat these challenges, we propose a simple yet general method to solve this problem based on the LaMa image inpainting framework, dubbed GLaMa. Our proposed GLaMa can better capture different types of missing information by using more types of masks. By incorporating more degraded images in the training phase, we can expect to enhance the robustness of the model with respect to various masks. In order to yield more reasonable results, we further introduce a frequency-based loss in addition to the traditional spatial reconstruction loss and adversarial loss. In particular, we introduce an effective reconstruction loss both in the spatial and frequency domain to reduce the chessboard effect and ripples in the reconstructed image. Extensive experiments demonstrate that our method can boost the performance over the original LaMa method for each type of mask on FFHQ, ImageNet, Places2 and WikiArt dataset. The proposed GLaMa was ranked first in terms of PSNR, LPIPS and SSIM in the NTIRE 2022 Image Inpainting Challenge Track 1 Unsupervised.