 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiva-DiT: Residual-Based Differentiable Top-$k$ Selection for Efficient Diffusion Transformers
Feb 05, 2026Diffusion Transformers (DiTs) incur prohibitive computational costs due to the quadratic scaling of self-attention. Existing pruning methods fail to simultaneously satisfy differentiability, efficiency, and the strict static budgets required for hardware overhead. To address this, we propose Shiva-DiT, which effectively reconciles these conflicting requirements via Residual-Based Differentiable Top-$k$ Selection. By leveraging a residual-aware straight-through estimator, our method enforces deterministic token counts for static compilation while preserving end-to-end learnability through residual gradient estimation. Furthermore, we introduce a Context-Aware Router and Adaptive Ratio Policy to autonomously learn an adaptive pruning schedule. Experiments on mainstream models, including SD3.5, demonstrate that Shiva-DiT establishes a new Pareto frontier, achieving a 1.54$\times$ wall-clock speedup with superior fidelity compared to existing baselines, effectively eliminating ragged tensor overheads.
Adaptive Dual-Weighting Framework for Federated Learning via Out-of-Distribution Detection
Feb 01, 2026Federated Learning (FL) enables collaborative model training across large-scale distributed service nodes while preserving data privacy, making it a cornerstone of intelligent service systems in edge-cloud environments. However, in real-world service-oriented deployments, data generated by heterogeneous users, devices, and application scenarios are inherently non-IID. This severe data heterogeneity critically undermines the convergence stability, generalization ability, and ultimately the quality of service delivered by the global model. To address this challenge, we propose FLood, a novel FL framework inspired by out-of-distribution (OOD) detection. FLood dynamically counteracts the adverse effects of heterogeneity through a dual-weighting mechanism that jointly governs local training and global aggregation. At the client level, it adaptively reweights the supervised loss by upweighting pseudo-OOD samples, thereby encouraging more robust learning from distributionally misaligned or challenging data. At the server level, it refines model aggregation by weighting client contributions according to their OOD confidence scores, prioritizing updates from clients with higher in-distribution consistency and enhancing the global model's robustness and convergence stability. Extensive experiments across multiple benchmarks under diverse non-IID settings demonstrate that FLood consistently outperforms state-of-the-art FL methods in both accuracy and generalization. Furthermore, FLood functions as an orthogonal plug-in module: it seamlessly integrates with existing FL algorithms to boost their performance under heterogeneity without modifying their core optimization logic. These properties make FLood a practical and scalable solution for deploying reliable intelligent services in real-world federated environments.
TrackTeller: Temporal Multimodal 3D Grounding for Behavior-Dependent Object References
Dec 25, 2025Understanding natural-language references to objects in dynamic 3D driving scenes is essential for interactive autonomous systems. In practice, many referring expressions describe targets through recent motion or short-term interactions, which cannot be resolved from static appearance or geometry alone. We study temporal language-based 3D grounding, where the objective is to identify the referred object in the current frame by leveraging multi-frame observations. We propose TrackTeller, a temporal multimodal grounding framework that integrates LiDAR-image fusion, language-conditioned decoding, and temporal reasoning in a unified architecture. TrackTeller constructs a shared UniScene representation aligned with textual semantics, generates language-aware 3D proposals, and refines grounding decisions using motion history and short-term dynamics. Experiments on the NuPrompt benchmark demonstrate that TrackTeller consistently improves language-grounded tracking performance, outperforming strong baselines with a 70% relative improvement in Average Multi-Object Tracking Accuracy and a 3.15-3.4 times reduction in False Alarm Frequency.
SeMi: When Imbalanced Semi-Supervised Learning Meets Mining Hard Examples
Jan 10, 2025



Semi-Supervised Learning (SSL) can leverage abundant unlabeled data to boost model performance. However, the class-imbalanced data distribution in real-world scenarios poses great challenges to SSL, resulting in performance degradation. Existing class-imbalanced semi-supervised learning (CISSL) methods mainly focus on rebalancing datasets but ignore the potential of using hard examples to enhance performance, making it difficult to fully harness the power of unlabeled data even with sophisticated algorithms. To address this issue, we propose a method that enhances the performance of Imbalanced Semi-Supervised Learning by Mining Hard Examples (SeMi). This method distinguishes the entropy differences among logits of hard and easy examples, thereby identifying hard examples and increasing the utility of unlabeled data, better addressing the imbalance problem in CISSL. In addition, we maintain a class-balanced memory bank with confidence decay for storing high-confidence embeddings to enhance the pseudo-labels' reliability. Although our method is simple, it is effective and seamlessly integrates with existing approaches. We perform comprehensive experiments on standard CISSL benchmarks and experimentally demonstrate that our proposed SeMi outperforms existing state-of-the-art methods on multiple benchmarks, especially in reversed scenarios, where our best result shows approximately a 54.8\% improvement over the baseline methods.
Learning-Augmented Algorithms for the Bahncard Problem
Oct 20, 2024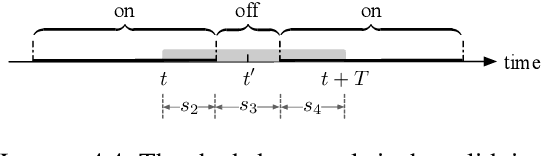



In this paper, we study learning-augmented algorithms for the Bahncard problem. The Bahncard problem is a generalization of the ski-rental problem, where a traveler needs to irrevocably and repeatedly decide between a cheap short-term solution and an expensive long-term one with an unknown future. Even though the problem is canonical, only a primal-dual-based learning-augmented algorithm was explicitly designed for it. We develop a new learning-augmented algorithm, named PFSUM, that incorporates both history and short-term future to improve online decision making. We derive the competitive ratio of PFSUM as a function of the prediction error and conduct extensive experiments to show that PFSUM outperforms the primal-dual-based algorithm.