 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepEBR: A Probabilistic Approach to Embedding Based Retrieval
Oct 25, 2024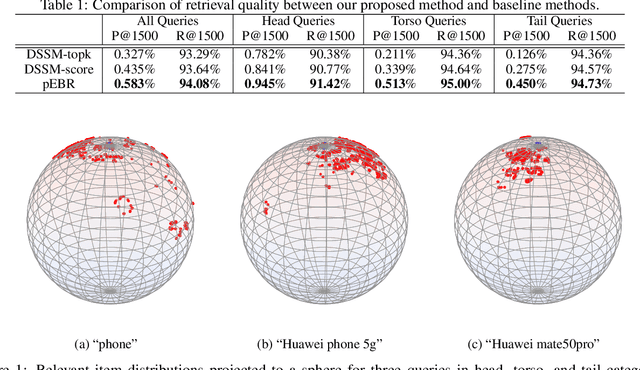
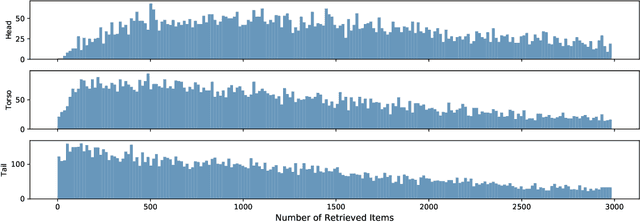

Embedding retrieval aims to learn a shared semantic representation space for both queries and items, thus enabling efficient and effective item retrieval using approximate nearest neighbor (ANN) algorithms. In current industrial practice, retrieval systems typically retrieve a fixed number of items for different queries, which actually leads to insufficient retrieval (low recall) for head queries and irrelevant retrieval (low precision) for tail queries. Mostly due to the trend of frequentist approach to loss function designs, till now there is no satisfactory solution to holistically address this challenge in the industry. In this paper, we move away from the frequentist approach, and take a novel \textbf{p}robabilistic approach to \textbf{e}mbedding \textbf{b}ased \textbf{r}etrieval (namely \textbf{pEBR}) by learning the item distribution for different queries, which enables a dynamic cosine similarity threshold calculated by the probabilistic cumulative distribution function (CDF) value. The experimental results show that our approach improves both the retrieval precision and recall significantly. Ablation studies also illustrate how the probabilistic approach is able to capture the differences between head and tail queries.