 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepEBR: A Probabilistic Approach to Embedding Based Retrieval
Oct 25, 2024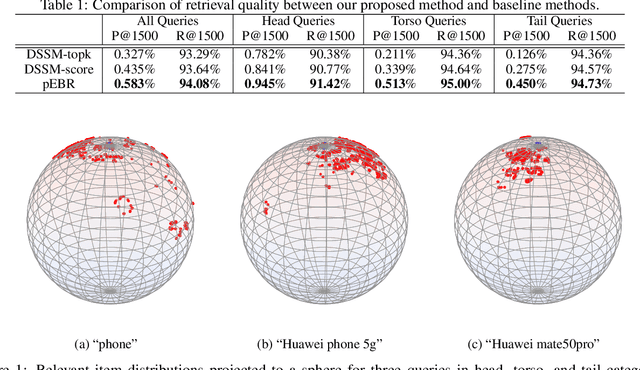
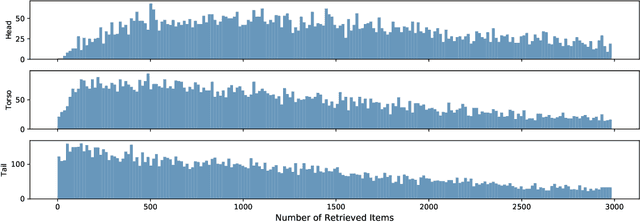

Embedding retrieval aims to learn a shared semantic representation space for both queries and items, thus enabling efficient and effective item retrieval using approximate nearest neighbor (ANN) algorithms. In current industrial practice, retrieval systems typically retrieve a fixed number of items for different queries, which actually leads to insufficient retrieval (low recall) for head queries and irrelevant retrieval (low precision) for tail queries. Mostly due to the trend of frequentist approach to loss function designs, till now there is no satisfactory solution to holistically address this challenge in the industry. In this paper, we move away from the frequentist approach, and take a novel \textbf{p}robabilistic approach to \textbf{e}mbedding \textbf{b}ased \textbf{r}etrieval (namely \textbf{pEBR}) by learning the item distribution for different queries, which enables a dynamic cosine similarity threshold calculated by the probabilistic cumulative distribution function (CDF) value. The experimental results show that our approach improves both the retrieval precision and recall significantly. Ablation studies also illustrate how the probabilistic approach is able to capture the differences between head and tail queries.
Differentiable Retrieval Augmentation via Generative Language Modeling for E-commerce Query Intent Classification
Aug 21, 2023Retrieval augmentation, which enhances downstream models by a knowledge retriever and an external corpus instead of by merely increasing the number of model parameters, has been successfully applied to many natural language processing (NLP) tasks such as text classification, question answering and so on. However, existing methods that separately or asynchronously train the retriever and downstream model mainly due to the non-differentiability between the two parts, usually lead to degraded performance compared to end-to-end joint training. In this paper, we propose Differentiable Retrieval Augmentation via Generative lANguage modeling(Dragan), to address this problem by a novel differentiable reformulation. We demonstrate the effectiveness of our proposed method on a challenging NLP task in e-commerce search, namely query intent classification. Both the experimental results and ablation study show that the proposed method significantly and reasonably improves the state-of-the-art baselines on both offline evaluation and online A/B test.
Pre-training Tasks for User Intent Detection and Embedding Retrieval in E-commerce Search
Aug 22, 2022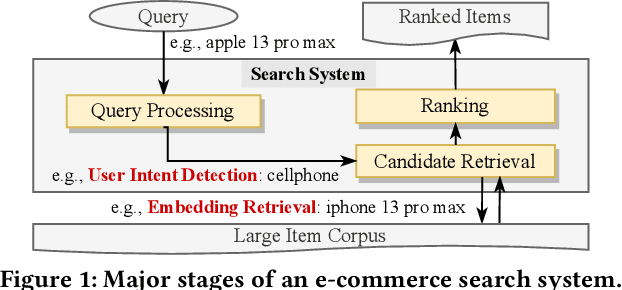

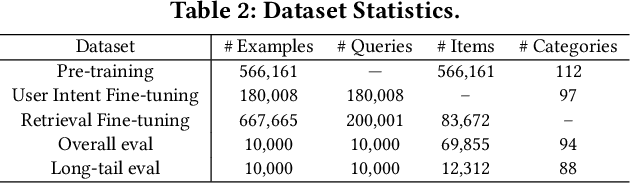
BERT-style models pre-trained on the general corpus (e.g., Wikipedia) and fine-tuned on specific task corpus, have recently emerged as breakthrough techniques in many NLP tasks: question answering, text classification, sequence labeling and so on. However, this technique may not always work, especially for two scenarios: a corpus that contains very different text from the general corpus Wikipedia, or a task that learns embedding spacial distribution for a specific purpose (e.g., approximate nearest neighbor search). In this paper, to tackle the above two scenarios that we have encountered in an industrial e-commerce search system, we propose customized and novel pre-training tasks for two critical modules: user intent detection and semantic embedding retrieval. The customized pre-trained models after fine-tuning, being less than 10% of BERT-base's size in order to be feasible for cost-efficient CPU serving, significantly improve the other baseline models: 1) no pre-training model and 2) fine-tuned model from the official pre-trained BERT using general corpus, on both offline datasets and online system. We have open sourced our datasets for the sake of reproducibility and future works.
Givens Coordinate Descent Methods for Rotation Matrix Learning in Trainable Embedding Indexes
Mar 09, 2022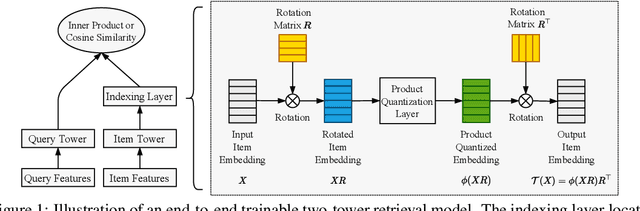
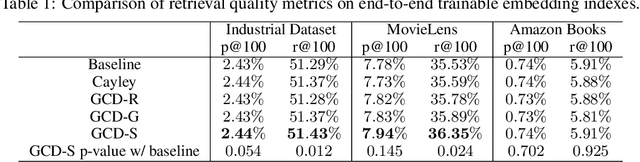
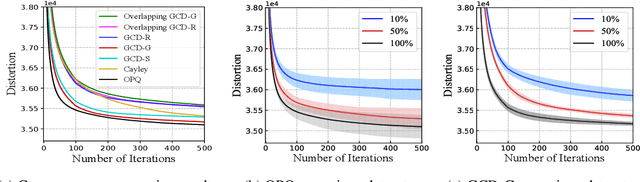
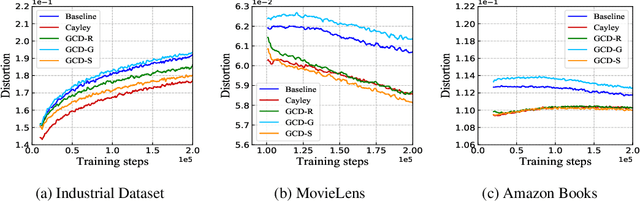
Product quantization (PQ) coupled with a space rotation, is widely used in modern approximate nearest neighbor (ANN) search systems to significantly compress the disk storage for embeddings and speed up the inner product computation. Existing rotation learning methods, however, minimize quantization distortion for fixed embeddings, which are not applicable to an end-to-end training scenario where embeddings are updated constantly. In this paper, based on geometric intuitions from Lie group theory, in particular the special orthogonal group $SO(n)$, we propose a family of block Givens coordinate descent algorithms to learn rotation matrix that are provably convergent on any convex objectives. Compared to the state-of-the-art SVD method, the Givens algorithms are much more parallelizable, reducing runtime by orders of magnitude on modern GPUs, and converge more stably according to experimental studies. They further improve upon vanilla product quantization significantly in an end-to-end training scenario.
* published in ICLR 2022
SearchGCN: Powering Embedding Retrieval by Graph Convolution Networks for E-Commerce Search
Jul 01, 2021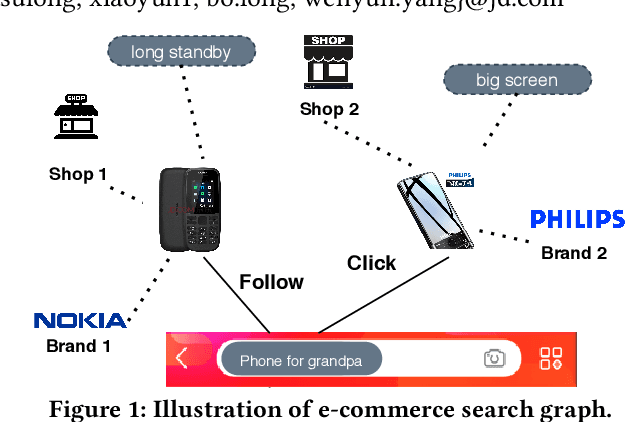
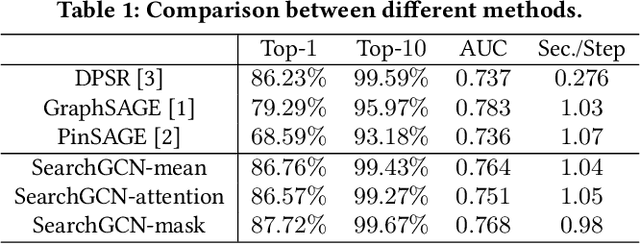
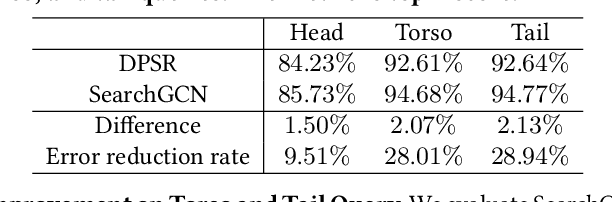
Graph convolution networks (GCN), which recently becomes new state-of-the-art method for graph node classification, recommendation and other applications, has not been successfully applied to industrial-scale search engine yet. In this proposal, we introduce our approach, namely SearchGCN, for embedding-based candidate retrieval in one of the largest e-commerce search engine in the world. Empirical studies demonstrate that SearchGCN learns better embedding representations than existing methods, especially for long tail queries and items. Thus, SearchGCN has been deployed into JD.com's search production since July 2020.
Joint Learning of Deep Retrieval Model and Product Quantization based Embedding Index
May 28, 2021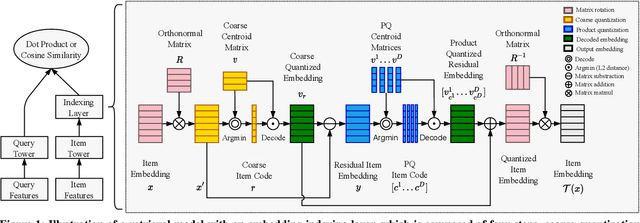
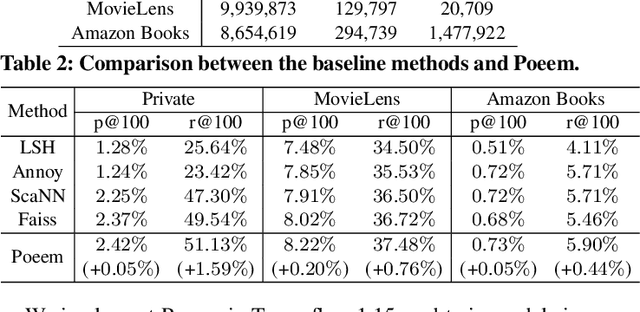
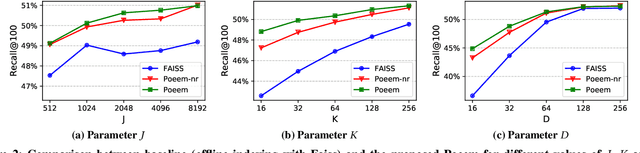
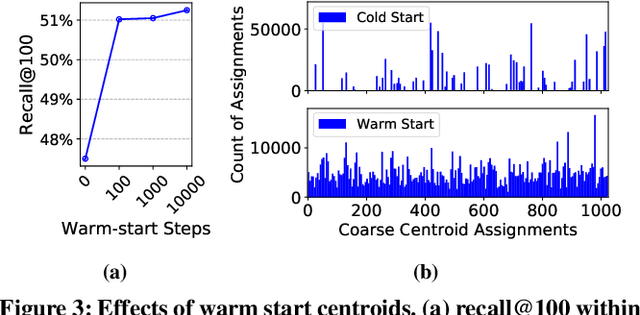
Embedding index that enables fast approximate nearest neighbor(ANN) search, serves as an indispensable component for state-of-the-art deep retrieval systems. Traditional approaches, often separating the two steps of embedding learning and index building, incur additional indexing time and decayed retrieval accuracy. In this paper, we propose a novel method called Poeem, which stands for product quantization based embedding index jointly trained with deep retrieval model, to unify the two separate steps within an end-to-end training, by utilizing a few techniques including the gradient straight-through estimator, warm start strategy, optimal space decomposition and Givens rotation. Extensive experimental results show that the proposed method not only improves retrieval accuracy significantly but also reduces the indexing time to almost none. We have open sourced our approach for the sake of comparison and reproducibility.
A unified Neural Network Approach to E-CommerceRelevance Learning
Apr 26, 2021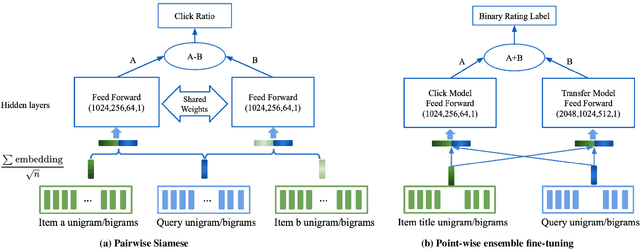



Result relevance scoring is critical to e-commerce search user experience. Traditional information retrieval methods focus on keyword matching and hand-crafted or counting-based numeric features, with limited understanding of item semantic relevance. We describe a highly-scalable feed-forward neural model to provide relevance score for (query, item) pairs, using only user query and item title as features, and both user click feedback as well as limited human ratings as labels. Several general enhancements were applied to further optimize eval/test metrics, including Siamese pairwise architecture, random batch negative co-training, and point-wise fine-tuning. We found significant improvement over GBDT baseline as well as several off-the-shelf deep-learning baselines on an independently constructed ratings dataset. The GBDT model relies on 10 times more features. We also present metrics for select subset combinations of techniques mentioned above.
* 6 pages
Query Rewriting via Cycle-Consistent Translation for E-Commerce Search
Mar 01, 2021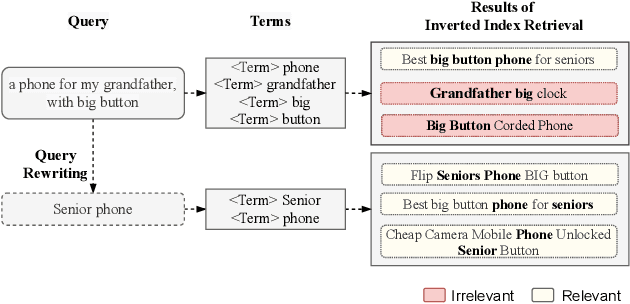
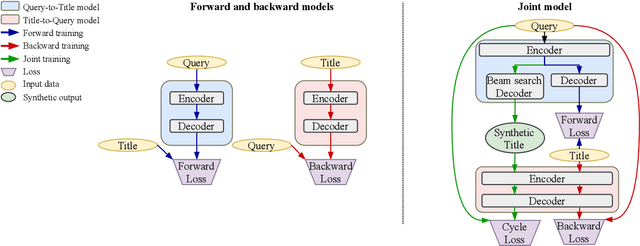

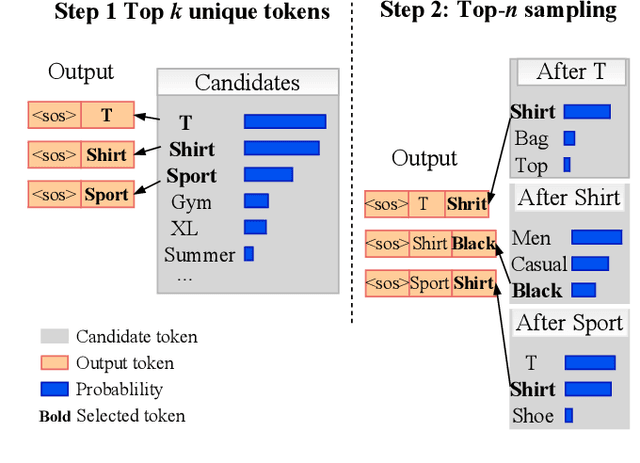
Nowadays e-commerce search has become an integral part of many people's shopping routines. One critical challenge in today's e-commerce search is the semantic matching problem where the relevant items may not contain the exact terms in the user query. In this paper, we propose a novel deep neural network based approach to query rewriting, in order to tackle this problem. Specifically, we formulate query rewriting into a cyclic machine translation problem to leverage abundant click log data. Then we introduce a novel cyclic consistent training algorithm in conjunction with state-of-the-art machine translation models to achieve the optimal performance in terms of query rewriting accuracy. In order to make it practical in industrial scenarios, we optimize the syntax tree construction to reduce computational cost and online serving latency. Offline experiments show that the proposed method is able to rewrite hard user queries into more standard queries that are more appropriate for the inverted index to retrieve. Comparing with human curated rule-based method, the proposed model significantly improves query rewriting diversity while maintaining good relevancy. Online A/B experiments show that it improves core e-commerce business metrics significantly. Since the summer of 2020, the proposed model has been launched into our search engine production, serving hundreds of millions of users.
Fine-tune BERT for E-commerce Non-Default Search Ranking
Aug 21, 2020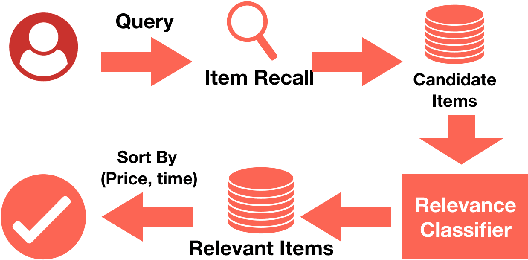
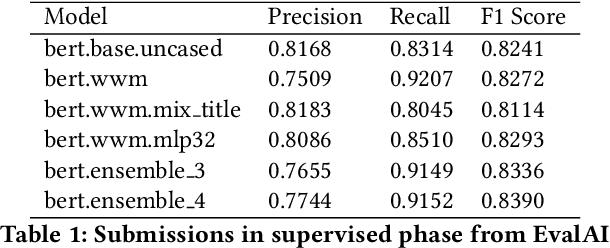
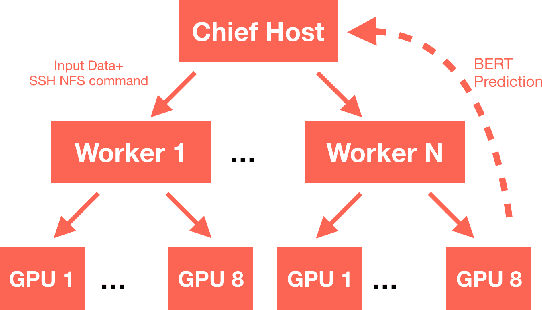
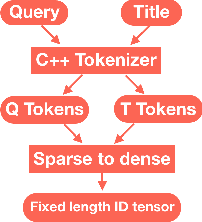
The quality of non-default ranking on e-commerce platforms, such as based on ascending item price or descending historical sales volume, often suffers from acute relevance problems, since the irrelevant items are much easier to be exposed at the top of the ranking results. In this work, we propose a two-stage ranking scheme, which first recalls wide range of candidate items through refined query/title keyword matching, and then classifies the recalled items using BERT-Large fine-tuned on human label data. We also implemented parallel prediction on multiple GPU hosts and a C++ tokenization custom op of Tensorflow. In this data challenge, our model won the 1st place in the supervised phase (based on overall F1 score) and 2nd place in the final phase (based on average per query F1 score).