 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniFormer: Efficient and Unified Model-Centric Scaling for Industrial Recommendation
Jun 25, 2026Recently, substantial progress has been made in industrial recommendation through component-centric model scaling, where individual components such as behavior modeling, feature interaction, or task modeling are independently scaled to improve model capacity. Although recent methods such as HyFormer and OneTrans further explore cross-module co-scaling by jointly modeling behavior and interaction, their designs are still confined to the feature space and lack a unified model-centric scaling framework over the overall modeling space. In this paper, we propose UniFormer, an efficient and unified model-centric scaling framework for industrial recommender systems. To improve efficiency, UniFormer decomposes the overall modeling space into feature and task spaces, which are modeled by stacked Feature-space Interaction Modules and Task-space Interaction Modules, respectively. Moreover, UniFormer introduces semantic-based tokenization scheme to enable user-item decoupling, thereby achieving request-level inference acceleration. To prevent preference collapse, UniFormer employs multi-sequence cross-attention to separately capture heterogeneous behavior patterns, followed by the self-attention to enhance interaction modeling. Besides, dedicated multi-view FFNs are introduced to support flexible and scalable parameter scaling across different modeling components. Extensive online A/B testing in two production scenarios, Kuaishou and Kuaishou Lite, shows that UniFormer consistently improves user engagement and interaction metrics, achieving gains of +0.101%/+0.260% in App Stay Time and +0.729%/+1.113% in Watch Time, respectively.
AgentX: Towards Agent-Driven Self-Iteration of Industrial Recommender Systems
Jun 25, 2026Recommendation algorithm iteration is moving from an artisanal, engineer-bound process toward an industrialized research loop, but this transition remains blocked by a structural execution bottleneck: the idea-to-launch cycle still depends on human engineers to generate hypotheses, modify production code, launch A/B experiments, and attribute online results. Innovation therefore scales linearly with headcount rather than compounding with evidence, compute, and accumulated experimental knowledge. We present AgentX, a production-deployed multi-agent system that fundamentally restructures this production function. AgentX operates as a self-evolving development engine: it autonomously generates, implements, evaluates, and learns from recommendation experiments at a scale and pace that no manual workflow can sustain. The system orchestrates four tightly coupled stages in a closed loop. A Brainstorm Agent synthesizes evidence from historical experiments, system architecture, data analysis, and external research into ranked, executable proposals. A Developing Agent translates each proposal into production-ready code through repository-grounded generation and multi-dimensional reliability verification. An Evaluation Agent conducts safe online rollout with guardrail-vetoed A/B judgment, converting both successes and failures into structured knowledge assets. A Harness Evolution layer (SGPO) then distills execution trajectories into semantic-gradient updates that continuously sharpen the agents themselves -- making the system not merely automated, but self-improving.
OneReason Technical Report
Jun 04, 2026Generative recommendation models in the OneRec family have been widely deployed in many real-world services, such as short-video, live-streaming, advertising, and e-commerce. However, these generative models can only benefit from the scaling advantage, while their reasoning ability is hard to activate, since we cannot construct meaningful Chain-of-Thought (CoT) sequences consisting of itemic tokens only. Inspired by the success of the reasoning-style ``think before answer'' paradigm in the LLM field, we conduct preliminary studies (i.e., OneRec-Think, OpenOneRec) to explore reasoning capability in generative recommendation. Nevertheless, we notice an unexpected phenomenon: the thinking mode does not show advantages over the non-thinking mode. Drawing insights from recent findings on CoT robustness in multi-modal language models, we argue that effective reasoning in recommendation rests on two factors: perception, the ability to ground itemic tokens in their underlying language semantics, and cognition, the ability to reorganize a user's behavior sequence into coherent latent interest points. We therefore propose OneReason, which includes: (1) strong itemic token perception in pre-training, (2) a three-level cognition-enhanced CoT format for recommendation tasks in SFT, and (3) a specialize-then-unify training recipe in RL to enhance the thinking ability.
Action-Aware Generative Sequence Modeling for Short Video Recommendation
Apr 28, 2026With the rapid development of the Internet, users have increasingly higher expectations for the recommendation accuracy of online content consumption platforms. However, short videos often contain diverse segments, and users may not hold the same attitude toward all of them. Traditional binary-classification recommendation models, which treat a video as a single holistic entity, face limitations in accurately capturing such nuanced preferences. Considering that user consumption is a temporal process, this paper demonstrates that the timing of user actions can represent diverse intentions through statistical analysis and examination of action patterns. Based on this insight, we propose a novel modeling paradigm: Action-Aware Generative Sequence Network (A2Gen), which refines user actions along the temporal dimension and chains them into sequences for unified processing and prediction. First, we introduce the Context-aware Attention Module (CAM) to model action sequences enriched with item-specific contextual features. Building upon this, we develop the Hierarchical Sequence Encoder (HSE) to learn temporal action patterns from users' historical actions. Finally, through leveraging CAM, we design a module for action sequence generation: the Action-seq Autoregressive Generator (AAG). Extensive offline experiments on the Kuaishou's dataset and the Tmall public dataset demonstrate the superiority of our proposed model. Furthermore, through large-scale online A/B testing deployed on Kuaishou's platform, our model achieves significant improvements over baseline methods in multi-task prediction by leveraging sequential information. Specifically, it yields increases of 0.34% in user watch time, 8.1% in interaction rate, and 0.162% in overall user retention (LifeTime-7), leading to successful deployment across all traffic, serving over 400 million users every day.
SMES: Towards Scalable Multi-Task Recommendation via Expert Sparsity
Feb 10, 2026Industrial recommender systems typically rely on multi-task learning to estimate diverse user feedback signals and aggregate them for ranking. Recent advances in model scaling have shown promising gains in recommendation. However, naively increasing model capacity imposes prohibitive online inference costs and often yields diminishing returns for sparse tasks with skewed label distributions. This mismatch between uniform parameter scaling and heterogeneous task capacity demands poses a fundamental challenge for scalable multi-task recommendation. In this work, we investigate parameter sparsification as a principled scaling paradigm and identify two critical obstacles when applying sparse Mixture-of-Experts (MoE) to multi-task recommendation: exploded expert activation that undermines instance-level sparsity and expert load skew caused by independent task-wise routing. To address these challenges, we propose SMES, a scalable sparse MoE framework with progressive expert routing. SMES decomposes expert activation into a task-shared expert subset jointly selected across tasks and task-adaptive private experts, explicitly bounding per-instance expert execution while preserving task-specific capacity. In addition, SMES introduces a global multi-gate load-balancing regularizer that stabilizes training by regulating aggregated expert utilization across all tasks. SMES has been deployed in Kuaishou large-scale short-video services, supporting over 400 million daily active users. Extensive online experiments demonstrate stable improvements, with GAUC gain of 0.29% and a 0.31% uplift in user watch time.
OpenOneRec Technical Report
Dec 31, 2025While the OneRec series has successfully unified the fragmented recommendation pipeline into an end-to-end generative framework, a significant gap remains between recommendation systems and general intelligence. Constrained by isolated data, they operate as domain specialists-proficient in pattern matching but lacking world knowledge, reasoning capabilities, and instruction following. This limitation is further compounded by the lack of a holistic benchmark to evaluate such integrated capabilities. To address this, our contributions are: 1) RecIF Bench & Open Data: We propose RecIF-Bench, a holistic benchmark covering 8 diverse tasks that thoroughly evaluate capabilities from fundamental prediction to complex reasoning. Concurrently, we release a massive training dataset comprising 96 million interactions from 160,000 users to facilitate reproducible research. 2) Framework & Scaling: To ensure full reproducibility, we open-source our comprehensive training pipeline, encompassing data processing, co-pretraining, and post-training. Leveraging this framework, we demonstrate that recommendation capabilities can scale predictably while mitigating catastrophic forgetting of general knowledge. 3) OneRec-Foundation: We release OneRec Foundation (1.7B and 8B), a family of models establishing new state-of-the-art (SOTA) results across all tasks in RecIF-Bench. Furthermore, when transferred to the Amazon benchmark, our models surpass the strongest baselines with an average 26.8% improvement in Recall@10 across 10 diverse datasets (Figure 1). This work marks a step towards building truly intelligent recommender systems. Nonetheless, realizing this vision presents significant technical and theoretical challenges, highlighting the need for broader research engagement in this promising direction.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
OneRec Technical Report
Jun 16, 2025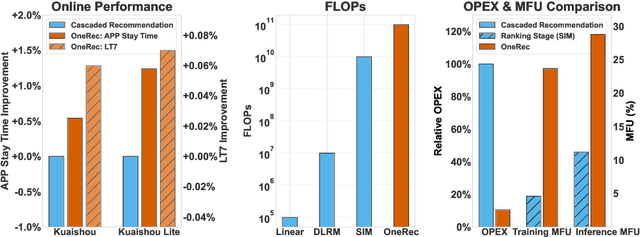

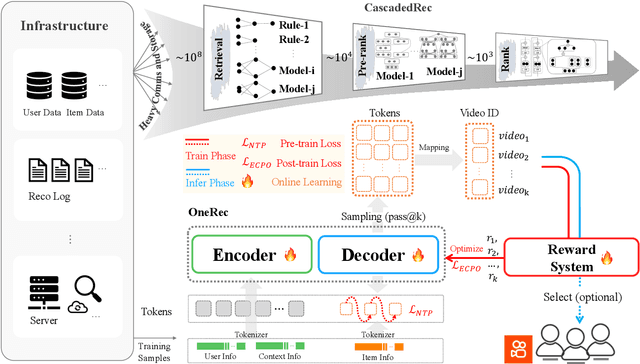

Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Attention Weighted Mixture of Experts with Contrastive Learning for Personalized Ranking in E-commerce
Jun 08, 2023



Ranking model plays an essential role in e-commerce search and recommendation. An effective ranking model should give a personalized ranking list for each user according to the user preference. Existing algorithms usually extract a user representation vector from the user behavior sequence, then feed the vector into a feed-forward network (FFN) together with other features for feature interactions, and finally produce a personalized ranking score. Despite tremendous progress in the past, there is still room for improvement. Firstly, the personalized patterns of feature interactions for different users are not explicitly modeled. Secondly, most of existing algorithms have poor personalized ranking results for long-tail users with few historical behaviors due to the data sparsity. To overcome the two challenges, we propose Attention Weighted Mixture of Experts (AW-MoE) with contrastive learning for personalized ranking. Firstly, AW-MoE leverages the MoE framework to capture personalized feature interactions for different users. To model the user preference, the user behavior sequence is simultaneously fed into expert networks and the gate network. Within the gate network, one gate unit and one activation unit are designed to adaptively learn the fine-grained activation vector for experts using an attention mechanism. Secondly, a random masking strategy is applied to the user behavior sequence to simulate long-tail users, and an auxiliary contrastive loss is imposed to the output of the gate network to improve the model generalization for these users. This is validated by a higher performance gain on the long-tail user test set. Experiment results on a JD real production dataset and a public dataset demonstrate the effectiveness of AW-MoE, which significantly outperforms state-of-art methods. Notably, AW-MoE has been successfully deployed in the JD e-commerce search engine, ...
A unified Neural Network Approach to E-CommerceRelevance Learning
Apr 26, 2021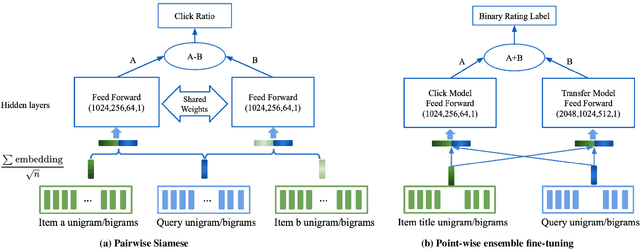



Result relevance scoring is critical to e-commerce search user experience. Traditional information retrieval methods focus on keyword matching and hand-crafted or counting-based numeric features, with limited understanding of item semantic relevance. We describe a highly-scalable feed-forward neural model to provide relevance score for (query, item) pairs, using only user query and item title as features, and both user click feedback as well as limited human ratings as labels. Several general enhancements were applied to further optimize eval/test metrics, including Siamese pairwise architecture, random batch negative co-training, and point-wise fine-tuning. We found significant improvement over GBDT baseline as well as several off-the-shelf deep-learning baselines on an independently constructed ratings dataset. The GBDT model relies on 10 times more features. We also present metrics for select subset combinations of techniques mentioned above.
* 6 pages