 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMODRL-TA:A Multi-Objective Deep Reinforcement Learning Framework for Traffic Allocation in E-Commerce Search
Jul 22, 2024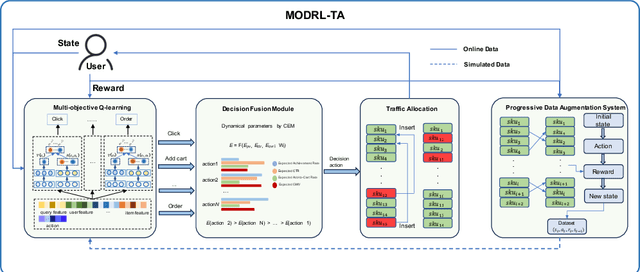
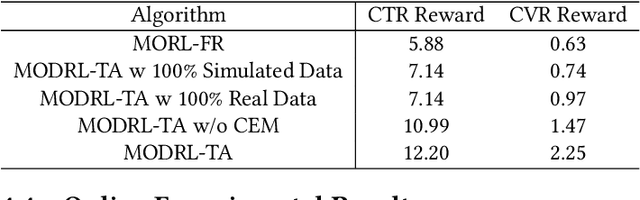
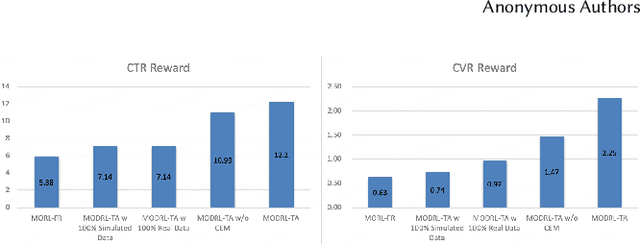
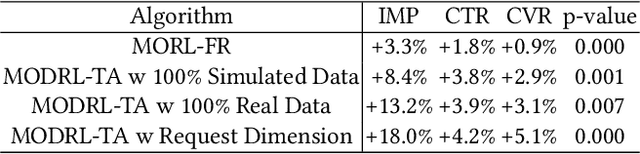
Traffic allocation is a process of redistributing natural traffic to products by adjusting their positions in the post-search phase, aimed at effectively fostering merchant growth, precisely meeting customer demands, and ensuring the maximization of interests across various parties within e-commerce platforms. Existing methods based on learning to rank neglect the long-term value of traffic allocation, whereas approaches of reinforcement learning suffer from balancing multiple objectives and the difficulties of cold starts within realworld data environments. To address the aforementioned issues, this paper propose a multi-objective deep reinforcement learning framework consisting of multi-objective Q-learning (MOQ), a decision fusion algorithm (DFM) based on the cross-entropy method(CEM), and a progressive data augmentation system(PDA). Specifically. MOQ constructs ensemble RL models, each dedicated to an objective, such as click-through rate, conversion rate, etc. These models individually determine the position of items as actions, aiming to estimate the long-term value of multiple objectives from an individual perspective. Then we employ DFM to dynamically adjust weights among objectives to maximize long-term value, addressing temporal dynamics in objective preferences in e-commerce scenarios. Initially, PDA trained MOQ with simulated data from offline logs. As experiments progressed, it strategically integrated real user interaction data, ultimately replacing the simulated dataset to alleviate distributional shifts and the cold start problem. Experimental results on real-world online e-commerce systems demonstrate the significant improvements of MODRL-TA, and we have successfully deployed MODRL-TA on an e-commerce search platform.
Attention Weighted Mixture of Experts with Contrastive Learning for Personalized Ranking in E-commerce
Jun 08, 2023



Ranking model plays an essential role in e-commerce search and recommendation. An effective ranking model should give a personalized ranking list for each user according to the user preference. Existing algorithms usually extract a user representation vector from the user behavior sequence, then feed the vector into a feed-forward network (FFN) together with other features for feature interactions, and finally produce a personalized ranking score. Despite tremendous progress in the past, there is still room for improvement. Firstly, the personalized patterns of feature interactions for different users are not explicitly modeled. Secondly, most of existing algorithms have poor personalized ranking results for long-tail users with few historical behaviors due to the data sparsity. To overcome the two challenges, we propose Attention Weighted Mixture of Experts (AW-MoE) with contrastive learning for personalized ranking. Firstly, AW-MoE leverages the MoE framework to capture personalized feature interactions for different users. To model the user preference, the user behavior sequence is simultaneously fed into expert networks and the gate network. Within the gate network, one gate unit and one activation unit are designed to adaptively learn the fine-grained activation vector for experts using an attention mechanism. Secondly, a random masking strategy is applied to the user behavior sequence to simulate long-tail users, and an auxiliary contrastive loss is imposed to the output of the gate network to improve the model generalization for these users. This is validated by a higher performance gain on the long-tail user test set. Experiment results on a JD real production dataset and a public dataset demonstrate the effectiveness of AW-MoE, which significantly outperforms state-of-art methods. Notably, AW-MoE has been successfully deployed in the JD e-commerce search engine, ...
Adversarial Mixture Of Experts with Category Hierarchy Soft Constraint
Jul 27, 2020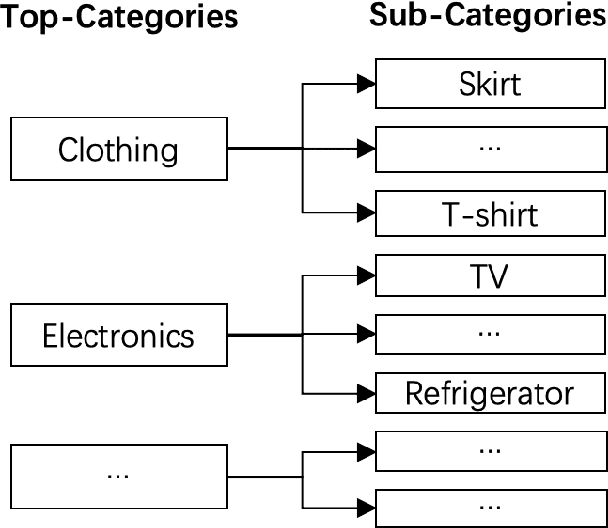
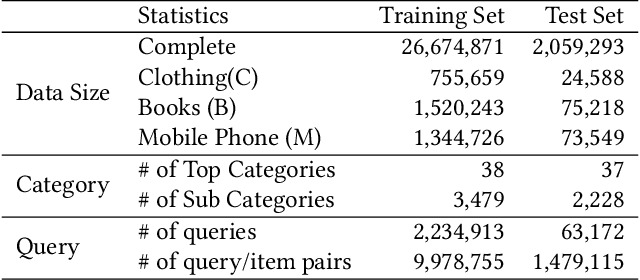
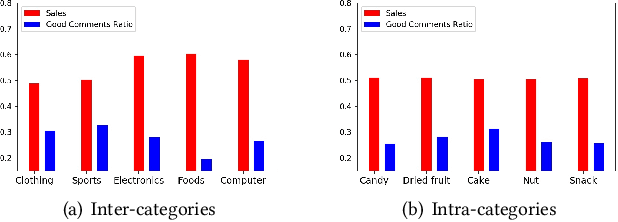
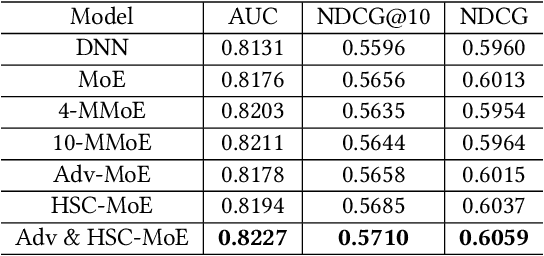
Product search is the most common way for people to satisfy their shopping needs on e-commerce websites. Products are typically annotated with one of several broad categorical tags, such as "Clothing" or "Electronics", as well as finer-grained categories like "Refrigerator" or "TV", both under "Electronics". These tags are used to construct a hierarchy of query categories. Feature distributions such as price and brand popularity vary wildly across query categories. In addition, feature importance for the purpose of CTR/CVR predictions differs from one category to another. In this work, we leverage the Mixture of Expert (MoE) framework to learn a ranking model that specializes for each query category. In particular, our gate network relies solely on the category ids extracted from the user query. While classical MoE's pick expert towers spontaneously for each input example, we explore two techniques to establish more explicit and transparent connections between the experts and query categories. To help differentiate experts on their domain specialties, we introduce a form of adversarial regularization among the expert outputs, forcing them to disagree with one another. As a result, they tend to approach each prediction problem from different angles, rather than copying one another. This is validated by a much stronger clustering effect of the gate output vectors under different categories. In addition, soft gating constraints based on the categorical hierarchy are imposed to help similar products choose similar gate values. and make them more likely to share similar experts. This allows aggregation of training data among smaller sibling categories to overcome data scarcity issues among the latter. Experiments on a learning-to-rank dataset gathered from a leading e-commerce search log demonstrate that MoE with our improvements consistently outperforms competing models.