 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Retrieval Augmentation via Generative Language Modeling for E-commerce Query Intent Classification
Aug 21, 2023Retrieval augmentation, which enhances downstream models by a knowledge retriever and an external corpus instead of by merely increasing the number of model parameters, has been successfully applied to many natural language processing (NLP) tasks such as text classification, question answering and so on. However, existing methods that separately or asynchronously train the retriever and downstream model mainly due to the non-differentiability between the two parts, usually lead to degraded performance compared to end-to-end joint training. In this paper, we propose Differentiable Retrieval Augmentation via Generative lANguage modeling(Dragan), to address this problem by a novel differentiable reformulation. We demonstrate the effectiveness of our proposed method on a challenging NLP task in e-commerce search, namely query intent classification. Both the experimental results and ablation study show that the proposed method significantly and reasonably improves the state-of-the-art baselines on both offline evaluation and online A/B test.
Attention Weighted Mixture of Experts with Contrastive Learning for Personalized Ranking in E-commerce
Jun 08, 2023



Ranking model plays an essential role in e-commerce search and recommendation. An effective ranking model should give a personalized ranking list for each user according to the user preference. Existing algorithms usually extract a user representation vector from the user behavior sequence, then feed the vector into a feed-forward network (FFN) together with other features for feature interactions, and finally produce a personalized ranking score. Despite tremendous progress in the past, there is still room for improvement. Firstly, the personalized patterns of feature interactions for different users are not explicitly modeled. Secondly, most of existing algorithms have poor personalized ranking results for long-tail users with few historical behaviors due to the data sparsity. To overcome the two challenges, we propose Attention Weighted Mixture of Experts (AW-MoE) with contrastive learning for personalized ranking. Firstly, AW-MoE leverages the MoE framework to capture personalized feature interactions for different users. To model the user preference, the user behavior sequence is simultaneously fed into expert networks and the gate network. Within the gate network, one gate unit and one activation unit are designed to adaptively learn the fine-grained activation vector for experts using an attention mechanism. Secondly, a random masking strategy is applied to the user behavior sequence to simulate long-tail users, and an auxiliary contrastive loss is imposed to the output of the gate network to improve the model generalization for these users. This is validated by a higher performance gain on the long-tail user test set. Experiment results on a JD real production dataset and a public dataset demonstrate the effectiveness of AW-MoE, which significantly outperforms state-of-art methods. Notably, AW-MoE has been successfully deployed in the JD e-commerce search engine, ...
Givens Coordinate Descent Methods for Rotation Matrix Learning in Trainable Embedding Indexes
Mar 09, 2022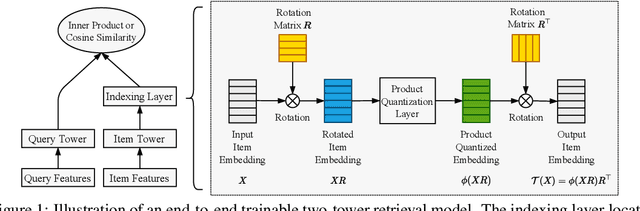
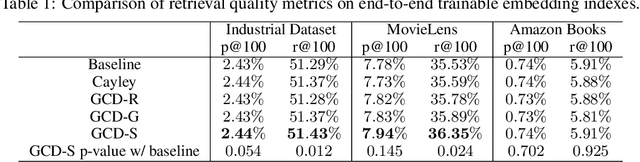
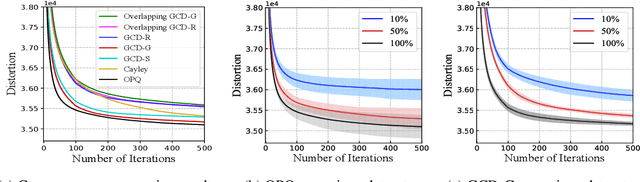
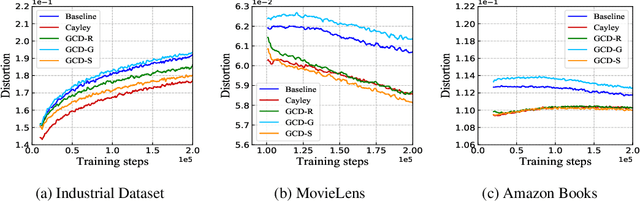
Product quantization (PQ) coupled with a space rotation, is widely used in modern approximate nearest neighbor (ANN) search systems to significantly compress the disk storage for embeddings and speed up the inner product computation. Existing rotation learning methods, however, minimize quantization distortion for fixed embeddings, which are not applicable to an end-to-end training scenario where embeddings are updated constantly. In this paper, based on geometric intuitions from Lie group theory, in particular the special orthogonal group $SO(n)$, we propose a family of block Givens coordinate descent algorithms to learn rotation matrix that are provably convergent on any convex objectives. Compared to the state-of-the-art SVD method, the Givens algorithms are much more parallelizable, reducing runtime by orders of magnitude on modern GPUs, and converge more stably according to experimental studies. They further improve upon vanilla product quantization significantly in an end-to-end training scenario.
* published in ICLR 2022
Sequential Search with Off-Policy Reinforcement Learning
Feb 01, 2022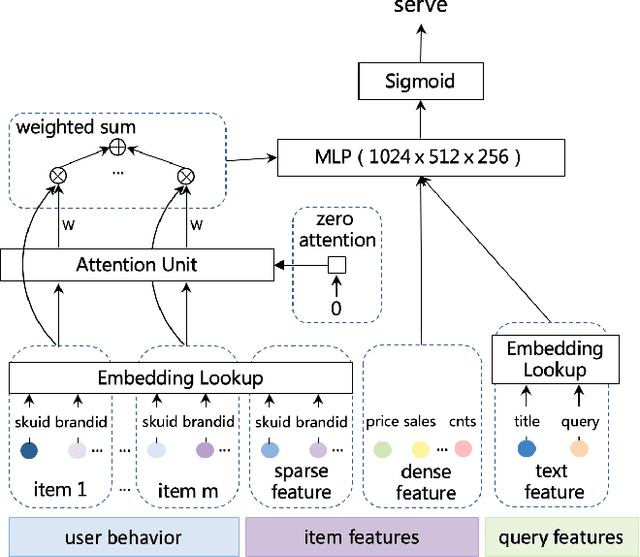
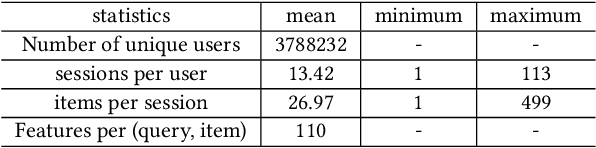
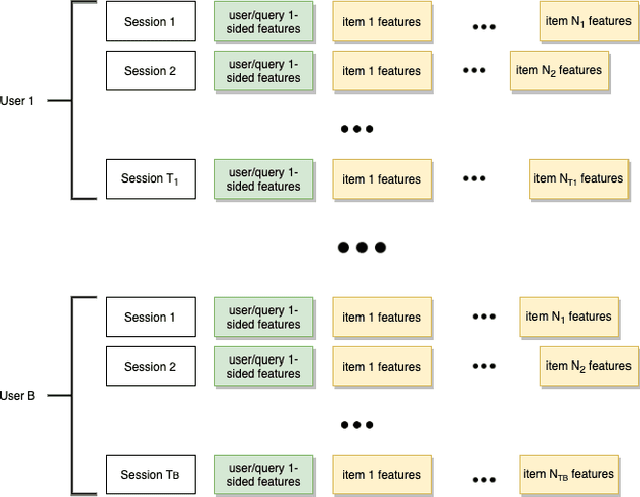
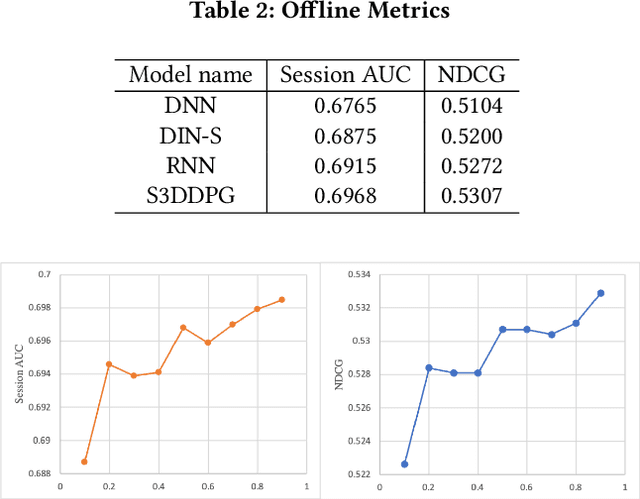
Recent years have seen a significant amount of interests in Sequential Recommendation (SR), which aims to understand and model the sequential user behaviors and the interactions between users and items over time. Surprisingly, despite the huge success Sequential Recommendation has achieved, there is little study on Sequential Search (SS), a twin learning task that takes into account a user's current and past search queries, in addition to behavior on historical query sessions. The SS learning task is even more important than the counterpart SR task for most of E-commence companies due to its much larger online serving demands as well as traffic volume. To this end, we propose a highly scalable hybrid learning model that consists of an RNN learning framework leveraging all features in short-term user-item interactions, and an attention model utilizing selected item-only features from long-term interactions. As a novel optimization step, we fit multiple short user sequences in a single RNN pass within a training batch, by solving a greedy knapsack problem on the fly. Moreover, we explore the use of off-policy reinforcement learning in multi-session personalized search ranking. Specifically, we design a pairwise Deep Deterministic Policy Gradient model that efficiently captures users' long term reward in terms of pairwise classification error. Extensive ablation experiments demonstrate significant improvement each component brings to its state-of-the-art baseline, on a variety of offline and online metrics.
DSGPT: Domain-Specific Generative Pre-Training of Transformers for Text Generation in E-commerce Title and Review Summarization
Dec 15, 2021
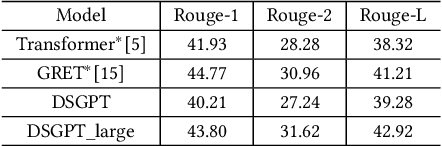
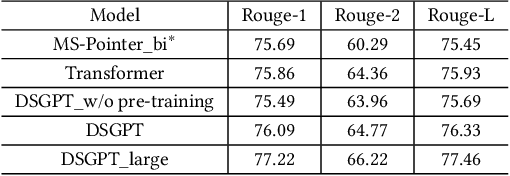
We propose a novel domain-specific generative pre-training (DS-GPT) method for text generation and apply it to the product titleand review summarization problems on E-commerce mobile display.First, we adopt a decoder-only transformer architecture, which fitswell for fine-tuning tasks by combining input and output all to-gether. Second, we demonstrate utilizing only small amount of pre-training data in related domains is powerful. Pre-training a languagemodel from a general corpus such as Wikipedia or the CommonCrawl requires tremendous time and resource commitment, andcan be wasteful if the downstream tasks are limited in variety. OurDSGPT is pre-trained on a limited dataset, the Chinese short textsummarization dataset (LCSTS). Third, our model does not requireproduct-related human-labeled data. For title summarization task,the state of art explicitly uses additional background knowledgein training and predicting stages. In contrast, our model implic-itly captures this knowledge and achieves significant improvementover other methods, after fine-tuning on the public Taobao.comdataset. For review summarization task, we utilize JD.com in-housedataset, and observe similar improvement over standard machinetranslation methods which lack the flexibility of fine-tuning. Ourproposed work can be simply extended to other domains for a widerange of text generation tasks.
Joint Learning of Deep Retrieval Model and Product Quantization based Embedding Index
May 28, 2021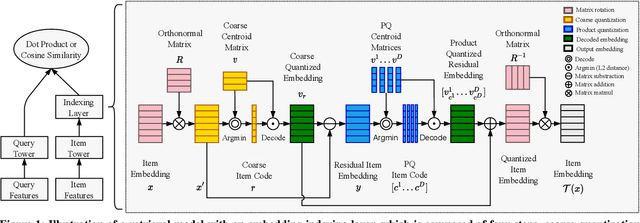
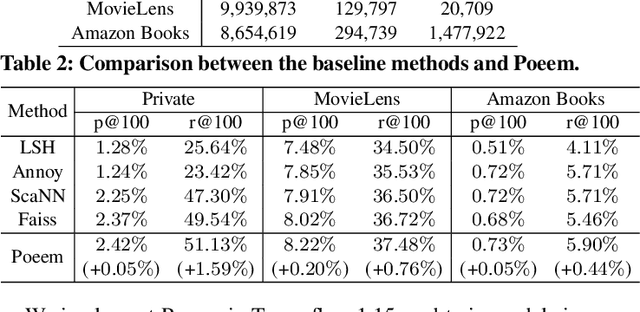
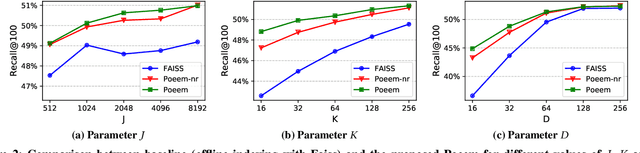
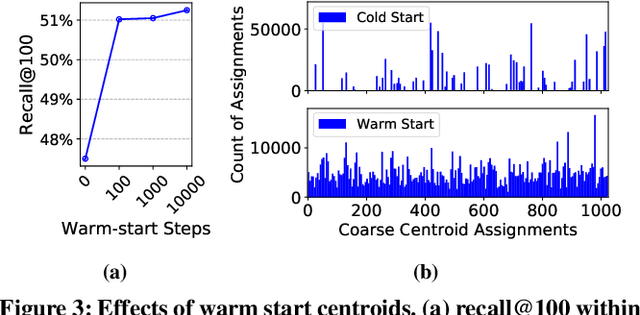
Embedding index that enables fast approximate nearest neighbor(ANN) search, serves as an indispensable component for state-of-the-art deep retrieval systems. Traditional approaches, often separating the two steps of embedding learning and index building, incur additional indexing time and decayed retrieval accuracy. In this paper, we propose a novel method called Poeem, which stands for product quantization based embedding index jointly trained with deep retrieval model, to unify the two separate steps within an end-to-end training, by utilizing a few techniques including the gradient straight-through estimator, warm start strategy, optimal space decomposition and Givens rotation. Extensive experimental results show that the proposed method not only improves retrieval accuracy significantly but also reduces the indexing time to almost none. We have open sourced our approach for the sake of comparison and reproducibility.
A unified Neural Network Approach to E-CommerceRelevance Learning
Apr 26, 2021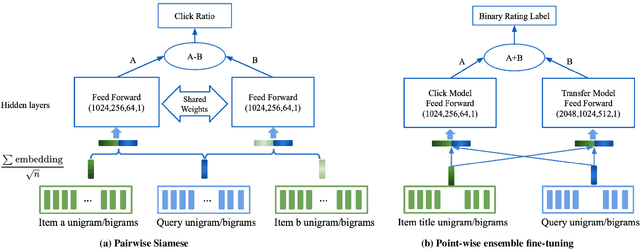



Result relevance scoring is critical to e-commerce search user experience. Traditional information retrieval methods focus on keyword matching and hand-crafted or counting-based numeric features, with limited understanding of item semantic relevance. We describe a highly-scalable feed-forward neural model to provide relevance score for (query, item) pairs, using only user query and item title as features, and both user click feedback as well as limited human ratings as labels. Several general enhancements were applied to further optimize eval/test metrics, including Siamese pairwise architecture, random batch negative co-training, and point-wise fine-tuning. We found significant improvement over GBDT baseline as well as several off-the-shelf deep-learning baselines on an independently constructed ratings dataset. The GBDT model relies on 10 times more features. We also present metrics for select subset combinations of techniques mentioned above.
* 6 pages
From Semantic Retrieval to Pairwise Ranking: Applying Deep Learning in E-commerce Search
Mar 24, 2021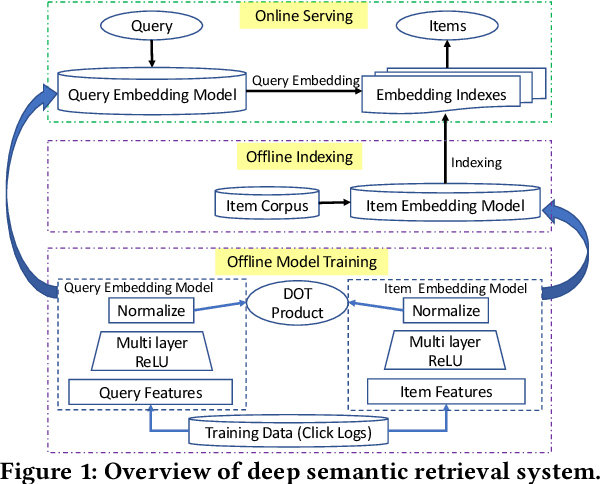

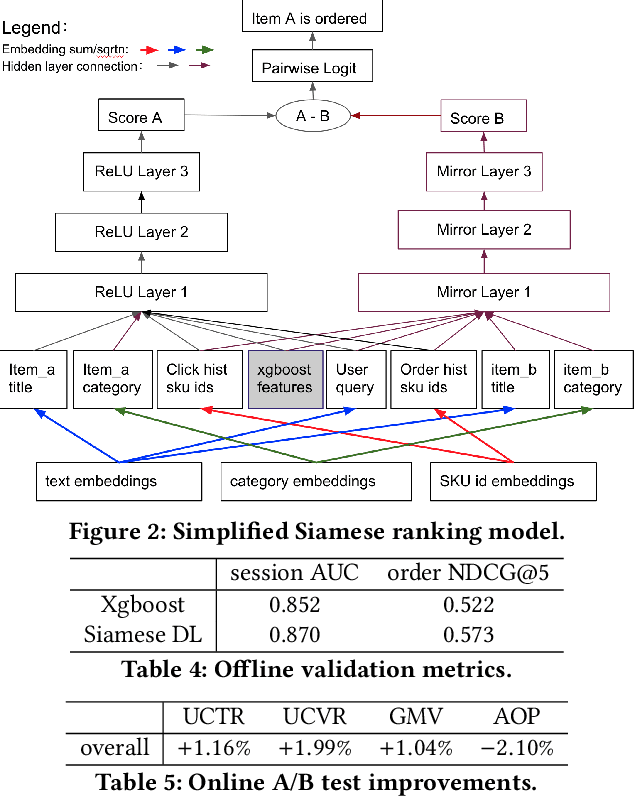
We introduce deep learning models to the two most important stages in product search at JD.com, one of the largest e-commerce platforms in the world. Specifically, we outline the design of a deep learning system that retrieves semantically relevant items to a query within milliseconds, and a pairwise deep re-ranking system, which learns subtle user preferences. Compared to traditional search systems, the proposed approaches are better at semantic retrieval and personalized ranking, achieving significant improvements.
Heterogeneous Network Embedding for Deep Semantic Relevance Match in E-commerce Search
Jan 13, 2021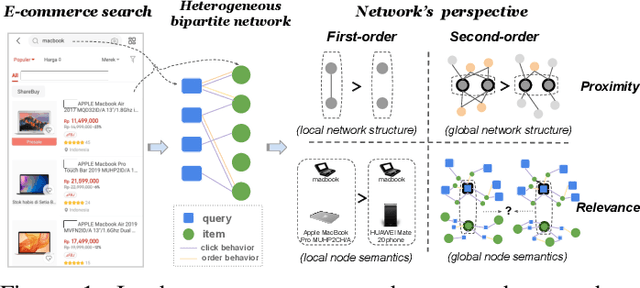
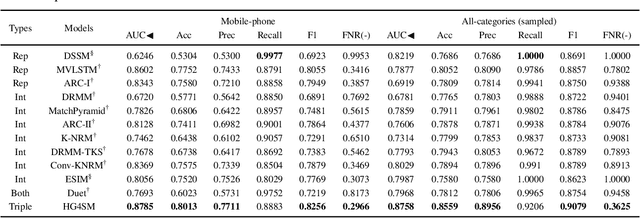
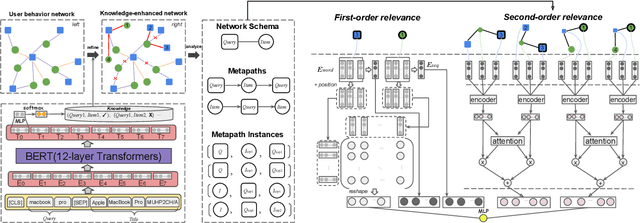
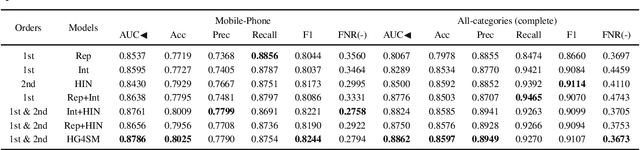
Result relevance prediction is an essential task of e-commerce search engines to boost the utility of search engines and ensure smooth user experience. The last few years eyewitnessed a flurry of research on the use of Transformer-style models and deep text-match models to improve relevance. However, these two types of models ignored the inherent bipartite network structures that are ubiquitous in e-commerce search logs, making these models ineffective. We propose in this paper a novel Second-order Relevance, which is fundamentally different from the previous First-order Relevance, to improve result relevance prediction. We design, for the first time, an end-to-end First-and-Second-order Relevance prediction model for e-commerce item relevance. The model is augmented by the neighborhood structures of bipartite networks that are built using the information of user behavioral feedback, including clicks and purchases. To ensure that edges accurately encode relevance information, we introduce external knowledge generated from BERT to refine the network of user behaviors. This allows the new model to integrate information from neighboring items and queries, which are highly relevant to the focus query-item pair under consideration. Results of offline experiments showed that the new model significantly improved the prediction accuracy in terms of human relevance judgment. An ablation study showed that the First-and-Second-order model gained a 4.3% average gain over the First-order model. Results of an online A/B test revealed that the new model derived more commercial benefits compared to the base model.
BERT2DNN: BERT Distillation with Massive Unlabeled Data for Online E-Commerce Search
Oct 20, 2020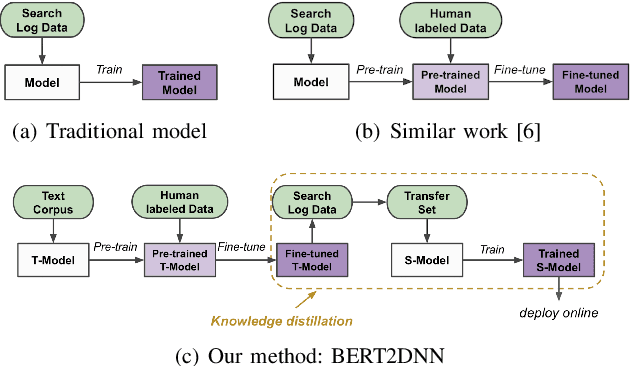

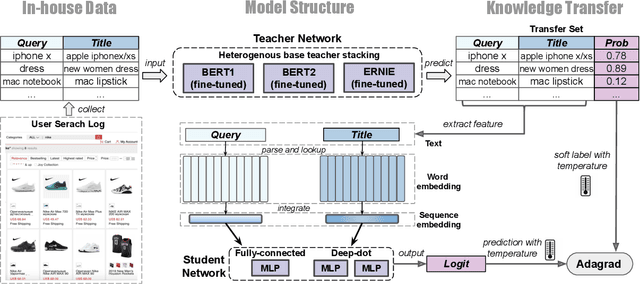
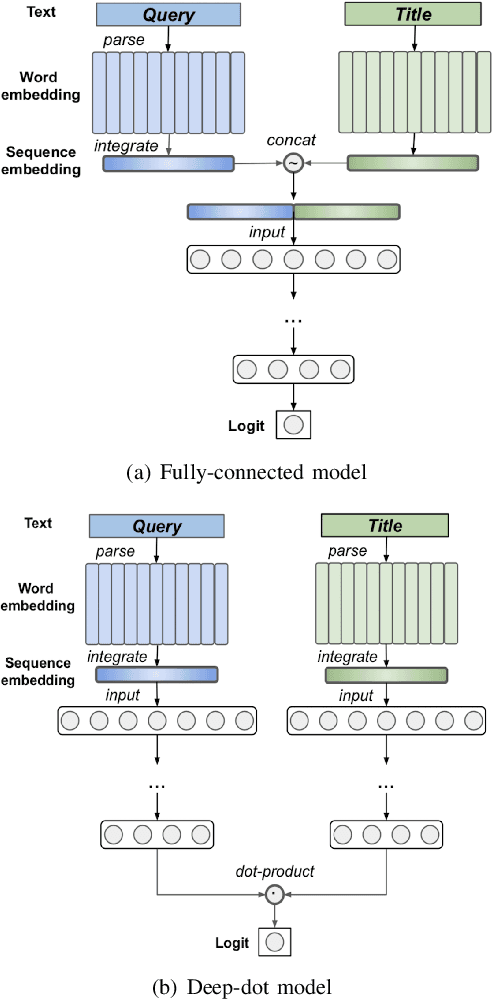
Relevance has significant impact on user experience and business profit for e-commerce search platform. In this work, we propose a data-driven framework for search relevance prediction, by distilling knowledge from BERT and related multi-layer Transformer teacher models into simple feed-forward networks with large amount of unlabeled data. The distillation process produces a student model that recovers more than 97\% test accuracy of teacher models on new queries, at a serving cost that's several magnitude lower (latency 150x lower than BERT-Base and 15x lower than the most efficient BERT variant, TinyBERT). The applications of temperature rescaling and teacher model stacking further boost model accuracy, without increasing the student model complexity. We present experimental results on both in-house e-commerce search relevance data as well as a public data set on sentiment analysis from the GLUE benchmark. The latter takes advantage of another related public data set of much larger scale, while disregarding its potentially noisy labels. Embedding analysis and case study on the in-house data further highlight the strength of the resulting model. By making the data processing and model training source code public, we hope the techniques presented here can help reduce energy consumption of the state of the art Transformer models and also level the playing field for small organizations lacking access to cutting edge machine learning hardwares.