 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Learning of Deep Retrieval Model and Product Quantization based Embedding Index
May 28, 2021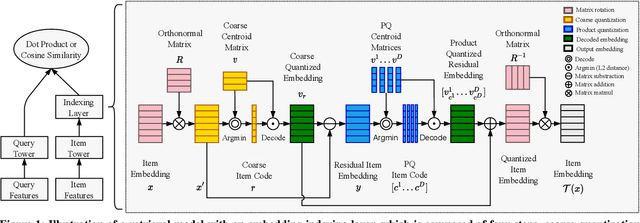
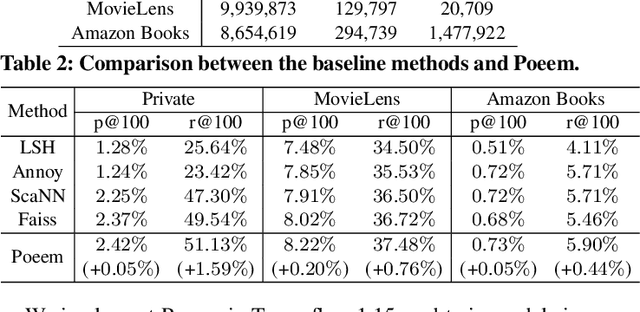
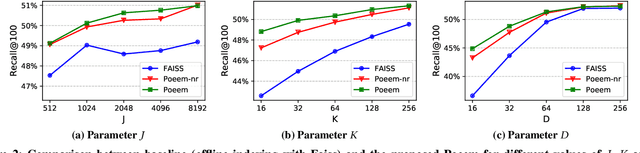
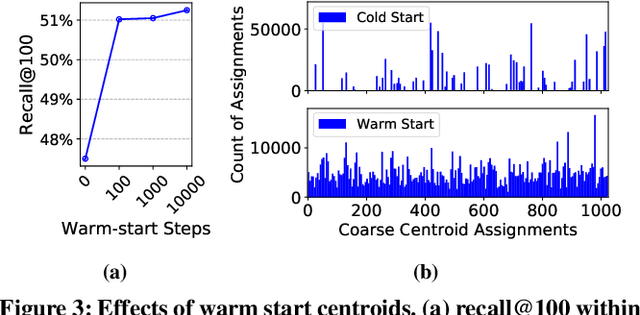
Embedding index that enables fast approximate nearest neighbor(ANN) search, serves as an indispensable component for state-of-the-art deep retrieval systems. Traditional approaches, often separating the two steps of embedding learning and index building, incur additional indexing time and decayed retrieval accuracy. In this paper, we propose a novel method called Poeem, which stands for product quantization based embedding index jointly trained with deep retrieval model, to unify the two separate steps within an end-to-end training, by utilizing a few techniques including the gradient straight-through estimator, warm start strategy, optimal space decomposition and Givens rotation. Extensive experimental results show that the proposed method not only improves retrieval accuracy significantly but also reduces the indexing time to almost none. We have open sourced our approach for the sake of comparison and reproducibility.
BERT2DNN: BERT Distillation with Massive Unlabeled Data for Online E-Commerce Search
Oct 20, 2020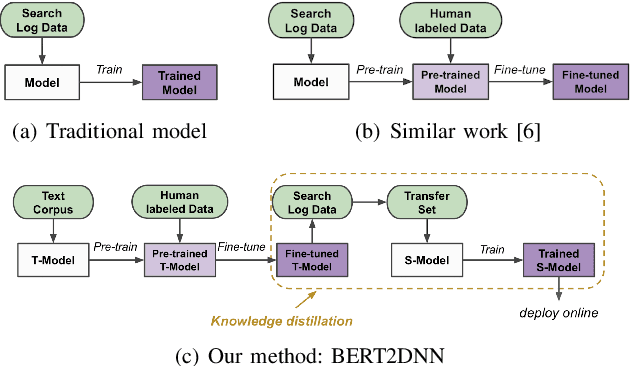

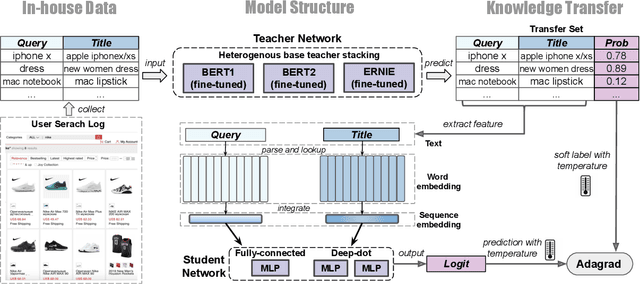
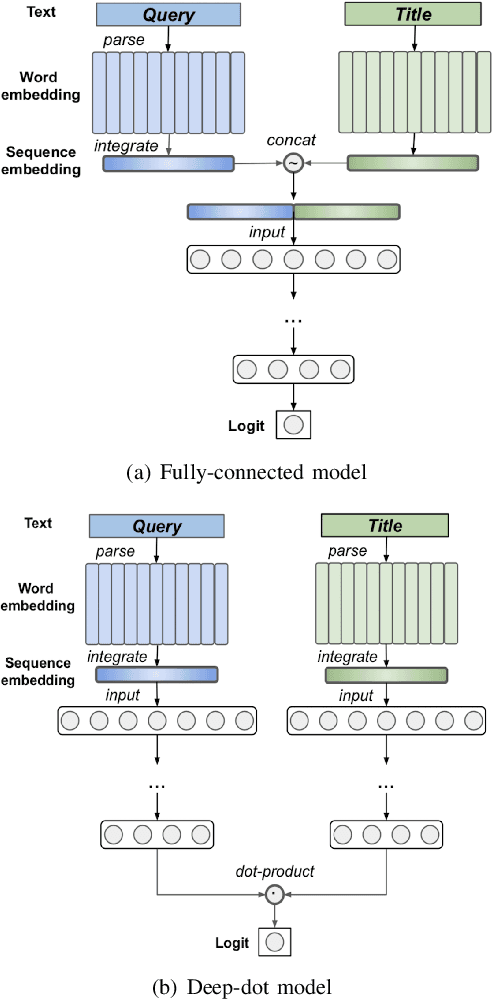
Relevance has significant impact on user experience and business profit for e-commerce search platform. In this work, we propose a data-driven framework for search relevance prediction, by distilling knowledge from BERT and related multi-layer Transformer teacher models into simple feed-forward networks with large amount of unlabeled data. The distillation process produces a student model that recovers more than 97\% test accuracy of teacher models on new queries, at a serving cost that's several magnitude lower (latency 150x lower than BERT-Base and 15x lower than the most efficient BERT variant, TinyBERT). The applications of temperature rescaling and teacher model stacking further boost model accuracy, without increasing the student model complexity. We present experimental results on both in-house e-commerce search relevance data as well as a public data set on sentiment analysis from the GLUE benchmark. The latter takes advantage of another related public data set of much larger scale, while disregarding its potentially noisy labels. Embedding analysis and case study on the in-house data further highlight the strength of the resulting model. By making the data processing and model training source code public, we hope the techniques presented here can help reduce energy consumption of the state of the art Transformer models and also level the playing field for small organizations lacking access to cutting edge machine learning hardwares.
Fine-tune BERT for E-commerce Non-Default Search Ranking
Aug 21, 2020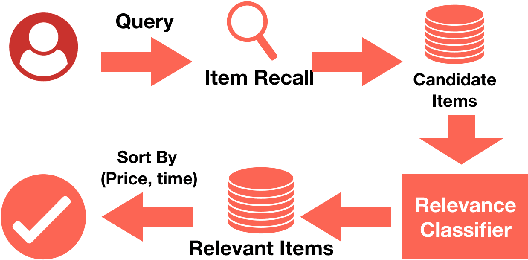
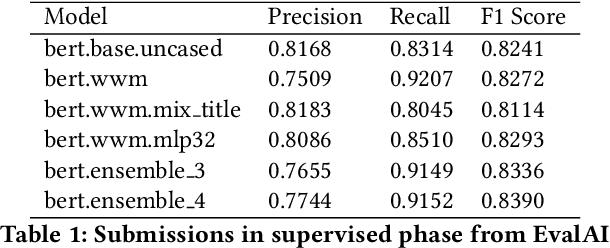
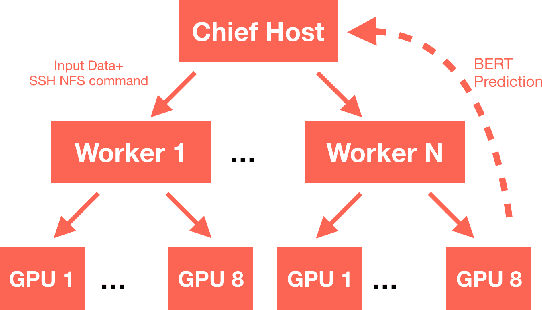
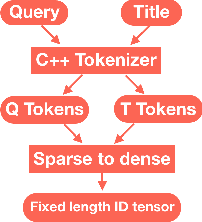
The quality of non-default ranking on e-commerce platforms, such as based on ascending item price or descending historical sales volume, often suffers from acute relevance problems, since the irrelevant items are much easier to be exposed at the top of the ranking results. In this work, we propose a two-stage ranking scheme, which first recalls wide range of candidate items through refined query/title keyword matching, and then classifies the recalled items using BERT-Large fine-tuned on human label data. We also implemented parallel prediction on multiple GPU hosts and a C++ tokenization custom op of Tensorflow. In this data challenge, our model won the 1st place in the supervised phase (based on overall F1 score) and 2nd place in the final phase (based on average per query F1 score).