 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT2DNN: BERT Distillation with Massive Unlabeled Data for Online E-Commerce Search
Paper and Code
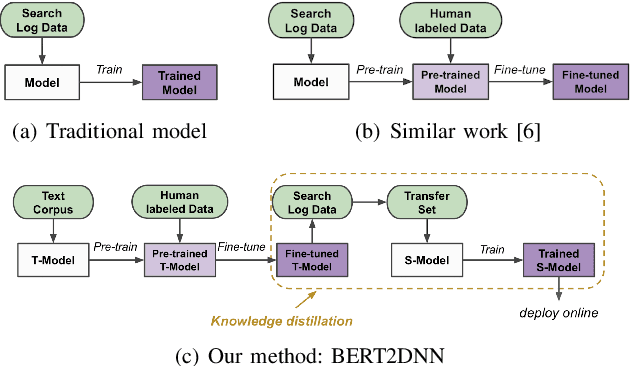

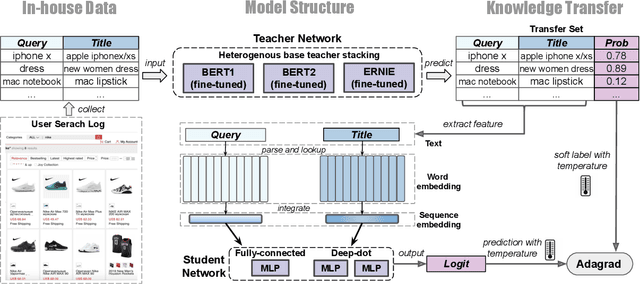
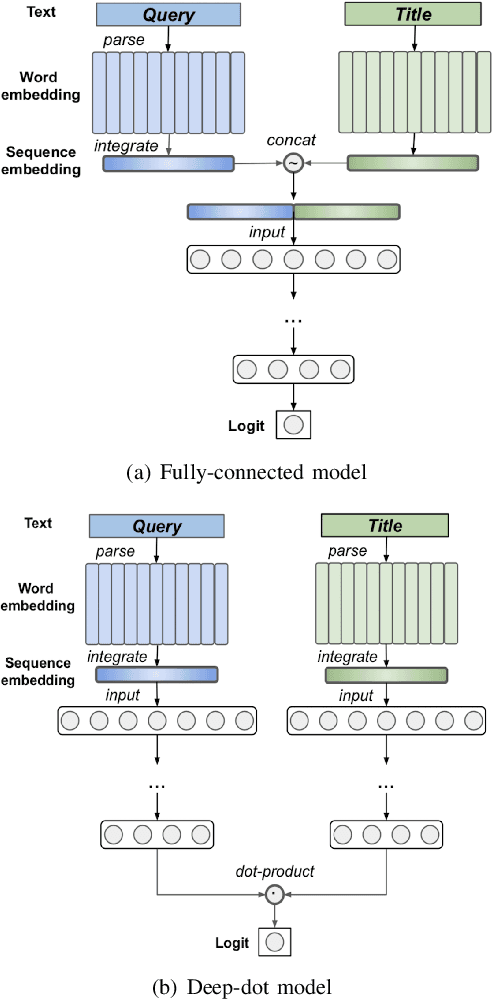
Relevance has significant impact on user experience and business profit for e-commerce search platform. In this work, we propose a data-driven framework for search relevance prediction, by distilling knowledge from BERT and related multi-layer Transformer teacher models into simple feed-forward networks with large amount of unlabeled data. The distillation process produces a student model that recovers more than 97\% test accuracy of teacher models on new queries, at a serving cost that's several magnitude lower (latency 150x lower than BERT-Base and 15x lower than the most efficient BERT variant, TinyBERT). The applications of temperature rescaling and teacher model stacking further boost model accuracy, without increasing the student model complexity. We present experimental results on both in-house e-commerce search relevance data as well as a public data set on sentiment analysis from the GLUE benchmark. The latter takes advantage of another related public data set of much larger scale, while disregarding its potentially noisy labels. Embedding analysis and case study on the in-house data further highlight the strength of the resulting model. By making the data processing and model training source code public, we hope the techniques presented here can help reduce energy consumption of the state of the art Transformer models and also level the playing field for small organizations lacking access to cutting edge machine learning hardwares.