 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSGPT: Domain-Specific Generative Pre-Training of Transformers for Text Generation in E-commerce Title and Review Summarization
Dec 15, 2021
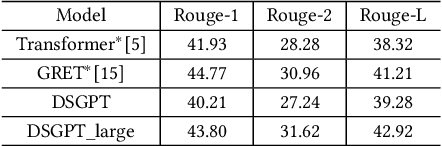
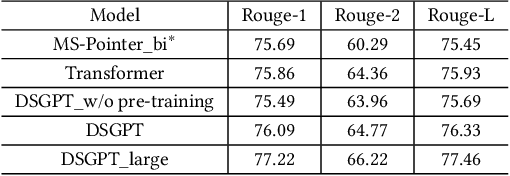
We propose a novel domain-specific generative pre-training (DS-GPT) method for text generation and apply it to the product titleand review summarization problems on E-commerce mobile display.First, we adopt a decoder-only transformer architecture, which fitswell for fine-tuning tasks by combining input and output all to-gether. Second, we demonstrate utilizing only small amount of pre-training data in related domains is powerful. Pre-training a languagemodel from a general corpus such as Wikipedia or the CommonCrawl requires tremendous time and resource commitment, andcan be wasteful if the downstream tasks are limited in variety. OurDSGPT is pre-trained on a limited dataset, the Chinese short textsummarization dataset (LCSTS). Third, our model does not requireproduct-related human-labeled data. For title summarization task,the state of art explicitly uses additional background knowledgein training and predicting stages. In contrast, our model implic-itly captures this knowledge and achieves significant improvementover other methods, after fine-tuning on the public Taobao.comdataset. For review summarization task, we utilize JD.com in-housedataset, and observe similar improvement over standard machinetranslation methods which lack the flexibility of fine-tuning. Ourproposed work can be simply extended to other domains for a widerange of text generation tasks.
Heterogeneous Network Embedding for Deep Semantic Relevance Match in E-commerce Search
Jan 13, 2021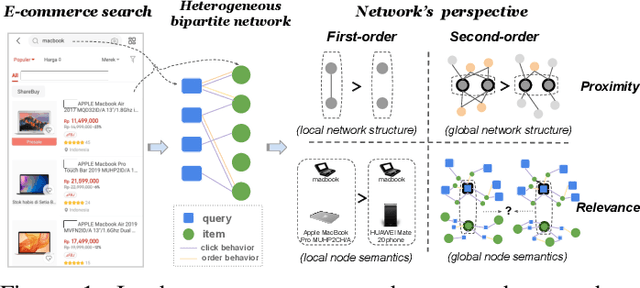
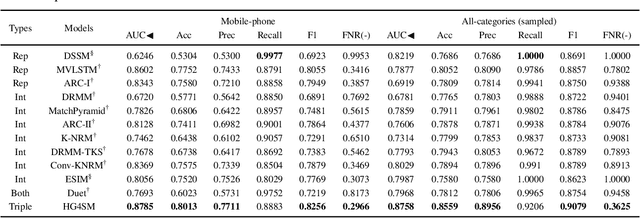
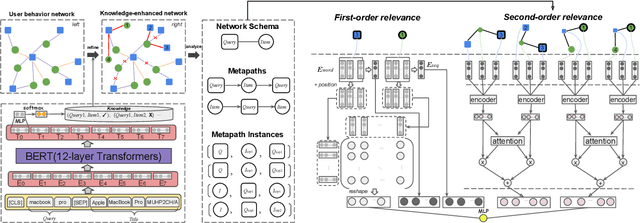
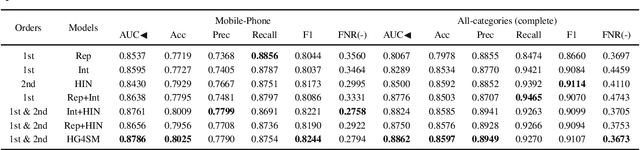
Result relevance prediction is an essential task of e-commerce search engines to boost the utility of search engines and ensure smooth user experience. The last few years eyewitnessed a flurry of research on the use of Transformer-style models and deep text-match models to improve relevance. However, these two types of models ignored the inherent bipartite network structures that are ubiquitous in e-commerce search logs, making these models ineffective. We propose in this paper a novel Second-order Relevance, which is fundamentally different from the previous First-order Relevance, to improve result relevance prediction. We design, for the first time, an end-to-end First-and-Second-order Relevance prediction model for e-commerce item relevance. The model is augmented by the neighborhood structures of bipartite networks that are built using the information of user behavioral feedback, including clicks and purchases. To ensure that edges accurately encode relevance information, we introduce external knowledge generated from BERT to refine the network of user behaviors. This allows the new model to integrate information from neighboring items and queries, which are highly relevant to the focus query-item pair under consideration. Results of offline experiments showed that the new model significantly improved the prediction accuracy in terms of human relevance judgment. An ablation study showed that the First-and-Second-order model gained a 4.3% average gain over the First-order model. Results of an online A/B test revealed that the new model derived more commercial benefits compared to the base model.
BiTe-GCN: A New GCN Architecture via BidirectionalConvolution of Topology and Features on Text-Rich Networks
Oct 23, 2020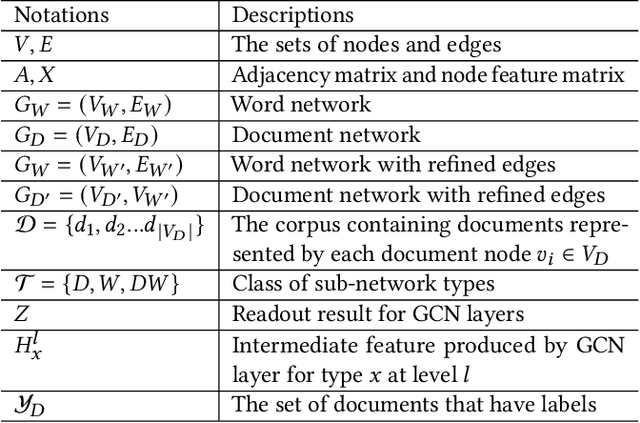

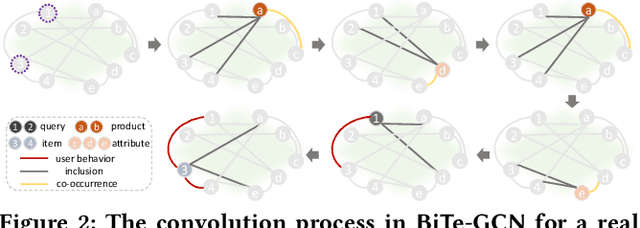
Graph convolutional networks (GCNs), aiming to integrate high-order neighborhood information through stacked graph convolution layers, have demonstrated remarkable power in many network analysis tasks. However, topological limitations, including over-smoothing and local topology homophily, limit its capability to represent networks. Existing studies only perform feature convolution on network topology, which inevitably introduces unbalance between topology and features. Considering that in real world, the information network consists of not only the node-level citation information but also the local text-sequence information. We propose BiTe-GCN, a novel GCN architecture with bidirectional convolution of both topology and features on text-rich networks to solve these limitations. We first transform the original text-rich network into an augmented bi-typed heterogeneous network, capturing both the global node-level information and the local text-sequence information from texts. We then introduce discriminative convolution mechanisms to performs convolutions of both topology and features simultaneously. Extensive experiments on text-rich networks demonstrate that our new architecture outperforms state-of-the-art by a breakout improvement. Moreover, this architecture can also be applied to several e-commerce searching scenes such as JD\ searching. The experiments on the JD dataset validate the superiority of the proposed architecture over the related methods.