 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Generation of Product-Image Sequence in E-commerce
Jun 26, 2022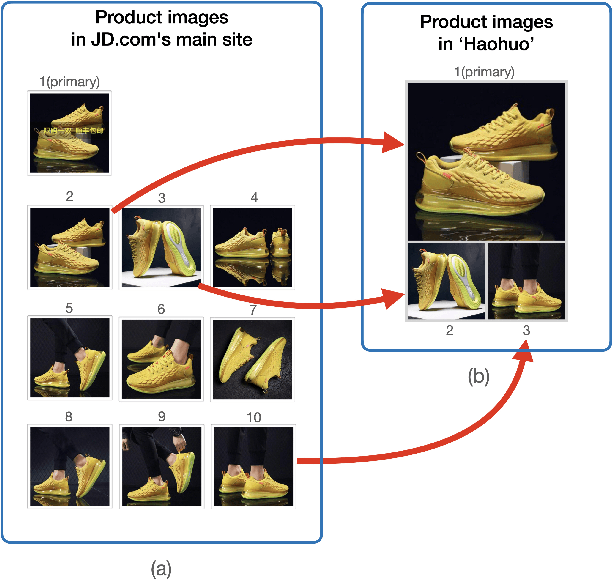

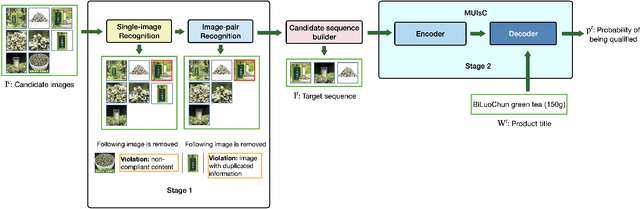
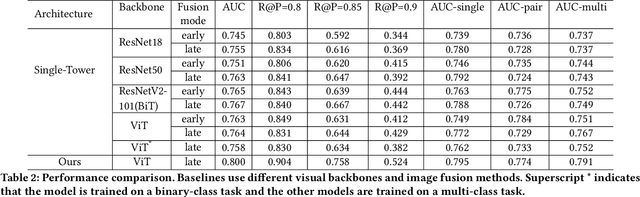
Product images are essential for providing desirable user experience in an e-commerce platform. For a platform with billions of products, it is extremely time-costly and labor-expensive to manually pick and organize qualified images. Furthermore, there are the numerous and complicated image rules that a product image needs to comply in order to be generated/selected. To address these challenges, in this paper, we present a new learning framework in order to achieve Automatic Generation of Product-Image Sequence (AGPIS) in e-commerce. To this end, we propose a Multi-modality Unified Image-sequence Classifier (MUIsC), which is able to simultaneously detect all categories of rule violations through learning. MUIsC leverages textual review feedback as the additional training target and utilizes product textual description to provide extra semantic information. Based on offline evaluations, we show that the proposed MUIsC significantly outperforms various baselines. Besides MUIsC, we also integrate some other important modules in the proposed framework, such as primary image selection, noncompliant content detection, and image deduplication. With all these modules, our framework works effectively and efficiently in JD.com recommendation platform. By Dec 2021, our AGPIS framework has generated high-standard images for about 1.5 million products and achieves 13.6% in reject rate.
Scenario-based Multi-product Advertising Copywriting Generation for E-Commerce
May 21, 2022

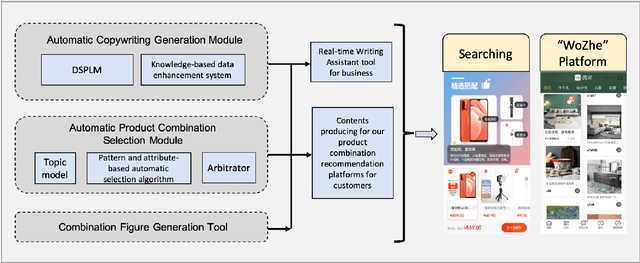
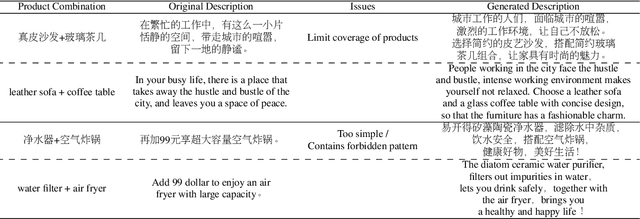
In this paper, we proposed an automatic Scenario-based Multi-product Advertising Copywriting Generation system (SMPACG) for E-Commerce, which has been deployed on a leading Chinese e-commerce platform. The proposed SMPACG consists of two main components: 1) an automatic multi-product combination selection module, which itself is consisted of a topic prediction model, a pattern and attribute-based selection model and an arbitrator model; and 2) an automatic multi-product advertising copywriting generation module, which combines our proposed domain-specific pretrained language model and knowledge-based data enhancement model. The SMPACG is the first system that realizes automatic scenario-based multi-product advertising contents generation, which achieves significant improvements over other state-of-the-art methods. The SMPACG has been not only developed for directly serving for our e-commerce recommendation system, but also used as a real-time writing assistant tool for merchants.
DSGPT: Domain-Specific Generative Pre-Training of Transformers for Text Generation in E-commerce Title and Review Summarization
Dec 15, 2021
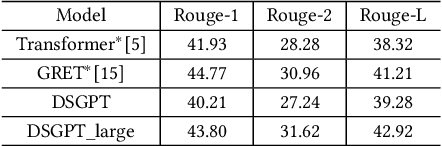
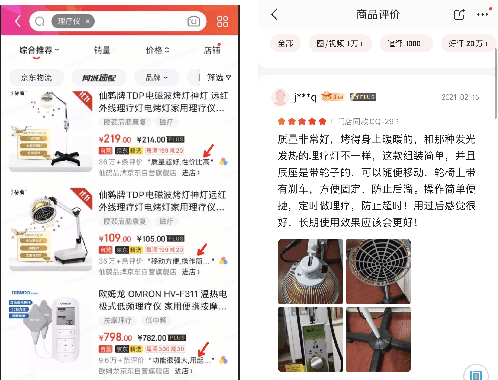
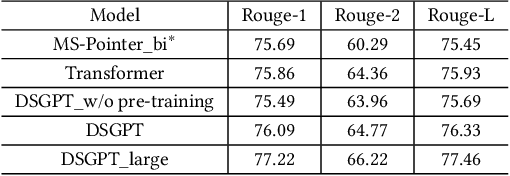
We propose a novel domain-specific generative pre-training (DS-GPT) method for text generation and apply it to the product titleand review summarization problems on E-commerce mobile display.First, we adopt a decoder-only transformer architecture, which fitswell for fine-tuning tasks by combining input and output all to-gether. Second, we demonstrate utilizing only small amount of pre-training data in related domains is powerful. Pre-training a languagemodel from a general corpus such as Wikipedia or the CommonCrawl requires tremendous time and resource commitment, andcan be wasteful if the downstream tasks are limited in variety. OurDSGPT is pre-trained on a limited dataset, the Chinese short textsummarization dataset (LCSTS). Third, our model does not requireproduct-related human-labeled data. For title summarization task,the state of art explicitly uses additional background knowledgein training and predicting stages. In contrast, our model implic-itly captures this knowledge and achieves significant improvementover other methods, after fine-tuning on the public Taobao.comdataset. For review summarization task, we utilize JD.com in-housedataset, and observe similar improvement over standard machinetranslation methods which lack the flexibility of fine-tuning. Ourproposed work can be simply extended to other domains for a widerange of text generation tasks.
A Top-down Approach to Articulated Human Pose Estimation and Tracking
Jan 23, 2019

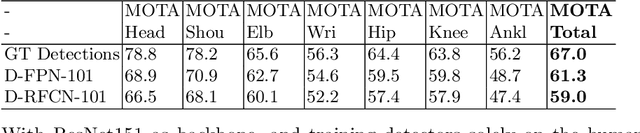
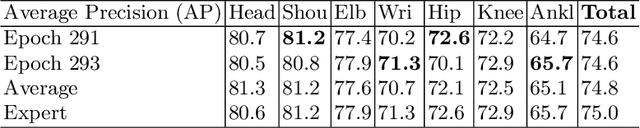
Both the tasks of multi-person human pose estimation and pose tracking in videos are quite challenging. Existing methods can be categorized into two groups: top-down and bottom-up approaches. In this paper, following the top-down approach, we aim to build a strong baseline system with three modules: human candidate detector, single-person pose estimator and human pose tracker. Firstly, we choose a generic object detector among state-of-the-art methods to detect human candidates. Then, the cascaded pyramid network is used to estimate the corresponding human pose. Finally, we use a flow-based pose tracker to render keypoint-association across frames, i.e., assigning each human candidate a unique and temporally-consistent id, for the multi-target pose tracking purpose. We conduct extensive ablative experiments to validate various choices of models and configurations. We take part in two ECCV 18 PoseTrack challenges: pose estimation and pose tracking.
Object Detection with Mask-based Feature Encoding
Feb 12, 2018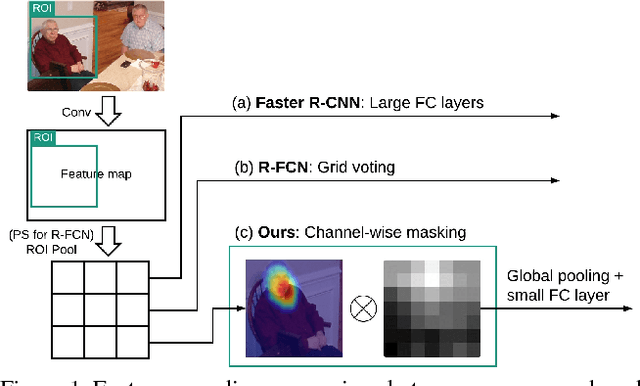



Region-based Convolutional Neural Networks (R-CNNs) have achieved great success in the field of object detection. The existing R-CNNs usually divide a Region-of-Interest (ROI) into grids, and then localize objects by utilizing the spatial information reflected by the relative position of each grid in the ROI. In this paper, we propose a novel feature-encoding approach, where spatial information is represented through the spatial distributions of visual patterns. In particular, we design a Mask Weight Network (MWN) to learn a set of masks and then apply channel-wise masking operations to ROI feature map, followed by a global pooling and a cheap fully-connected layer. We integrate the newly designed feature encoder into the Faster R-CNN architecture. The resulting new Faster R-CNNs can preserve the object-detection accuracy of the standard Faster R-CNNs by using substantially fewer parameters. Compared to R-FCNs using state-of-art PS ROI pooling and deformable PS ROI pooling, the new Faster R-CNNs can produce higher object-detection accuracy with good run-time efficiency. We also show that a specifically designed and learned MWN can capture global contextual information and further improve the object-detection accuracy. Validation experiments are conducted on both PASCAL VOC and MS COCO datasets.
Detecting Small Signs from Large Images
Jun 26, 2017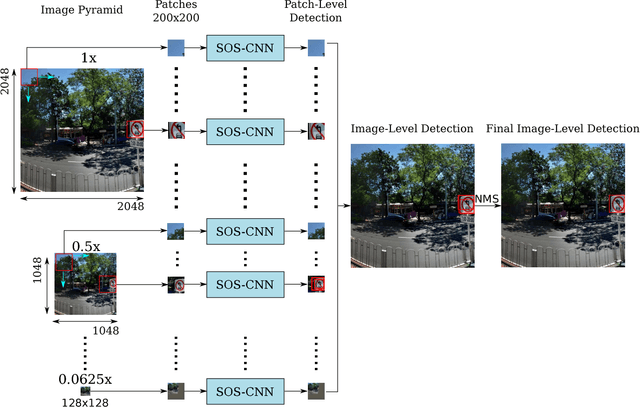



In the past decade, Convolutional Neural Networks (CNNs) have been demonstrated successful for object detections. However, the size of network input is limited by the amount of memory available on GPUs. Moreover, performance degrades when detecting small objects. To alleviate the memory usage and improve the performance of detecting small traffic signs, we proposed an approach for detecting small traffic signs from large images under real world conditions. In particular, large images are broken into small patches as input to a Small-Object-Sensitive-CNN (SOS-CNN) modified from a Single Shot Multibox Detector (SSD) framework with a VGG-16 network as the base network to produce patch-level object detection results. Scale invariance is achieved by applying the SOS-CNN on an image pyramid. Then, image-level object detection is obtained by projecting all the patch-level detection results to the image at the original scale. Experimental results on a real-world conditioned traffic sign dataset have demonstrated the effectiveness of the proposed method in terms of detection accuracy and recall, especially for those with small sizes.
Co-interest Person Detection from Multiple Wearable Camera Videos
Sep 05, 2015

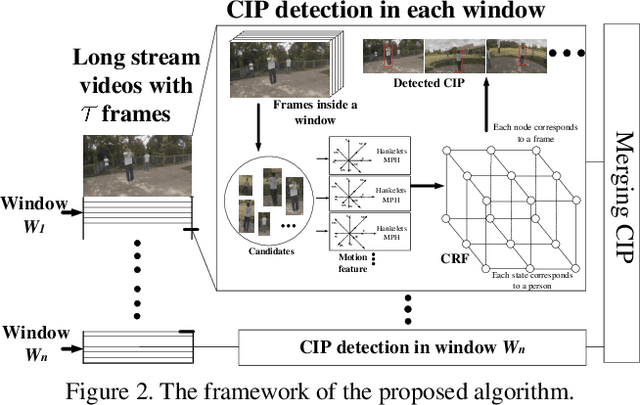
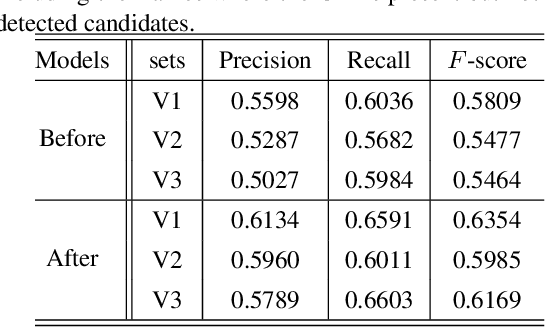
Wearable cameras, such as Google Glass and Go Pro, enable video data collection over larger areas and from different views. In this paper, we tackle a new problem of locating the co-interest person (CIP), i.e., the one who draws attention from most camera wearers, from temporally synchronized videos taken by multiple wearable cameras. Our basic idea is to exploit the motion patterns of people and use them to correlate the persons across different videos, instead of performing appearance-based matching as in traditional video co-segmentation/localization. This way, we can identify CIP even if a group of people with similar appearance are present in the view. More specifically, we detect a set of persons on each frame as the candidates of the CIP and then build a Conditional Random Field (CRF) model to select the one with consistent motion patterns in different videos and high spacial-temporal consistency in each video. We collect three sets of wearable-camera videos for testing the proposed algorithm. All the involved people have similar appearances in the collected videos and the experiments demonstrate the effectiveness of the proposed algorithm.
Combining Local Appearance and Holistic View: Dual-Source Deep Neural Networks for Human Pose Estimation
Apr 27, 2015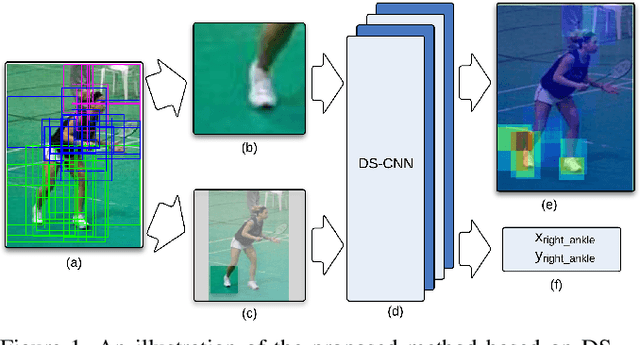
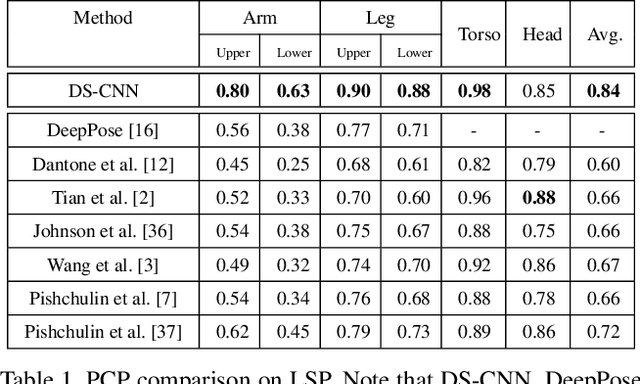


We propose a new learning-based method for estimating 2D human pose from a single image, using Dual-Source Deep Convolutional Neural Networks (DS-CNN). Recently, many methods have been developed to estimate human pose by using pose priors that are estimated from physiologically inspired graphical models or learned from a holistic perspective. In this paper, we propose to integrate both the local (body) part appearance and the holistic view of each local part for more accurate human pose estimation. Specifically, the proposed DS-CNN takes a set of image patches (category-independent object proposals for training and multi-scale sliding windows for testing) as the input and then learns the appearance of each local part by considering their holistic views in the full body. Using DS-CNN, we achieve both joint detection, which determines whether an image patch contains a body joint, and joint localization, which finds the exact location of the joint in the image patch. Finally, we develop an algorithm to combine these joint detection/localization results from all the image patches for estimating the human pose. The experimental results show the effectiveness of the proposed method by comparing to the state-of-the-art human-pose estimation methods based on pose priors that are estimated from physiologically inspired graphical models or learned from a holistic perspective.