 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObject Detection with Mask-based Feature Encoding
Paper and Code
Feb 12, 2018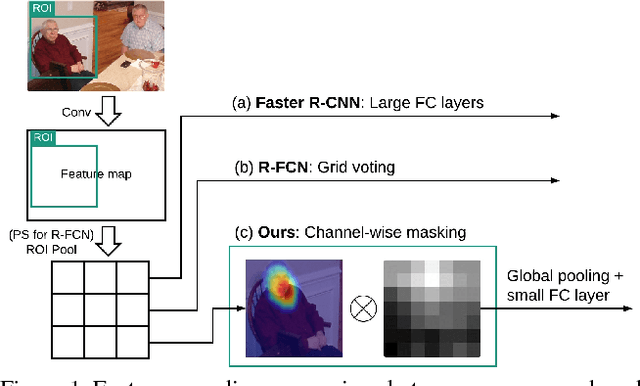



Region-based Convolutional Neural Networks (R-CNNs) have achieved great success in the field of object detection. The existing R-CNNs usually divide a Region-of-Interest (ROI) into grids, and then localize objects by utilizing the spatial information reflected by the relative position of each grid in the ROI. In this paper, we propose a novel feature-encoding approach, where spatial information is represented through the spatial distributions of visual patterns. In particular, we design a Mask Weight Network (MWN) to learn a set of masks and then apply channel-wise masking operations to ROI feature map, followed by a global pooling and a cheap fully-connected layer. We integrate the newly designed feature encoder into the Faster R-CNN architecture. The resulting new Faster R-CNNs can preserve the object-detection accuracy of the standard Faster R-CNNs by using substantially fewer parameters. Compared to R-FCNs using state-of-art PS ROI pooling and deformable PS ROI pooling, the new Faster R-CNNs can produce higher object-detection accuracy with good run-time efficiency. We also show that a specifically designed and learned MWN can capture global contextual information and further improve the object-detection accuracy. Validation experiments are conducted on both PASCAL VOC and MS COCO datasets.