 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Multimodal Fusion for Optical and Scene Flow
Jul 28, 2023



This paper presents an investigation into the estimation of optical and scene flow using RGBD information in scenarios where the RGB modality is affected by noise or captured in dark environments. Existing methods typically rely solely on RGB images or fuse the modalities at later stages, which can result in lower accuracy when the RGB information is unreliable. To address this issue, we propose a novel deep neural network approach named FusionRAFT, which enables early-stage information fusion between sensor modalities (RGB and depth). Our approach incorporates self- and cross-attention layers at different network levels to construct informative features that leverage the strengths of both modalities. Through comparative experiments, we demonstrate that our approach outperforms recent methods in terms of performance on the synthetic dataset Flyingthings3D, as well as the generalization on the real-world dataset KITTI. We illustrate that our approach exhibits improved robustness in the presence of noise and low-lighting conditions that affect the RGB images. We release the code, models and dataset at https://github.com/jiesico/FusionRAFT.
Loop closure detection using local 3D deep descriptors
Oct 31, 2021

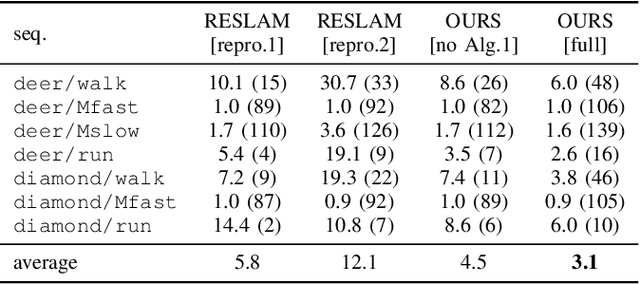
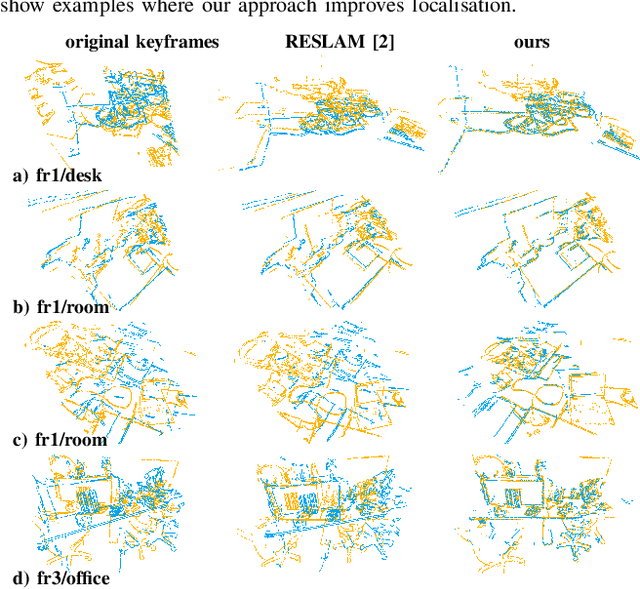
We present a simple yet effective method to address loop closure detection in simultaneous localisation and mapping using local 3D deep descriptors (L3Ds). L3Ds are emerging compact representations of patches extracted from point clouds that are learned from data using a deep learning algorithm. We propose a novel overlap measure for loop detection by computing the metric error between points that correspond to mutually-nearest-neighbour descriptors after registering the loop candidate point cloud by its estimated relative pose. This novel approach enables us to accurately detect loops and estimate six degrees-of-freedom poses in the case of small overlaps. We compare our L3D-based loop closure approach with recent approaches on LiDAR data and achieve state-of-the-art loop closure detection accuracy. Additionally, we embed our loop closure approach in RESLAM, a recent edge-based SLAM system, and perform the evaluation on real-world RGBD-TUM and synthetic ICL datasets. Our approach enables RESLAM to achieve a better localisation accuracy compared to its original loop closure strategy.
LooseCut: Interactive Image Segmentation with Loosely Bounded Boxes
Nov 22, 2015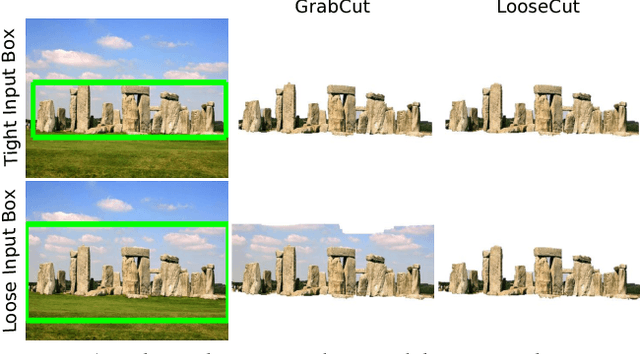


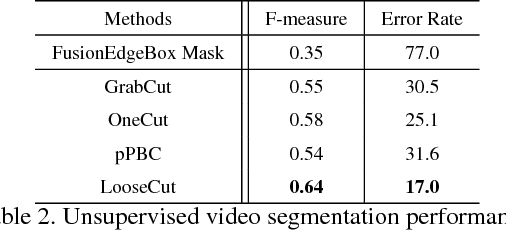
One popular approach to interactively segment the foreground object of interest from an image is to annotate a bounding box that covers the foreground object. Then, a binary labeling is performed to achieve a refined segmentation. One major issue of the existing algorithms for such interactive image segmentation is their preference of an input bounding box that tightly encloses the foreground object. This increases the annotation burden, and prevents these algorithms from utilizing automatically detected bounding boxes. In this paper, we develop a new LooseCut algorithm that can handle cases where the input bounding box only loosely covers the foreground object. We propose a new Markov Random Fields (MRF) model for segmentation with loosely bounded boxes, including a global similarity constraint to better distinguish the foreground and background, and an additional energy term to encourage consistent labeling of similar-appearance pixels. This MRF model is then solved by an iterated max-flow algorithm. In the experiments, we evaluate LooseCut in three publicly-available image datasets, and compare its performance against several state-of-the-art interactive image segmentation algorithms. We also show that LooseCut can be used for enhancing the performance of unsupervised video segmentation and image saliency detection.
Unsupervised Cross-Domain Recognition by Identifying Compact Joint Subspaces
Sep 05, 2015
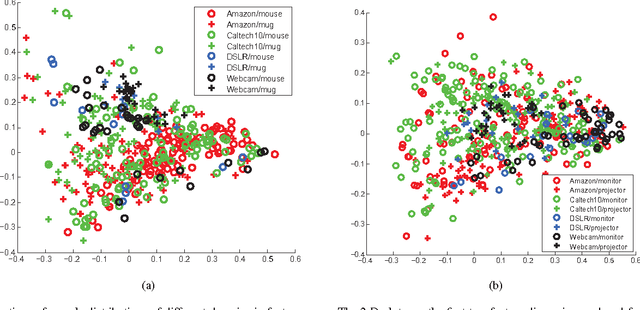
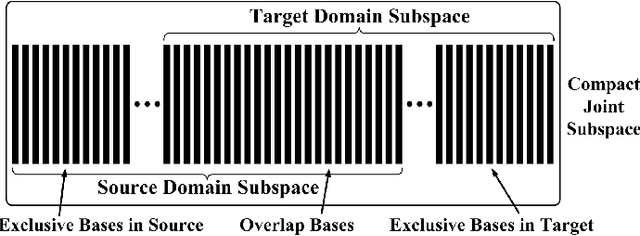
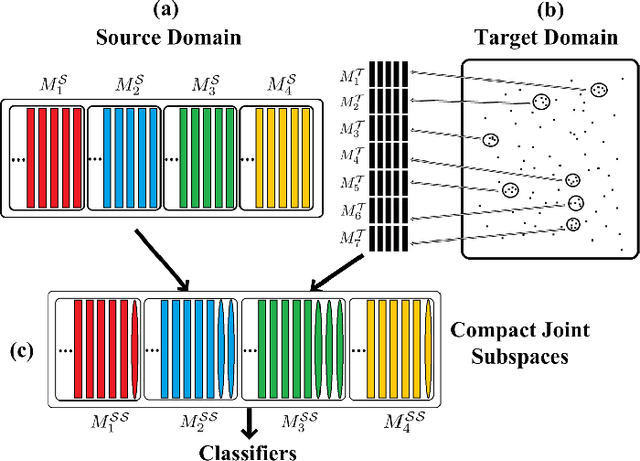
This paper introduces a new method to solve the cross-domain recognition problem. Different from the traditional domain adaption methods which rely on a global domain shift for all classes between source and target domain, the proposed method is more flexible to capture individual class variations across domains. By adopting a natural and widely used assumption -- "the data samples from the same class should lay on a low-dimensional subspace, even if they come from different domains", the proposed method circumvents the limitation of the global domain shift, and solves the cross-domain recognition by finding the compact joint subspaces of source and target domain. Specifically, given labeled samples in source domain, we construct subspaces for each of the classes. Then we construct subspaces in the target domain, called anchor subspaces, by collecting unlabeled samples that are close to each other and highly likely all fall into the same class. The corresponding class label is then assigned by minimizing a cost function which reflects the overlap and topological structure consistency between subspaces across source and target domains, and within anchor subspaces, respectively.We further combine the anchor subspaces to corresponding source subspaces to construct the compact joint subspaces. Subsequently, one-vs-rest SVM classifiers are trained in the compact joint subspaces and applied to unlabeled data in the target domain. We evaluate the proposed method on two widely used datasets: object recognition dataset for computer vision tasks, and sentiment classification dataset for natural language processing tasks. Comparison results demonstrate that the proposed method outperforms the comparison methods on both datasets.
Co-interest Person Detection from Multiple Wearable Camera Videos
Sep 05, 2015

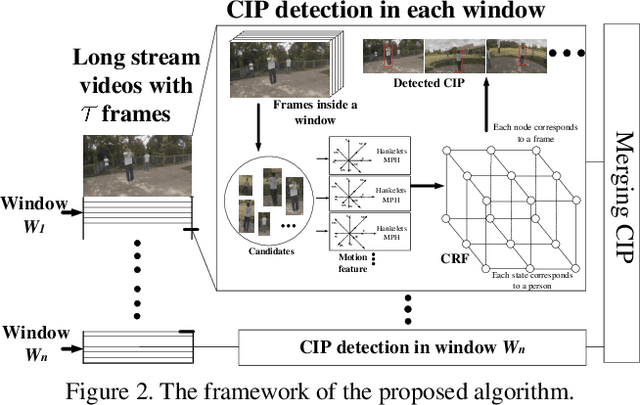
Wearable cameras, such as Google Glass and Go Pro, enable video data collection over larger areas and from different views. In this paper, we tackle a new problem of locating the co-interest person (CIP), i.e., the one who draws attention from most camera wearers, from temporally synchronized videos taken by multiple wearable cameras. Our basic idea is to exploit the motion patterns of people and use them to correlate the persons across different videos, instead of performing appearance-based matching as in traditional video co-segmentation/localization. This way, we can identify CIP even if a group of people with similar appearance are present in the view. More specifically, we detect a set of persons on each frame as the candidates of the CIP and then build a Conditional Random Field (CRF) model to select the one with consistent motion patterns in different videos and high spacial-temporal consistency in each video. We collect three sets of wearable-camera videos for testing the proposed algorithm. All the involved people have similar appearances in the collected videos and the experiments demonstrate the effectiveness of the proposed algorithm.
Feature Sampling Strategies for Action Recognition
Jan 28, 2015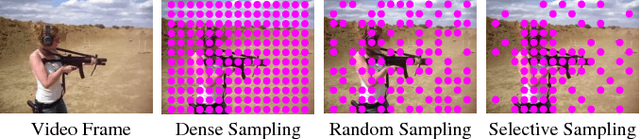
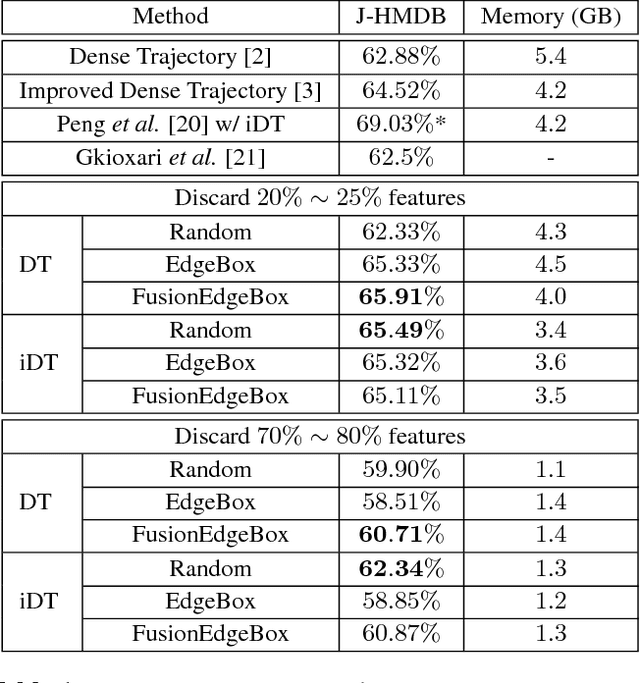

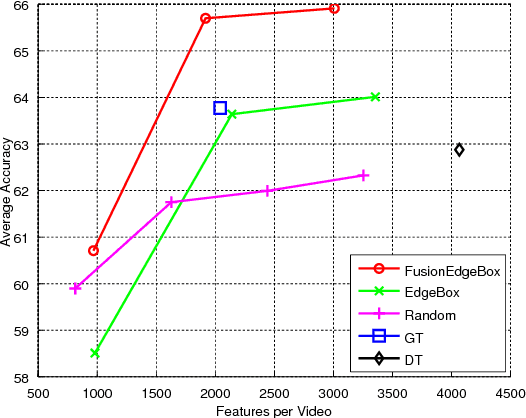
Although dense local spatial-temporal features with bag-of-features representation achieve state-of-the-art performance for action recognition, the huge feature number and feature size prevent current methods from scaling up to real size problems. In this work, we investigate different types of feature sampling strategies for action recognition, namely dense sampling, uniformly random sampling and selective sampling. We propose two effective selective sampling methods using object proposal techniques. Experiments conducted on a large video dataset show that we are able to achieve better average recognition accuracy using 25% less features, through one of proposed selective sampling methods, and even remain comparable accuracy while discarding 70% features.