 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Cross-Domain Recognition by Identifying Compact Joint Subspaces
Paper and Code
Sep 05, 2015
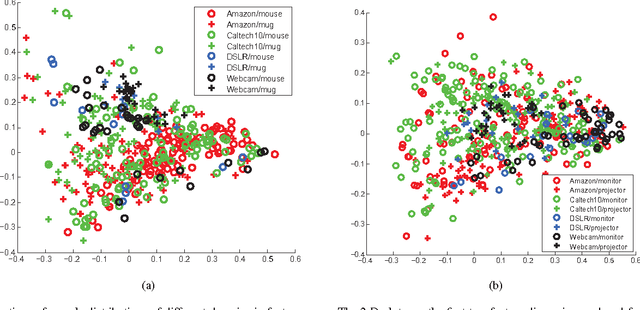
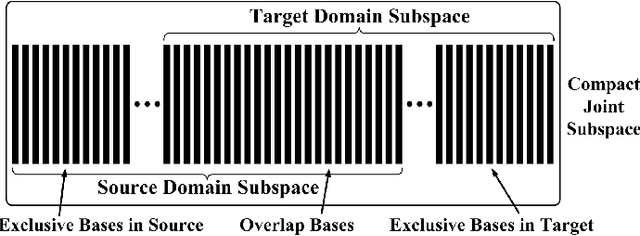
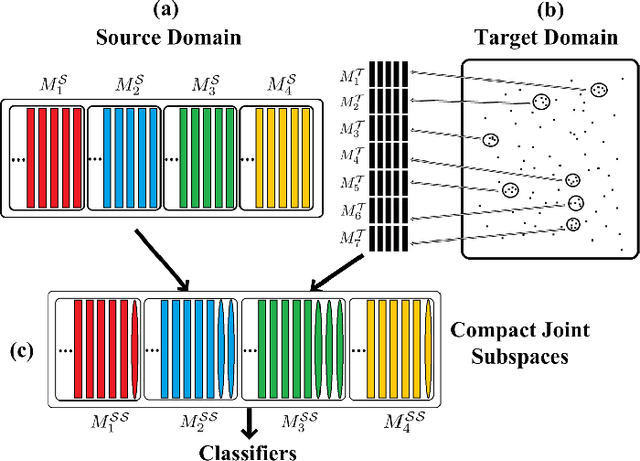
This paper introduces a new method to solve the cross-domain recognition problem. Different from the traditional domain adaption methods which rely on a global domain shift for all classes between source and target domain, the proposed method is more flexible to capture individual class variations across domains. By adopting a natural and widely used assumption -- "the data samples from the same class should lay on a low-dimensional subspace, even if they come from different domains", the proposed method circumvents the limitation of the global domain shift, and solves the cross-domain recognition by finding the compact joint subspaces of source and target domain. Specifically, given labeled samples in source domain, we construct subspaces for each of the classes. Then we construct subspaces in the target domain, called anchor subspaces, by collecting unlabeled samples that are close to each other and highly likely all fall into the same class. The corresponding class label is then assigned by minimizing a cost function which reflects the overlap and topological structure consistency between subspaces across source and target domains, and within anchor subspaces, respectively.We further combine the anchor subspaces to corresponding source subspaces to construct the compact joint subspaces. Subsequently, one-vs-rest SVM classifiers are trained in the compact joint subspaces and applied to unlabeled data in the target domain. We evaluate the proposed method on two widely used datasets: object recognition dataset for computer vision tasks, and sentiment classification dataset for natural language processing tasks. Comparison results demonstrate that the proposed method outperforms the comparison methods on both datasets.