 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning states enhanced knowledge tracing: Simulating the diversity in real-world learning process
Dec 27, 2024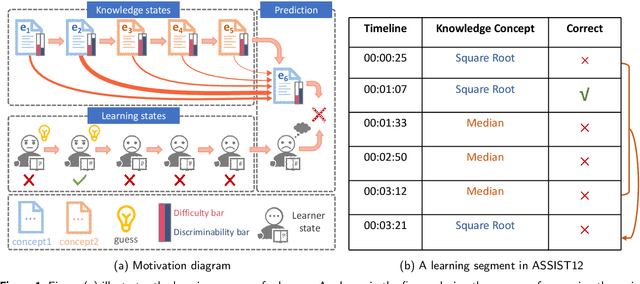
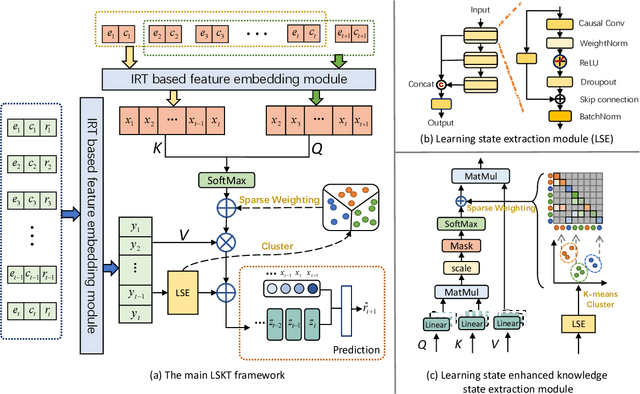
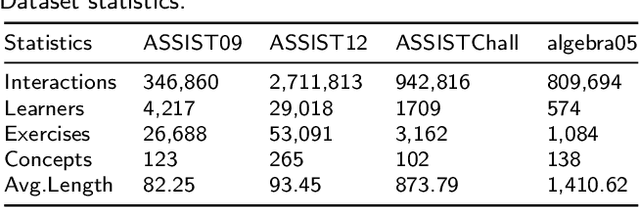
The Knowledge Tracing (KT) task focuses on predicting a learner's future performance based on the historical interactions. The knowledge state plays a key role in learning process. However, considering that the knowledge state is influenced by various learning factors in the interaction process, such as the exercises similarities, responses reliability and the learner's learning state. Previous models still face two major limitations. First, due to the exercises differences caused by various complex reasons and the unreliability of responses caused by guessing behavior, it is hard to locate the historical interaction which is most relevant to the current answered exercise. Second, the learning state is also a key factor to influence the knowledge state, which is always ignored by previous methods. To address these issues, we propose a new method named Learning State Enhanced Knowledge Tracing (LSKT). Firstly, to simulate the potential differences in interactions, inspired by Item Response Theory~(IRT) paradigm, we designed three different embedding methods ranging from coarse-grained to fine-grained views and conduct comparative analysis on them. Secondly, we design a learning state extraction module to capture the changing learning state during the learning process of the learner. In turn, with the help of the extracted learning state, a more detailed knowledge state could be captured. Experimental results on four real-world datasets show that our LSKT method outperforms the current state-of-the-art methods.
Research on Foundation Model for Spatial Data Intelligence: China's 2024 White Paper on Strategic Development of Spatial Data Intelligence
May 30, 2024This report focuses on spatial data intelligent large models, delving into the principles, methods, and cutting-edge applications of these models. It provides an in-depth discussion on the definition, development history, current status, and trends of spatial data intelligent large models, as well as the challenges they face. The report systematically elucidates the key technologies of spatial data intelligent large models and their applications in urban environments, aerospace remote sensing, geography, transportation, and other scenarios. Additionally, it summarizes the latest application cases of spatial data intelligent large models in themes such as urban development, multimodal systems, remote sensing, smart transportation, and resource environments. Finally, the report concludes with an overview and outlook on the development prospects of spatial data intelligent large models.
Halo: Estimation and Reduction of Hallucinations in Open-Source Weak Large Language Models
Sep 13, 2023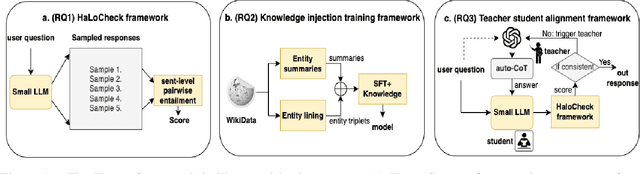
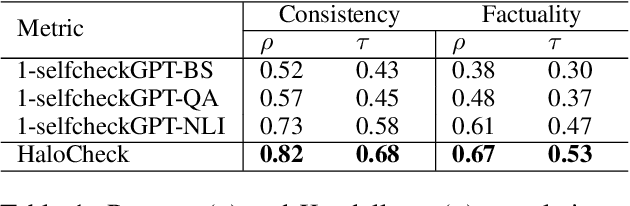
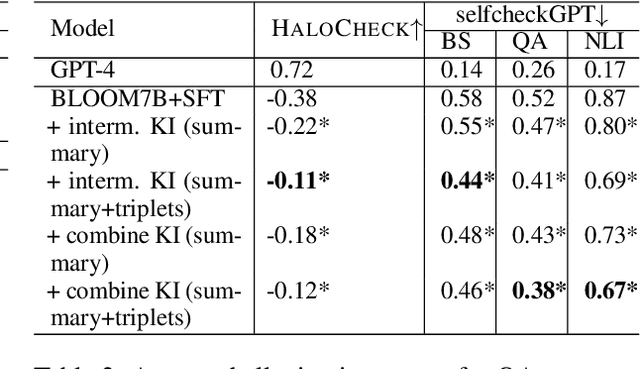
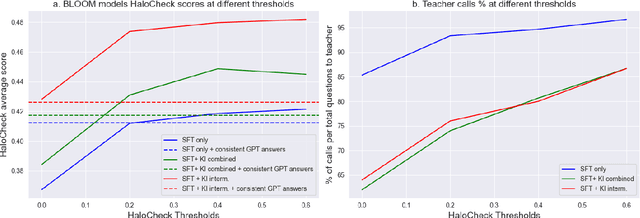
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP). Although convenient for research and practical applications, open-source LLMs with fewer parameters often suffer from severe hallucinations compared to their larger counterparts. This paper focuses on measuring and reducing hallucinations in BLOOM 7B, a representative of such weaker open-source LLMs that are publicly available for research and commercial applications. We introduce HaloCheck, a lightweight BlackBox knowledge-free framework designed to quantify the severity of hallucinations in LLMs. Additionally, we explore techniques like knowledge injection and teacher-student approaches to alleviate hallucinations in low-parameter LLMs. Our experiments effectively demonstrate the reduction of hallucinations in challenging domains for these LLMs.
Automatic Generation of Product-Image Sequence in E-commerce
Jun 26, 2022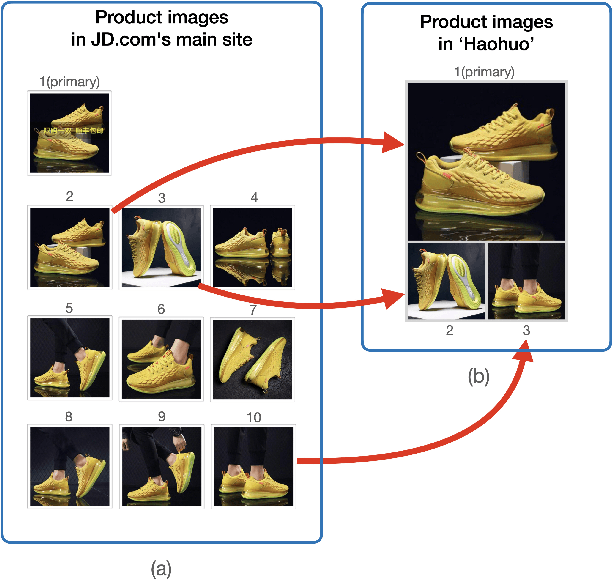

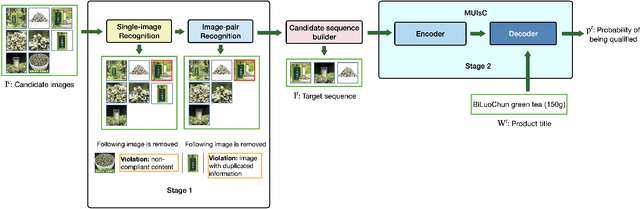
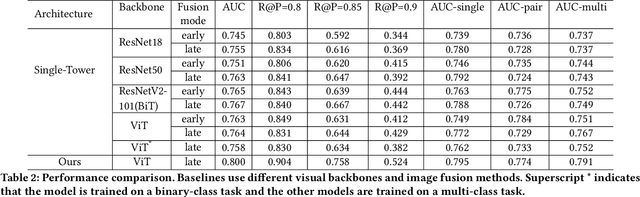
Product images are essential for providing desirable user experience in an e-commerce platform. For a platform with billions of products, it is extremely time-costly and labor-expensive to manually pick and organize qualified images. Furthermore, there are the numerous and complicated image rules that a product image needs to comply in order to be generated/selected. To address these challenges, in this paper, we present a new learning framework in order to achieve Automatic Generation of Product-Image Sequence (AGPIS) in e-commerce. To this end, we propose a Multi-modality Unified Image-sequence Classifier (MUIsC), which is able to simultaneously detect all categories of rule violations through learning. MUIsC leverages textual review feedback as the additional training target and utilizes product textual description to provide extra semantic information. Based on offline evaluations, we show that the proposed MUIsC significantly outperforms various baselines. Besides MUIsC, we also integrate some other important modules in the proposed framework, such as primary image selection, noncompliant content detection, and image deduplication. With all these modules, our framework works effectively and efficiently in JD.com recommendation platform. By Dec 2021, our AGPIS framework has generated high-standard images for about 1.5 million products and achieves 13.6% in reject rate.
Scenario-based Multi-product Advertising Copywriting Generation for E-Commerce
May 21, 2022

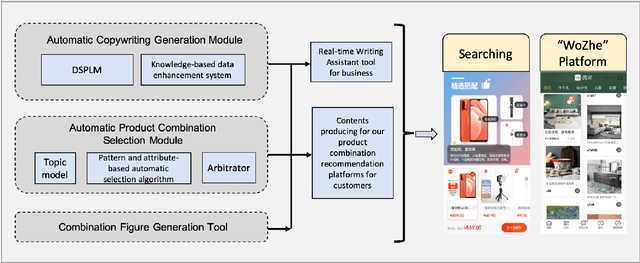
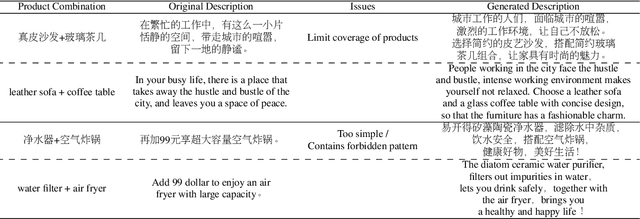
In this paper, we proposed an automatic Scenario-based Multi-product Advertising Copywriting Generation system (SMPACG) for E-Commerce, which has been deployed on a leading Chinese e-commerce platform. The proposed SMPACG consists of two main components: 1) an automatic multi-product combination selection module, which itself is consisted of a topic prediction model, a pattern and attribute-based selection model and an arbitrator model; and 2) an automatic multi-product advertising copywriting generation module, which combines our proposed domain-specific pretrained language model and knowledge-based data enhancement model. The SMPACG is the first system that realizes automatic scenario-based multi-product advertising contents generation, which achieves significant improvements over other state-of-the-art methods. The SMPACG has been not only developed for directly serving for our e-commerce recommendation system, but also used as a real-time writing assistant tool for merchants.
E-LMC: Extended Linear Model of Coregionalization for Predictions of Spatial Fields
Mar 01, 2022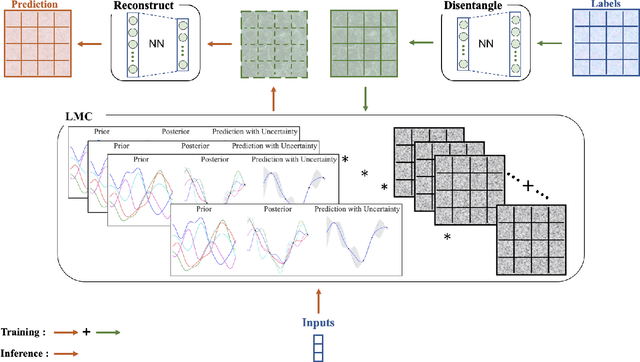
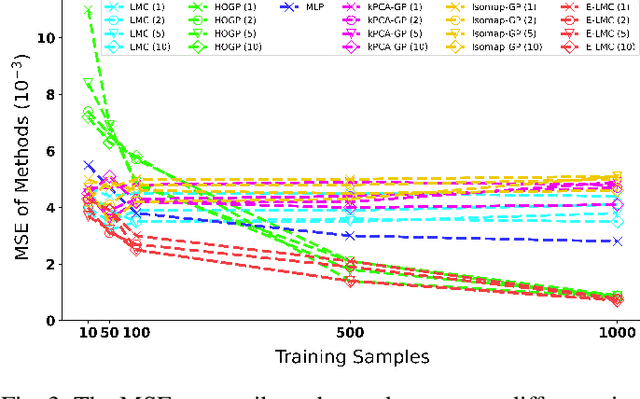
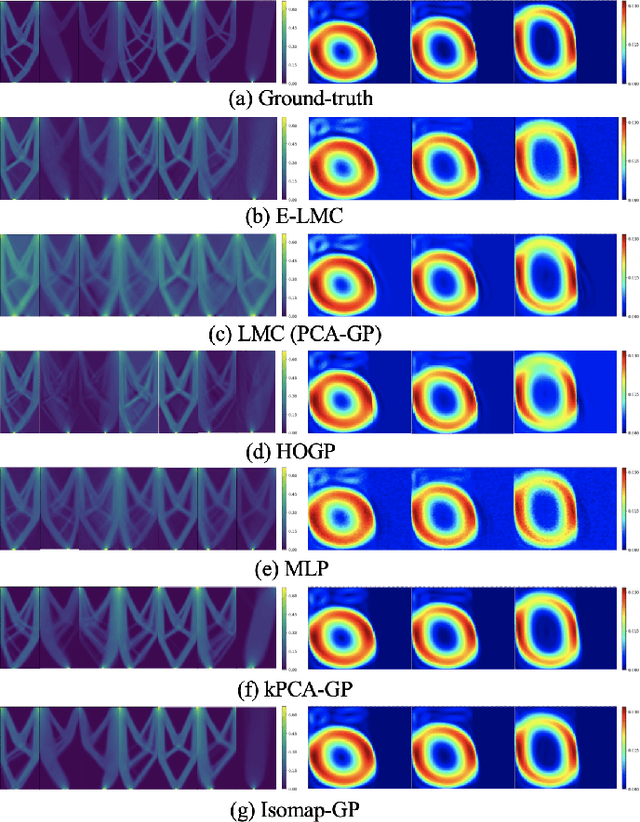
Physical simulations based on partial differential equations typically generate spatial fields results, which are utilized to calculate specific properties of a system for engineering design and optimization. Due to the intensive computational burden of the simulations, a surrogate model mapping the low-dimensional inputs to the spatial fields are commonly built based on a relatively small dataset. To resolve the challenge of predicting the whole spatial field, the popular linear model of coregionalization (LMC) can disentangle complicated correlations within the high-dimensional spatial field outputs and deliver accurate predictions. However, LMC fails if the spatial field cannot be well approximated by a linear combination of base functions with latent processes. In this paper, we extend LMC by introducing an invertible neural network to linearize the highly complex and nonlinear spatial fields such that the LMC can easily generalize to nonlinear problems while preserving the traceability and scalability. Several real-world applications demonstrate that E-LMC can exploit spatial correlations effectively, showing a maximum improvement of about 40% over the original LMC and outperforming the other state-of-the-art spatial field models.
Automatic Product Copywriting for E-Commerce
Dec 15, 2021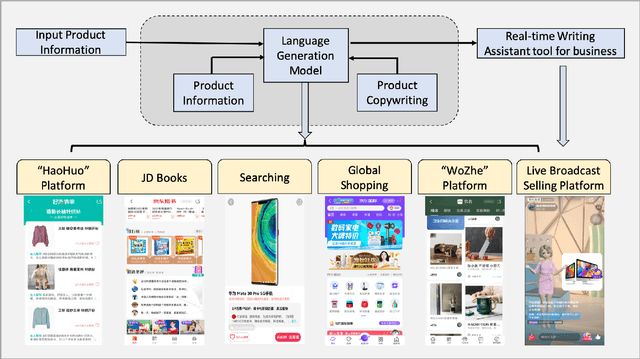

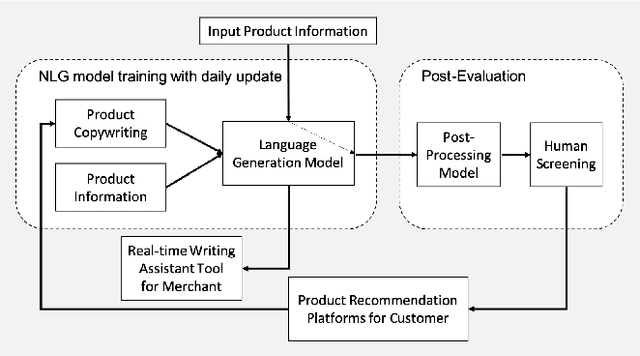
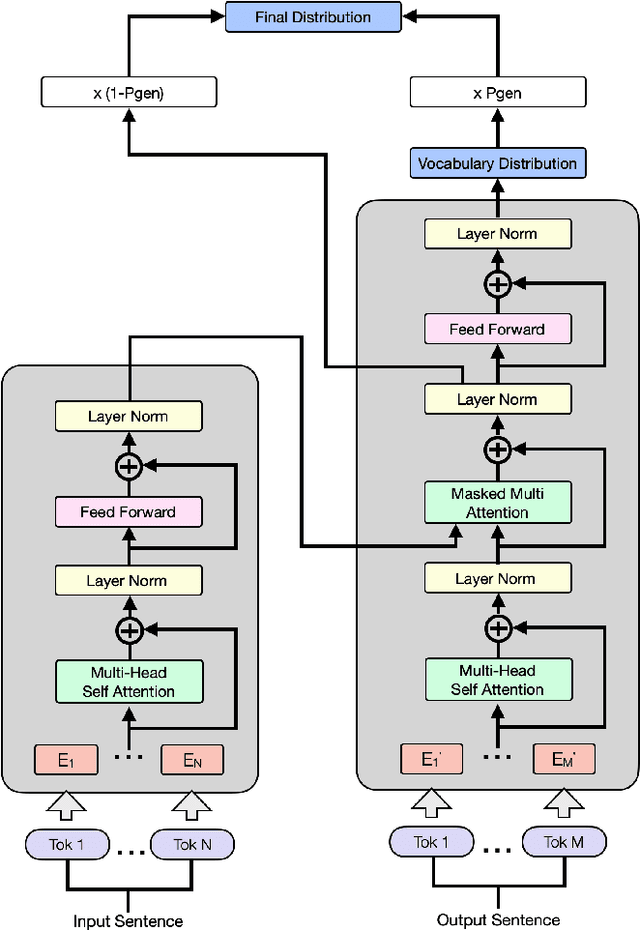
Product copywriting is a critical component of e-commerce recommendation platforms. It aims to attract users' interest and improve user experience by highlighting product characteristics with textual descriptions. In this paper, we report our experience deploying the proposed Automatic Product Copywriting Generation (APCG) system into the JD.com e-commerce product recommendation platform. It consists of two main components: 1) natural language generation, which is built from a transformer-pointer network and a pre-trained sequence-to-sequence model based on millions of training data from our in-house platform; and 2) copywriting quality control, which is based on both automatic evaluation and human screening. For selected domains, the models are trained and updated daily with the updated training data. In addition, the model is also used as a real-time writing assistant tool on our live broadcast platform. The APCG system has been deployed in JD.com since Feb 2021. By Sep 2021, it has generated 2.53 million product descriptions, and improved the overall averaged click-through rate (CTR) and the Conversion Rate (CVR) by 4.22% and 3.61%, compared to baselines, respectively on a year-on-year basis. The accumulated Gross Merchandise Volume (GMV) made by our system is improved by 213.42%, compared to the number in Feb 2021.
DSGPT: Domain-Specific Generative Pre-Training of Transformers for Text Generation in E-commerce Title and Review Summarization
Dec 15, 2021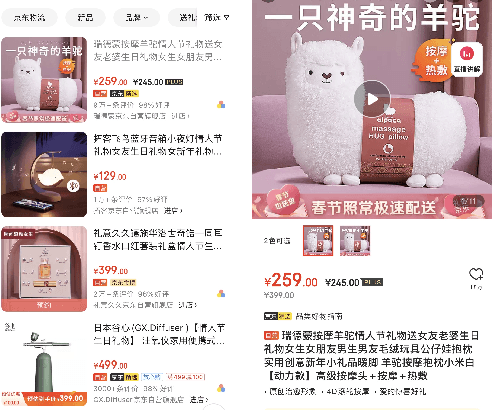
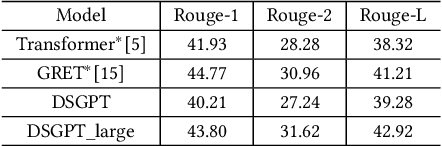
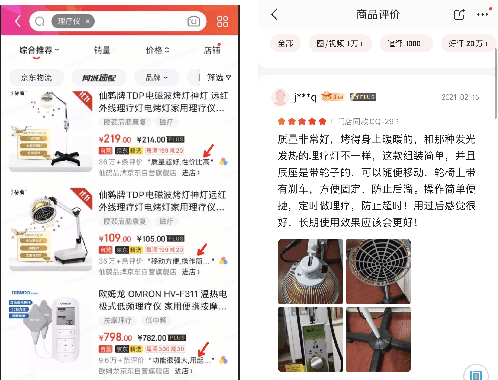
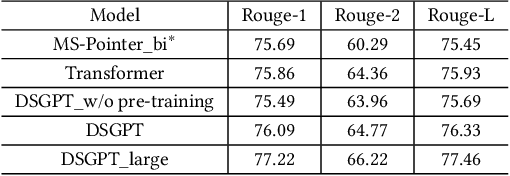
We propose a novel domain-specific generative pre-training (DS-GPT) method for text generation and apply it to the product titleand review summarization problems on E-commerce mobile display.First, we adopt a decoder-only transformer architecture, which fitswell for fine-tuning tasks by combining input and output all to-gether. Second, we demonstrate utilizing only small amount of pre-training data in related domains is powerful. Pre-training a languagemodel from a general corpus such as Wikipedia or the CommonCrawl requires tremendous time and resource commitment, andcan be wasteful if the downstream tasks are limited in variety. OurDSGPT is pre-trained on a limited dataset, the Chinese short textsummarization dataset (LCSTS). Third, our model does not requireproduct-related human-labeled data. For title summarization task,the state of art explicitly uses additional background knowledgein training and predicting stages. In contrast, our model implic-itly captures this knowledge and achieves significant improvementover other methods, after fine-tuning on the public Taobao.comdataset. For review summarization task, we utilize JD.com in-housedataset, and observe similar improvement over standard machinetranslation methods which lack the flexibility of fine-tuning. Ourproposed work can be simply extended to other domains for a widerange of text generation tasks.
A Feature Subset Selection Algorithm Automatic Recommendation Method
Feb 04, 2014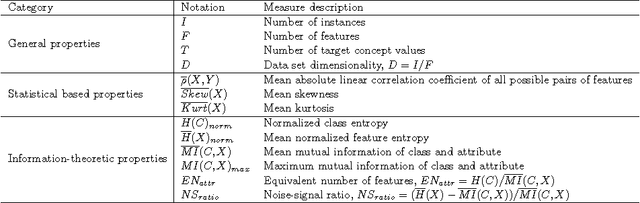
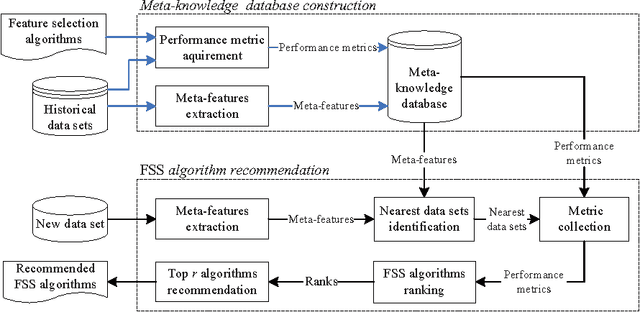
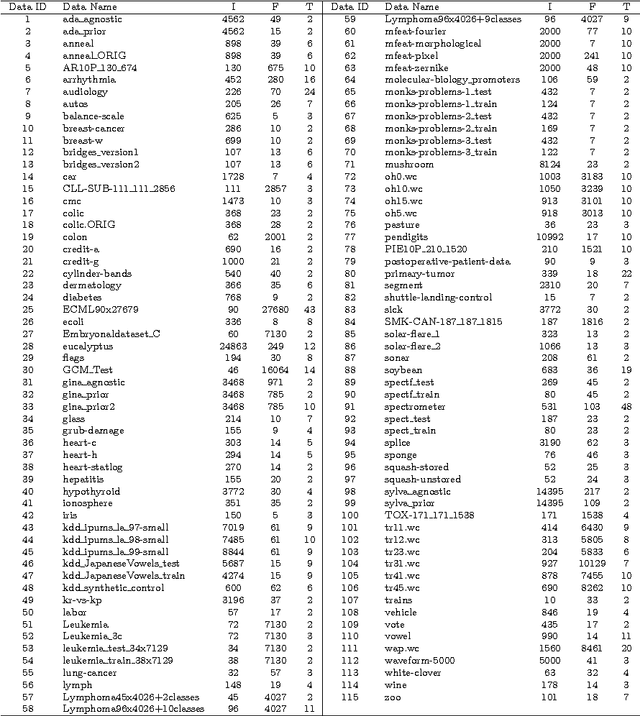
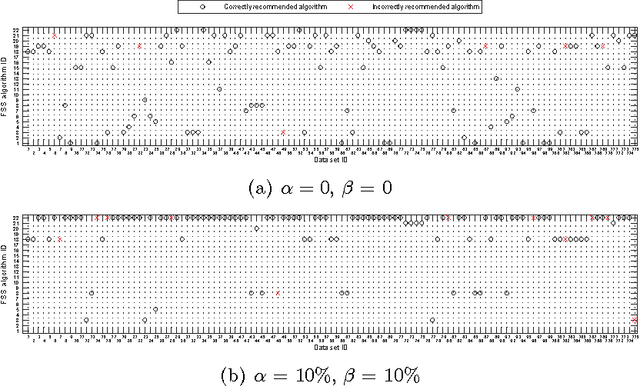
Many feature subset selection (FSS) algorithms have been proposed, but not all of them are appropriate for a given feature selection problem. At the same time, so far there is rarely a good way to choose appropriate FSS algorithms for the problem at hand. Thus, FSS algorithm automatic recommendation is very important and practically useful. In this paper, a meta learning based FSS algorithm automatic recommendation method is presented. The proposed method first identifies the data sets that are most similar to the one at hand by the k-nearest neighbor classification algorithm, and the distances among these data sets are calculated based on the commonly-used data set characteristics. Then, it ranks all the candidate FSS algorithms according to their performance on these similar data sets, and chooses the algorithms with best performance as the appropriate ones. The performance of the candidate FSS algorithms is evaluated by a multi-criteria metric that takes into account not only the classification accuracy over the selected features, but also the runtime of feature selection and the number of selected features. The proposed recommendation method is extensively tested on 115 real world data sets with 22 well-known and frequently-used different FSS algorithms for five representative classifiers. The results show the effectiveness of our proposed FSS algorithm recommendation method.