 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagCLIP: A Local-to-Global Framework to Enhance Open-Vocabulary Multi-Label Classification of CLIP Without Training
Dec 20, 2023

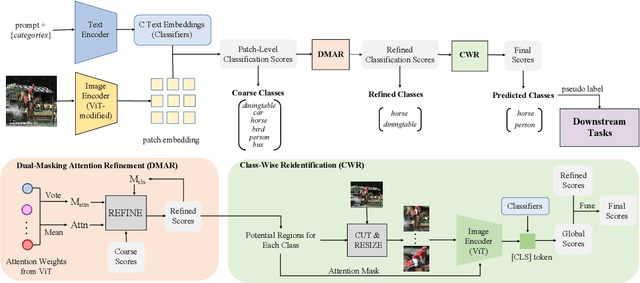
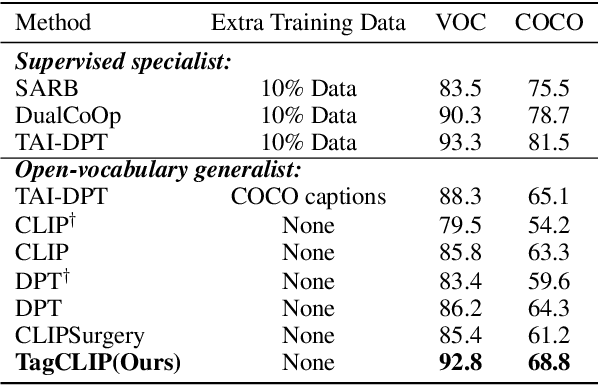
Contrastive Language-Image Pre-training (CLIP) has demonstrated impressive capabilities in open-vocabulary classification. The class token in the image encoder is trained to capture the global features to distinguish different text descriptions supervised by contrastive loss, making it highly effective for single-label classification. However, it shows poor performance on multi-label datasets because the global feature tends to be dominated by the most prominent class and the contrastive nature of softmax operation aggravates it. In this study, we observe that the multi-label classification results heavily rely on discriminative local features but are overlooked by CLIP. As a result, we dissect the preservation of patch-wise spatial information in CLIP and proposed a local-to-global framework to obtain image tags. It comprises three steps: (1) patch-level classification to obtain coarse scores; (2) dual-masking attention refinement (DMAR) module to refine the coarse scores; (3) class-wise reidentification (CWR) module to remedy predictions from a global perspective. This framework is solely based on frozen CLIP and significantly enhances its multi-label classification performance on various benchmarks without dataset-specific training. Besides, to comprehensively assess the quality and practicality of generated tags, we extend their application to the downstream task, i.e., weakly supervised semantic segmentation (WSSS) with generated tags as image-level pseudo labels. Experiments demonstrate that this classify-then-segment paradigm dramatically outperforms other annotation-free segmentation methods and validates the effectiveness of generated tags. Our code is available at https://github.com/linyq2117/TagCLIP.