 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent Temporal Relation Extraction based on Retrieval-Augmented on LLMs
Mar 22, 2024

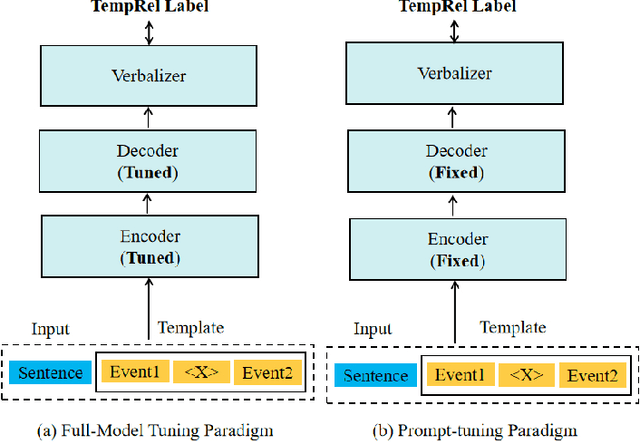

Event temporal relation (TempRel) is a primary subject of the event relation extraction task. However, the inherent ambiguity of TempRel increases the difficulty of the task. With the rise of prompt engineering, it is important to design effective prompt templates and verbalizers to extract relevant knowledge. The traditional manually designed templates struggle to extract precise temporal knowledge. This paper introduces a novel retrieval-augmented TempRel extraction approach, leveraging knowledge retrieved from large language models (LLMs) to enhance prompt templates and verbalizers. Our method capitalizes on the diverse capabilities of various LLMs to generate a wide array of ideas for template and verbalizer design. Our proposed method fully exploits the potential of LLMs for generation tasks and contributes more knowledge to our design. Empirical evaluations across three widely recognized datasets demonstrate the efficacy of our method in improving the performance of event temporal relation extraction tasks.
Text Smoothing: Enhance Various Data Augmentation Methods on Text Classification Tasks
Feb 28, 2022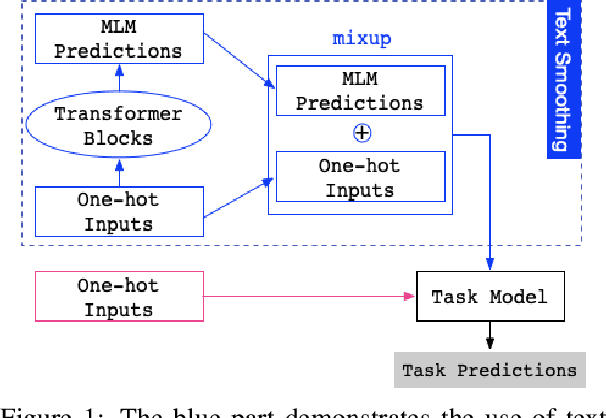
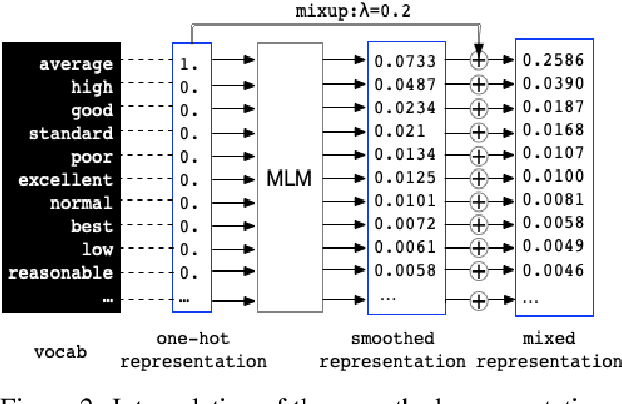
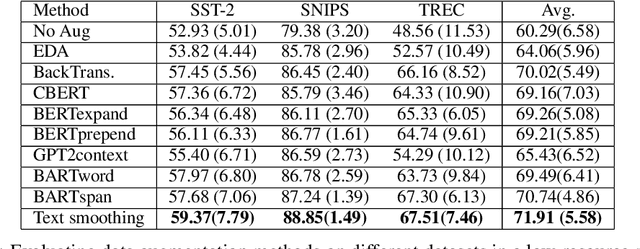
Before entering the neural network, a token is generally converted to the corresponding one-hot representation, which is a discrete distribution of the vocabulary. Smoothed representation is the probability of candidate tokens obtained from a pre-trained masked language model, which can be seen as a more informative substitution to the one-hot representation. We propose an efficient data augmentation method, termed text smoothing, by converting a sentence from its one-hot representation to a controllable smoothed representation. We evaluate text smoothing on different benchmarks in a low-resource regime. Experimental results show that text smoothing outperforms various mainstream data augmentation methods by a substantial margin. Moreover, text smoothing can be combined with those data augmentation methods to achieve better performance.
DisCo: Effective Knowledge Distillation For Contrastive Learning of Sentence Embeddings
Dec 10, 2021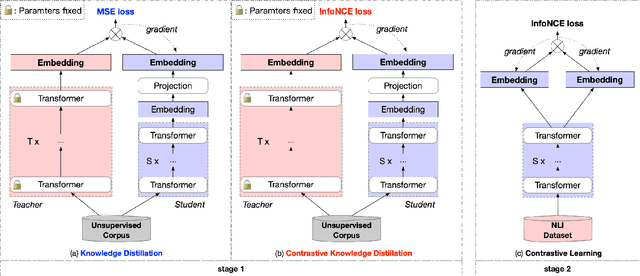
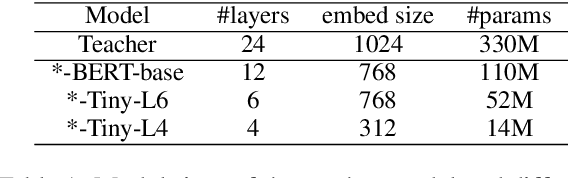
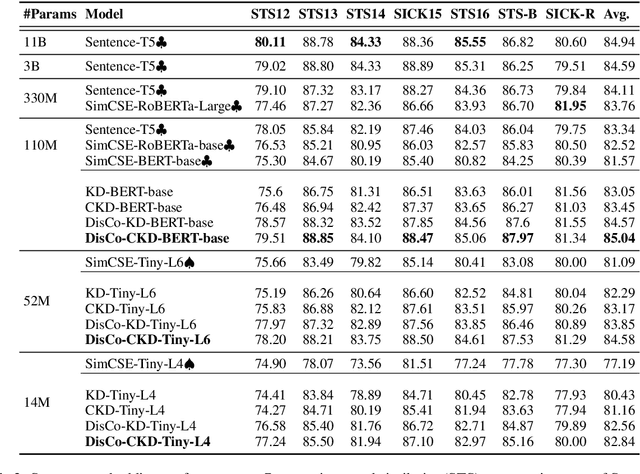

Contrastive learning has been proven suitable for learning sentence embeddings and can significantly improve the semantic textual similarity (STS) tasks. Recently, large contrastive learning models, e.g., Sentence-T5, tend to be proposed to learn more powerful sentence embeddings. Though effective, such large models are hard to serve online due to computational resources or time cost limits. To tackle that, knowledge distillation (KD) is commonly adopted, which can compress a large "teacher" model into a small "student" model but generally suffer from some performance loss. Here we propose an enhanced KD framework termed Distill-Contrast (DisCo). The proposed DisCo framework firstly utilizes KD to transfer the capability of a large sentence embedding model to a small student model on large unlabelled data, and then finetunes the student model with contrastive learning on labelled training data. For the KD process in DisCo, we further propose Contrastive Knowledge Distillation (CKD) to enhance the consistencies among teacher model training, KD, and student model finetuning, which can probably improve performance like prompt learning. Extensive experiments on 7 STS benchmarks show that student models trained with the proposed DisCo and CKD suffer from little or even no performance loss and consistently outperform the corresponding counterparts of the same parameter size. Amazingly, our 110M student model can even outperform the latest state-of-the-art (SOTA) model, i.e., Sentence-T5(11B), with only 1% parameters.
ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
Sep 09, 2021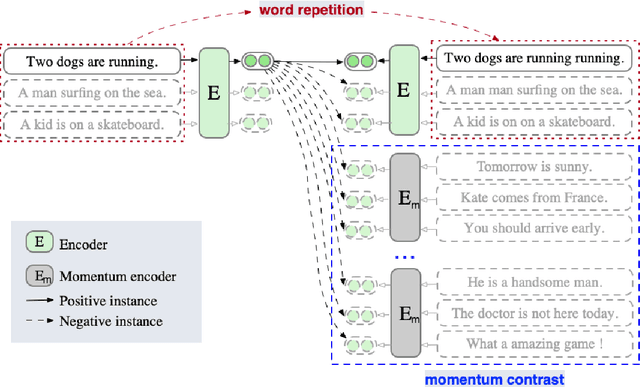
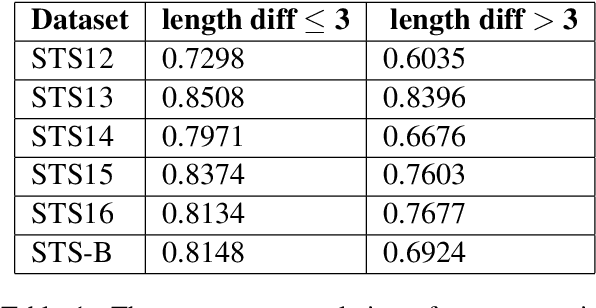
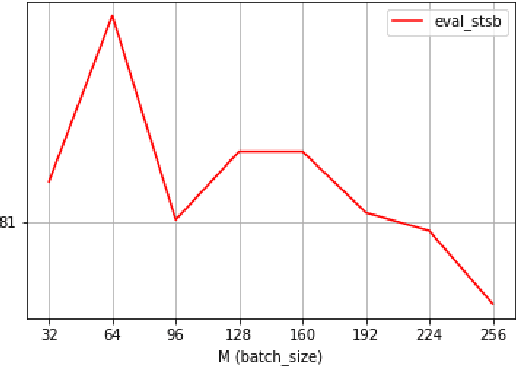

Contrastive learning has been attracting much attention for learning unsupervised sentence embeddings. The current state-of-the-art unsupervised method is the unsupervised SimCSE (unsup-SimCSE). Unsup-SimCSE takes dropout as a minimal data augmentation method, and passes the same input sentence to a pre-trained Transformer encoder (with dropout turned on) twice to obtain the two corresponding embeddings to build a positive pair. As the length information of a sentence will generally be encoded into the sentence embeddings due to the usage of position embedding in Transformer, each positive pair in unsup-SimCSE actually contains the same length information. And thus unsup-SimCSE trained with these positive pairs is probably biased, which would tend to consider that sentences of the same or similar length are more similar in semantics. Through statistical observations, we find that unsup-SimCSE does have such a problem. To alleviate it, we apply a simple repetition operation to modify the input sentence, and then pass the input sentence and its modified counterpart to the pre-trained Transformer encoder, respectively, to get the positive pair. Additionally, we draw inspiration from the community of computer vision and introduce a momentum contrast, enlarging the number of negative pairs without additional calculations. The proposed two modifications are applied on positive and negative pairs separately, and build a new sentence embedding method, termed Enhanced Unsup-SimCSE (ESimCSE). We evaluate the proposed ESimCSE on several benchmark datasets w.r.t the semantic text similarity (STS) task. Experimental results show that ESimCSE outperforms the state-of-the-art unsup-SimCSE by an average Spearman correlation of 2.02% on BERT-base.
Smoothed Contrastive Learning for Unsupervised Sentence Embedding
Sep 09, 2021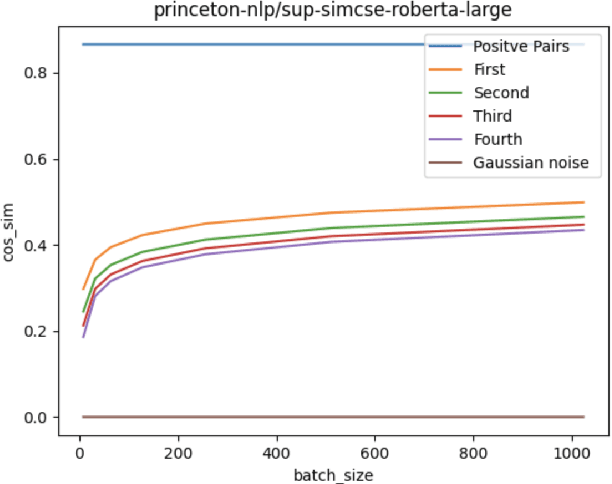
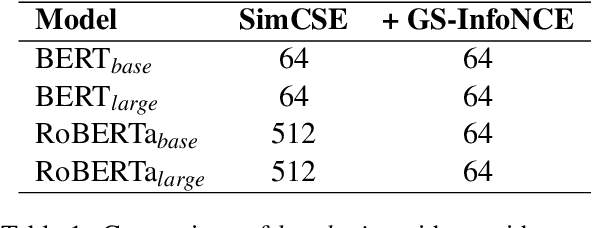
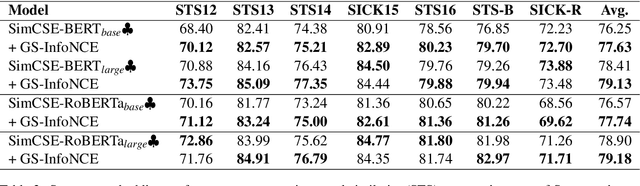
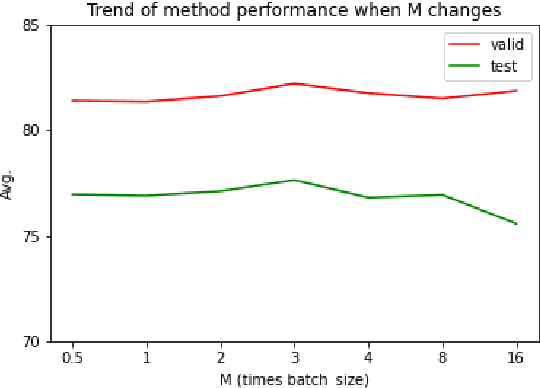
Contrastive learning has been gradually applied to learn high-quality unsupervised sentence embedding. Among the previous un-supervised methods, the latest state-of-the-art method, as far as we know, is unsupervised SimCSE (unsup-SimCSE). Unsup-SimCSE uses the InfoNCE1loss function in the training stage by pulling semantically similar sentences together and pushing apart dis-similar ones.Theoretically, we expect to use larger batches in unsup-SimCSE to get more adequate comparisons among samples and avoid overfitting. However, increasing the batch size does not always lead to improvements, but instead even lead to performance degradation when the batch size exceeds a threshold. Through statistical observation, we find that this is probably due to the introduction of low-confidence negative pairs after in-creasing the batch size. To alleviate this problem, we introduce a simple smoothing strategy upon the InfoNCE loss function, termedGaussian Smoothing InfoNCE (GS-InfoNCE).Specifically, we add random Gaussian noise vectors as negative samples, which act asa smoothing of the negative sample space.Though being simple, the proposed smooth-ing strategy brings substantial improvements to unsup-SimCSE. We evaluate GS-InfoNCEon the standard semantic text similarity (STS)task. GS-InfoNCE outperforms the state-of-the-art unsup-SimCSE by an average Spear-man correlation of 1.38%, 0.72%, 1.17% and0.28% on the base of BERT-base, BERT-large,RoBERTa-base and RoBERTa-large, respectively.
AutoSUM: Automating Feature Extraction and Multi-user Preference Simulation for Entity Summarization
May 25, 2020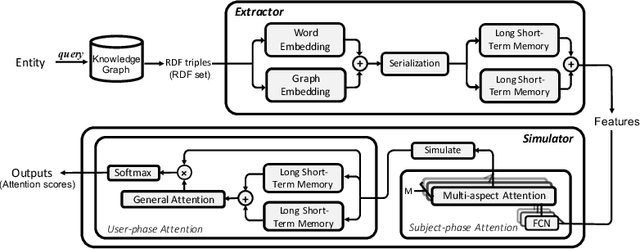
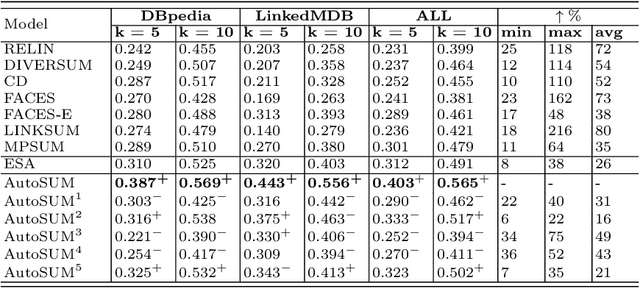
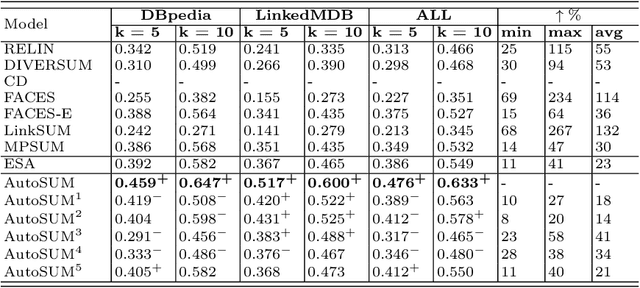
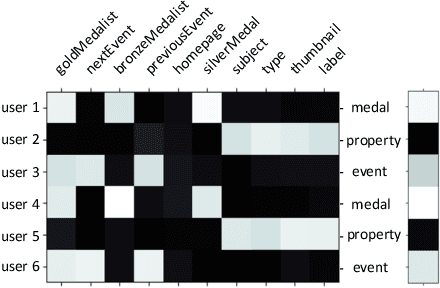
Withthegrowthofknowledgegraphs, entity descriptions are becoming extremely lengthy. Entity summarization task, aiming to generate diverse, comprehensive, and representative summaries for entities, has received increasing interest recently. In most previous methods, features are usually extracted by the handcrafted templates. Then the feature selection and multi-user preference simulation take place, depending too much on human expertise. In this paper, a novel integration method called AutoSUM is proposed for automatic feature extraction and multi-user preference simulation to overcome the drawbacks of previous methods. There are two modules in AutoSUM: extractor and simulator. The extractor module operates automatic feature extraction based on a BiLSTM with a combined input representation including word embeddings and graph embeddings. Meanwhile, the simulator module automates multi-user preference simulation based on a well-designed two-phase attention mechanism (i.e., entity-phase attention and user-phase attention). Experimental results demonstrate that AutoSUM produces state-of-the-art performance on two widely used datasets (i.e., DBpedia and LinkedMDB) in both F-measure and MAP.
Data Augmentation for Copy-Mechanism in Dialogue State Tracking
Feb 22, 2020
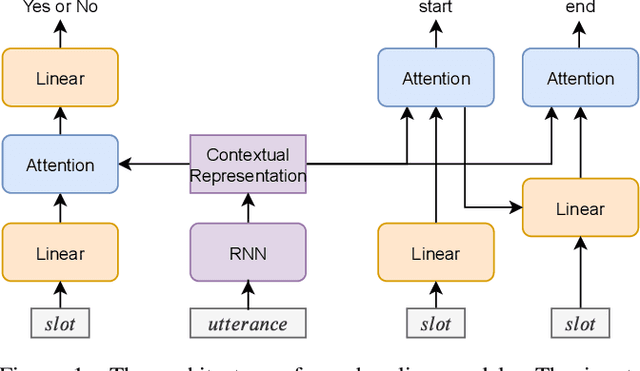
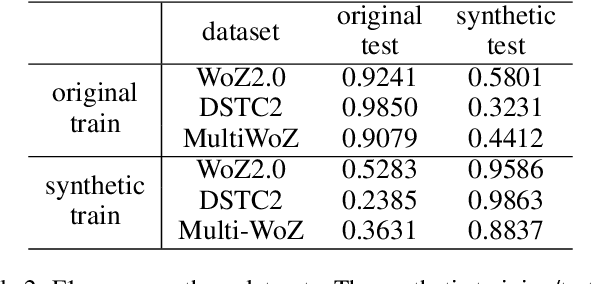
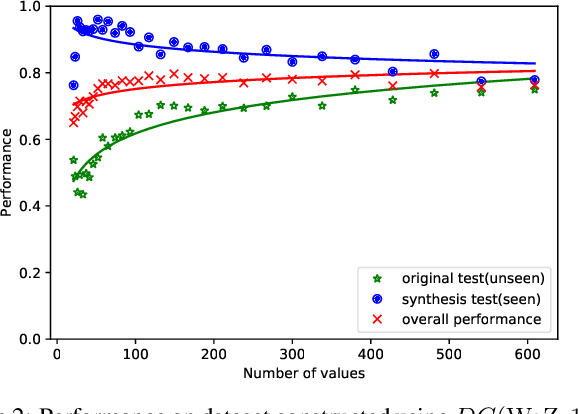
While several state-of-the-art approaches to dialogue state tracking (DST) have shown promising performances on several benchmarks, there is still a significant performance gap between seen slot values (i.e., values that occur in both training set and test set) and unseen ones (values that occur in training set but not in test set). Recently, the copy-mechanism has been widely used in DST models to handle unseen slot values, which copies slot values from user utterance directly. In this paper, we aim to find out the factors that influence the generalization ability of a common copy-mechanism model for DST. Our key observations include: 1) the copy-mechanism tends to memorize values rather than infer them from contexts, which is the primary reason for unsatisfactory generalization performance; 2) greater diversity of slot values in the training set increase the performance on unseen values but slightly decrease the performance on seen values. Moreover, we propose a simple but effective algorithm of data augmentation to train copy-mechanism models, which augments the input dataset by copying user utterances and replacing the real slot values with randomly generated strings. Users could use two hyper-parameters to realize a trade-off between the performances on seen values and unseen ones, as well as a trade-off between overall performance and computational cost. Experimental results on three widely used datasets (WoZ 2.0, DSTC2, and Multi-WoZ 2.0) show the effectiveness of our approach.
TransSent: Towards Generation of Structured Sentences with Discourse Marker
Sep 05, 2019



This paper focuses on the task of generating long structured sentences with explicit discourse markers, by proposing a new task Sentence Transfer and a novel model architecture TransSent. Previous works on text generation fused semantic and structure information in one mixed hidden representation. However, the structure was difficult to maintain properly when the generated sentence became longer. In this work, we explicitly separate the modeling process of semantic information and structure information. Intuitively, humans produce long sentences by directly connecting discourses with discourse markers like and, but, etc. We thus define a new task called Sentence Transfer. This task represents a long sentence as (head discourse, discourse marker, tail discourse) and aims at tail discourse generation based on head discourse and discourse marker. Then, by connecting original head discourse and generated tail discourse with a discourse marker, we generate a long structured sentence. We also propose a model architecture called TransSent, which models relations between two discourses by interpreting them as transferring from one discourse to the other in the embedding space. Experiment results show that our model achieves better performance in automatic evaluations, and can generate structured sentences with high quality. The datasets can be accessed by https://github.com/1024er/TransSent dataset.
"Mask and Infill" : Applying Masked Language Model to Sentiment Transfer
Aug 21, 2019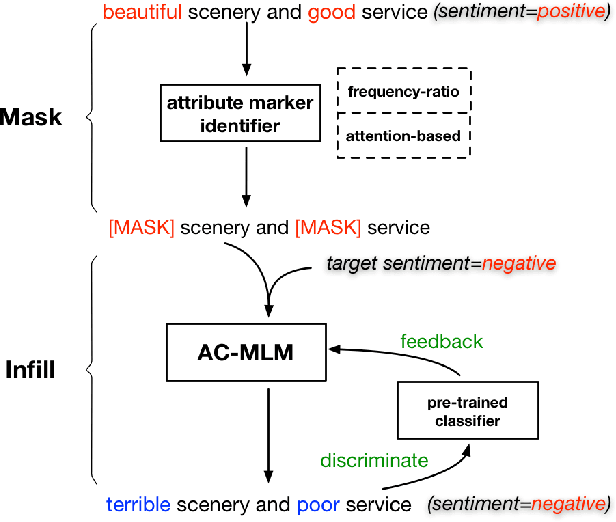
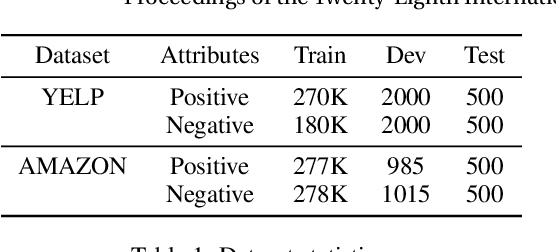
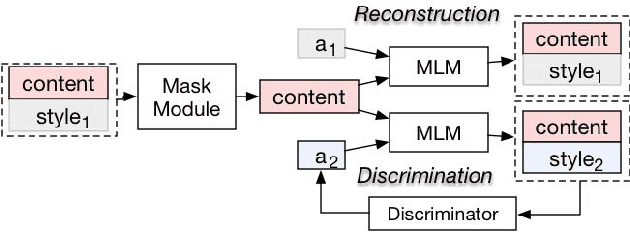
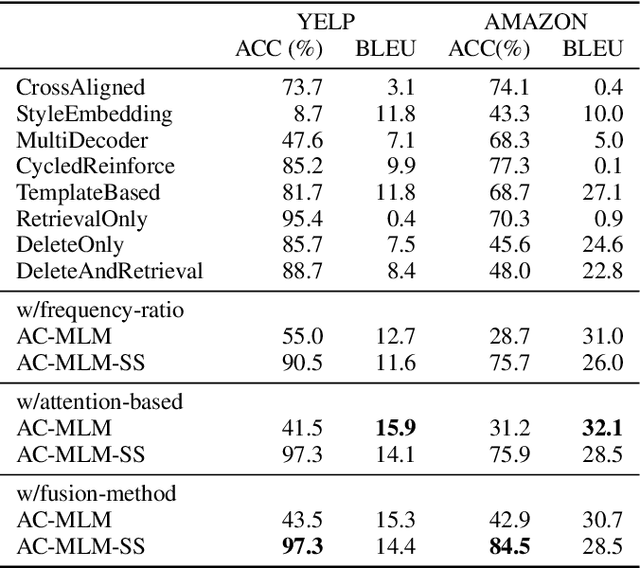
This paper focuses on the task of sentiment transfer on non-parallel text, which modifies sentiment attributes (e.g., positive or negative) of sentences while preserving their attribute-independent content. Due to the limited capability of RNNbased encoder-decoder structure to capture deep and long-range dependencies among words, previous works can hardly generate satisfactory sentences from scratch. When humans convert the sentiment attribute of a sentence, a simple but effective approach is to only replace the original sentimental tokens in the sentence with target sentimental expressions, instead of building a new sentence from scratch. Such a process is very similar to the task of Text Infilling or Cloze, which could be handled by a deep bidirectional Masked Language Model (e.g. BERT). So we propose a two step approach "Mask and Infill". In the mask step, we separate style from content by masking the positions of sentimental tokens. In the infill step, we retrofit MLM to Attribute Conditional MLM, to infill the masked positions by predicting words or phrases conditioned on the context1 and target sentiment. We evaluate our model on two review datasets with quantitative, qualitative, and human evaluations. Experimental results demonstrate that our models improve state-of-the-art performance.
Conditional BERT Contextual Augmentation
Dec 17, 2018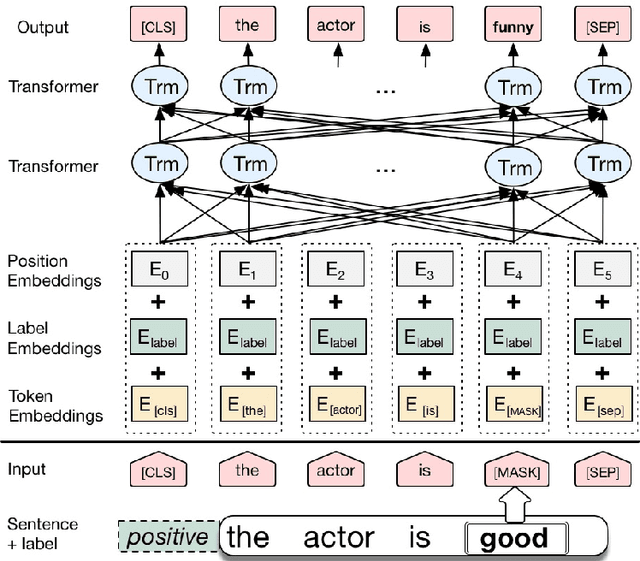
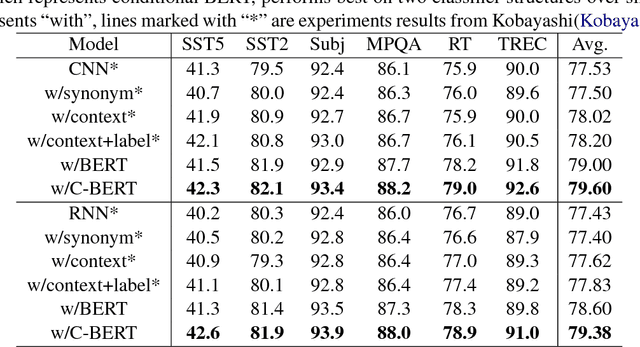

We propose a novel data augmentation method for labeled sentences called conditional BERT contextual augmentation. Data augmentation methods are often applied to prevent overfitting and improve generalization of deep neural network models. Recently proposed contextual augmentation augments labeled sentences by randomly replacing words with more varied substitutions predicted by language model. BERT demonstrates that a deep bidirectional language model is more powerful than either an unidirectional language model or the shallow concatenation of a forward and backward model. We retrofit BERT to conditional BERT by introducing a new conditional masked language model\footnote{The term "conditional masked language model" appeared once in original BERT paper, which indicates context-conditional, is equivalent to term "masked language model". In our paper, "conditional masked language model" indicates we apply extra label-conditional constraint to the "masked language model".} task. The well trained conditional BERT can be applied to enhance contextual augmentation. Experiments on six various different text classification tasks show that our method can be easily applied to both convolutional or recurrent neural networks classifier to obtain obvious improvement.