 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisCo: Effective Knowledge Distillation For Contrastive Learning of Sentence Embeddings
Paper and Code
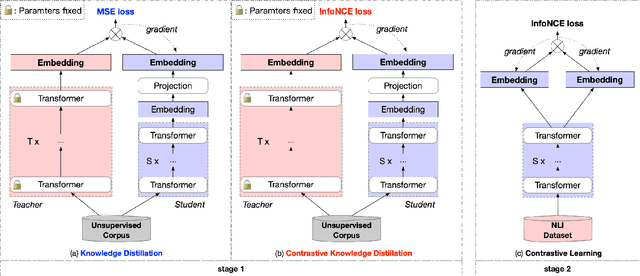
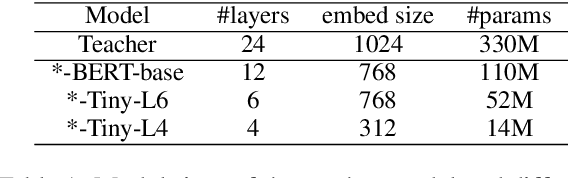
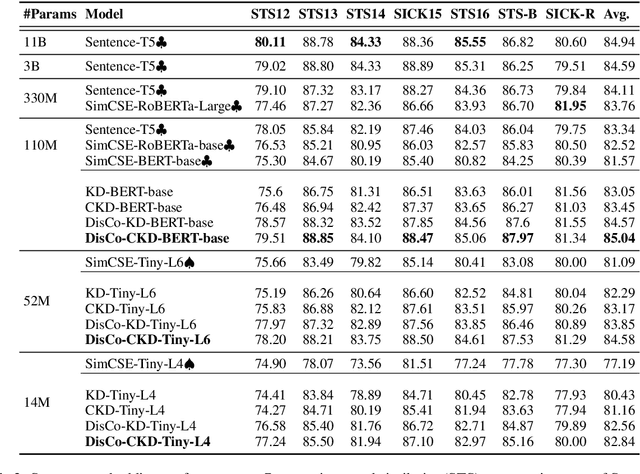

Contrastive learning has been proven suitable for learning sentence embeddings and can significantly improve the semantic textual similarity (STS) tasks. Recently, large contrastive learning models, e.g., Sentence-T5, tend to be proposed to learn more powerful sentence embeddings. Though effective, such large models are hard to serve online due to computational resources or time cost limits. To tackle that, knowledge distillation (KD) is commonly adopted, which can compress a large "teacher" model into a small "student" model but generally suffer from some performance loss. Here we propose an enhanced KD framework termed Distill-Contrast (DisCo). The proposed DisCo framework firstly utilizes KD to transfer the capability of a large sentence embedding model to a small student model on large unlabelled data, and then finetunes the student model with contrastive learning on labelled training data. For the KD process in DisCo, we further propose Contrastive Knowledge Distillation (CKD) to enhance the consistencies among teacher model training, KD, and student model finetuning, which can probably improve performance like prompt learning. Extensive experiments on 7 STS benchmarks show that student models trained with the proposed DisCo and CKD suffer from little or even no performance loss and consistently outperform the corresponding counterparts of the same parameter size. Amazingly, our 110M student model can even outperform the latest state-of-the-art (SOTA) model, i.e., Sentence-T5(11B), with only 1% parameters.