 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongBench Pro: A More Realistic and Comprehensive Bilingual Long-Context Evaluation Benchmark
Jan 06, 2026The rapid expansion of context length in large language models (LLMs) has outpaced existing evaluation benchmarks. Current long-context benchmarks often trade off scalability and realism: synthetic tasks underrepresent real-world complexity, while fully manual annotation is costly to scale to extreme lengths and diverse scenarios. We present LongBench Pro, a more realistic and comprehensive bilingual benchmark of 1,500 naturally occurring long-context samples in English and Chinese spanning 11 primary tasks and 25 secondary tasks, with input lengths from 8k to 256k tokens. LongBench Pro supports fine-grained analysis with task-specific metrics and a multi-dimensional taxonomy of context requirement (full vs. partial dependency), length (six levels), and difficulty (four levels calibrated by model performance). To balance quality with scalability, we propose a Human-Model Collaborative Construction pipeline: frontier LLMs draft challenging questions and reference answers, along with design rationales and solution processes, to reduce the cost of expert verification. Experts then rigorously validate correctness and refine problematic cases. Evaluating 46 widely used long-context LLMs on LongBench Pro yields three findings: (1) long-context optimization contributes more to long-context comprehension than parameter scaling; (2) effective context length is typically shorter than the claimed context length, with pronounced cross-lingual misalignment; and (3) the "thinking" paradigm helps primarily models trained with native reasoning, while mixed-thinking designs offer a promising Pareto trade-off. In summary, LongBench Pro provides a robust testbed for advancing long-context understanding.
LiteLong: Resource-Efficient Long-Context Data Synthesis for LLMs
Sep 19, 2025
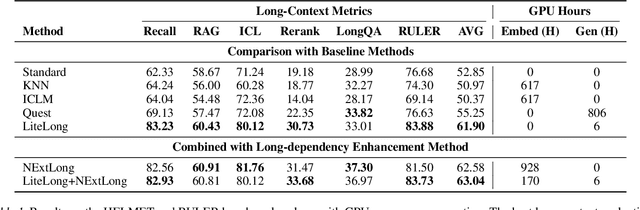


High-quality long-context data is essential for training large language models (LLMs) capable of processing extensive documents, yet existing synthesis approaches using relevance-based aggregation face challenges of computational efficiency. We present LiteLong, a resource-efficient method for synthesizing long-context data through structured topic organization and multi-agent debate. Our approach leverages the BISAC book classification system to provide a comprehensive hierarchical topic organization, and then employs a debate mechanism with multiple LLMs to generate diverse, high-quality topics within this structure. For each topic, we use lightweight BM25 retrieval to obtain relevant documents and concatenate them into 128K-token training samples. Experiments on HELMET and Ruler benchmarks demonstrate that LiteLong achieves competitive long-context performance and can seamlessly integrate with other long-dependency enhancement methods. LiteLong makes high-quality long-context data synthesis more accessible by reducing both computational and data engineering costs, facilitating further research in long-context language training.
LongMagpie: A Self-synthesis Method for Generating Large-scale Long-context Instructions
May 22, 2025High-quality long-context instruction data is essential for aligning long-context large language models (LLMs). Despite the public release of models like Qwen and Llama, their long-context instruction data remains proprietary. Human annotation is costly and challenging, while template-based synthesis methods limit scale, diversity, and quality. We introduce LongMagpie, a self-synthesis framework that automatically generates large-scale long-context instruction data. Our key insight is that aligned long-context LLMs, when presented with a document followed by special tokens preceding a user turn, auto-regressively generate contextually relevant queries. By harvesting these document-query pairs and the model's responses, LongMagpie produces high-quality instructions without human effort. Experiments on HELMET, RULER, and Longbench v2 demonstrate that LongMagpie achieves leading performance on long-context tasks while maintaining competitive performance on short-context tasks, establishing it as a simple and effective approach for open, diverse, and scalable long-context instruction data synthesis.
Quest: Query-centric Data Synthesis Approach for Long-context Scaling of Large Language Model
May 30, 2024



Large language models, initially pre-trained with a limited context length, can better handle longer texts by continuing training on a corpus with extended contexts. However, obtaining effective long-context data is challenging due to the scarcity and uneven distribution of long documents across different domains. To address this issue, we propose a Query-centric data synthesis method, abbreviated as Quest. Quest is an interpretable method based on the observation that documents retrieved by similar queries are relevant but low-redundant, thus well-suited for synthesizing long-context data. The method is also scalable and capable of constructing large amounts of long-context data. Using Quest, we synthesize a long-context dataset up to 128k context length, significantly outperforming other data synthesis methods on multiple long-context benchmark datasets. In addition, we further verify that the Quest method is predictable through scaling law experiments, making it a reliable solution for advancing long-context models.
RaP: Redundancy-aware Video-language Pre-training for Text-Video Retrieval
Oct 13, 2022
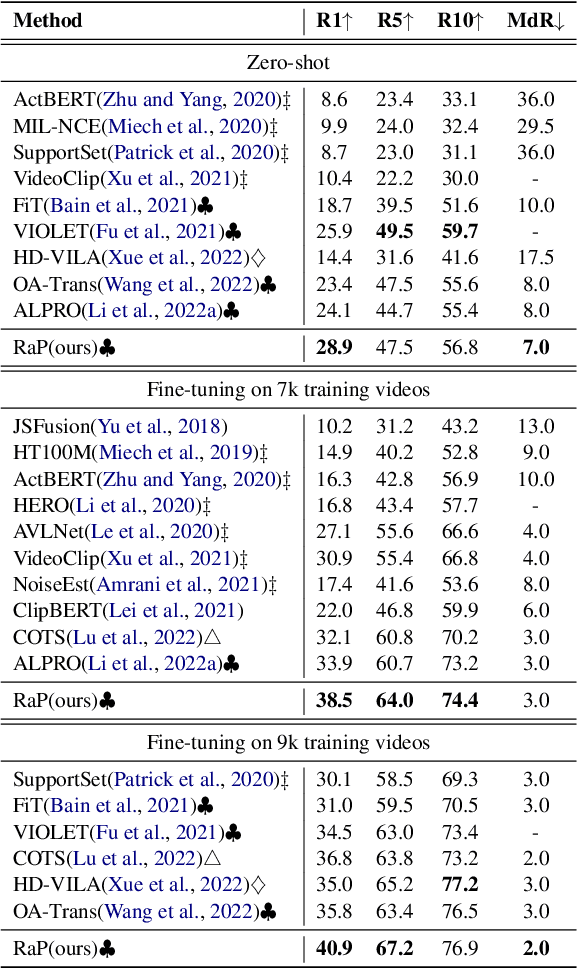
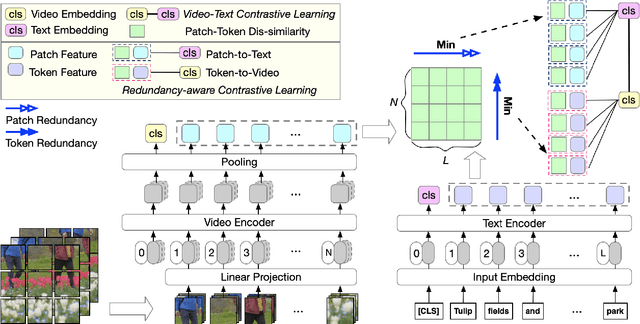
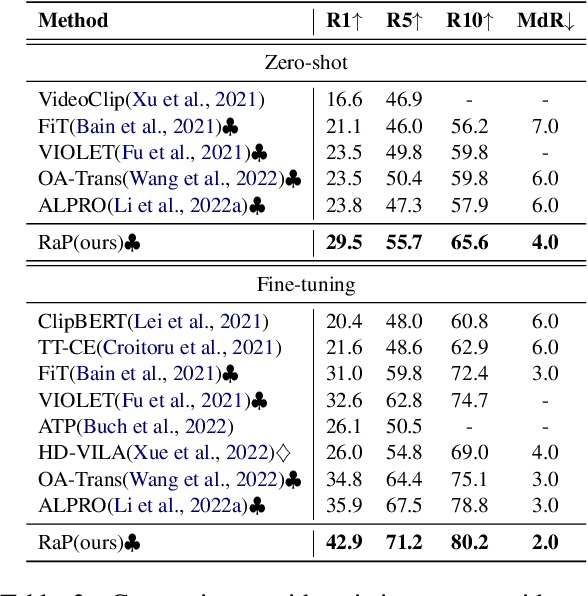
Video language pre-training methods have mainly adopted sparse sampling techniques to alleviate the temporal redundancy of videos. Though effective, sparse sampling still suffers inter-modal redundancy: visual redundancy and textual redundancy. Compared with highly generalized text, sparsely sampled frames usually contain text-independent portions, called visual redundancy. Sparse sampling is also likely to miss important frames corresponding to some text portions, resulting in textual redundancy. Inter-modal redundancy leads to a mismatch of video and text information, hindering the model from better learning the shared semantics across modalities. To alleviate it, we propose Redundancy-aware Video-language Pre-training. We design a redundancy measurement of video patches and text tokens by calculating the cross-modal minimum dis-similarity. Then, we penalize the highredundant video patches and text tokens through a proposed redundancy-aware contrastive learning. We evaluate our method on four benchmark datasets, MSRVTT, MSVD, DiDeMo, and LSMDC, achieving a significant improvement over the previous stateof-the-art results. Our code are available at https://github.com/caskcsg/VLP/tree/main/RaP.
InfoCSE: Information-aggregated Contrastive Learning of Sentence Embeddings
Oct 08, 2022
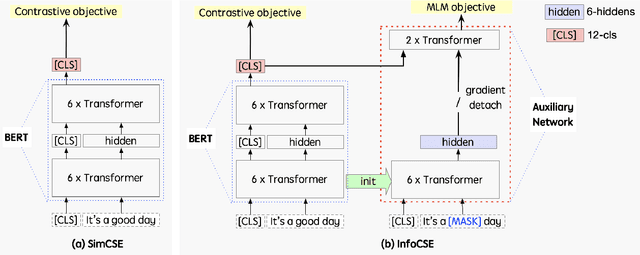
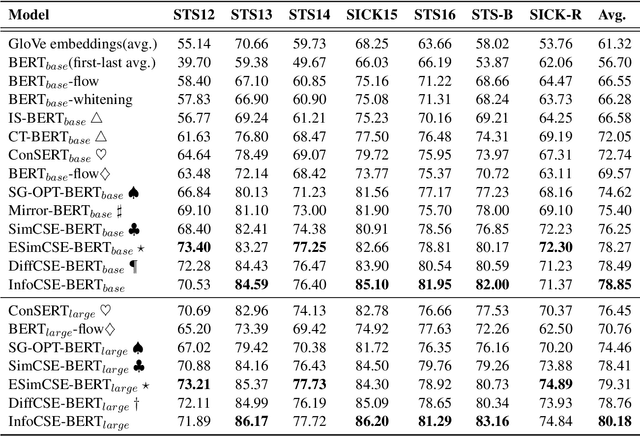
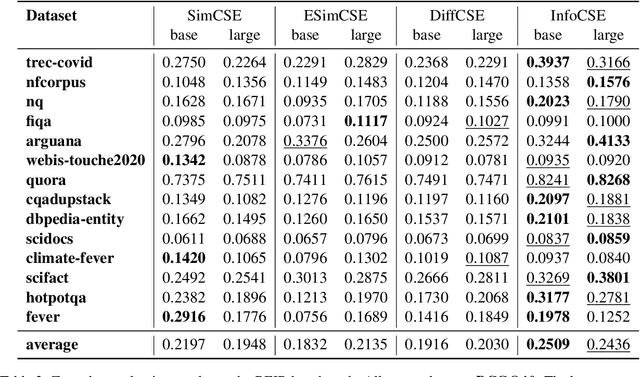
Contrastive learning has been extensively studied in sentence embedding learning, which assumes that the embeddings of different views of the same sentence are closer. The constraint brought by this assumption is weak, and a good sentence representation should also be able to reconstruct the original sentence fragments. Therefore, this paper proposes an information-aggregated contrastive learning framework for learning unsupervised sentence embeddings, termed InfoCSE. InfoCSE forces the representation of [CLS] positions to aggregate denser sentence information by introducing an additional Masked language model task and a well-designed network. We evaluate the proposed InfoCSE on several benchmark datasets w.r.t the semantic text similarity (STS) task. Experimental results show that InfoCSE outperforms SimCSE by an average Spearman correlation of 2.60% on BERT-base, and 1.77% on BERT-large, achieving state-of-the-art results among unsupervised sentence representation learning methods. Our code are available at https://github.com/caskcsg/sentemb/info
Text Smoothing: Enhance Various Data Augmentation Methods on Text Classification Tasks
Feb 28, 2022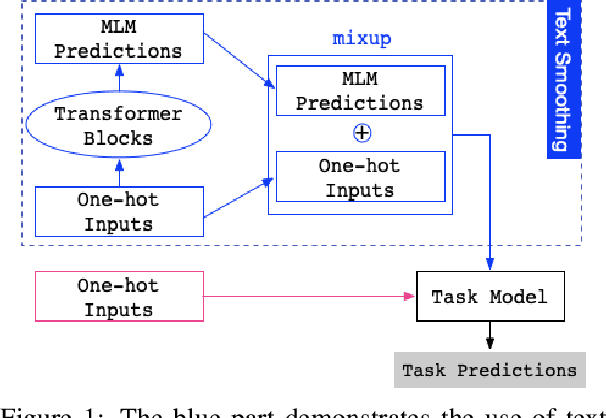
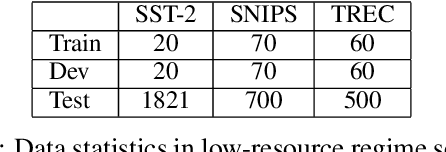
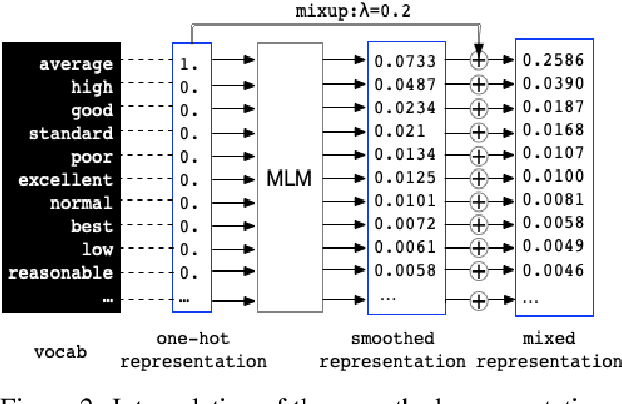
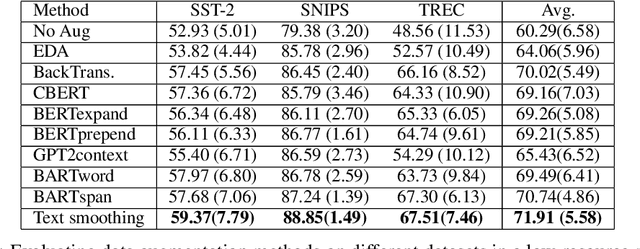
Before entering the neural network, a token is generally converted to the corresponding one-hot representation, which is a discrete distribution of the vocabulary. Smoothed representation is the probability of candidate tokens obtained from a pre-trained masked language model, which can be seen as a more informative substitution to the one-hot representation. We propose an efficient data augmentation method, termed text smoothing, by converting a sentence from its one-hot representation to a controllable smoothed representation. We evaluate text smoothing on different benchmarks in a low-resource regime. Experimental results show that text smoothing outperforms various mainstream data augmentation methods by a substantial margin. Moreover, text smoothing can be combined with those data augmentation methods to achieve better performance.
DisCo: Effective Knowledge Distillation For Contrastive Learning of Sentence Embeddings
Dec 10, 2021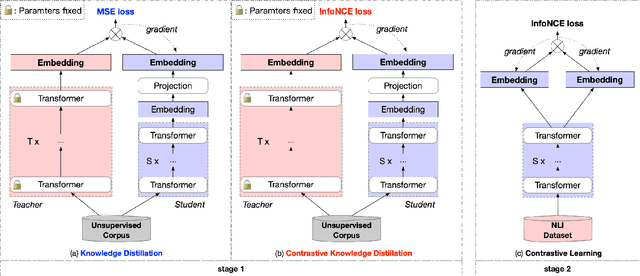
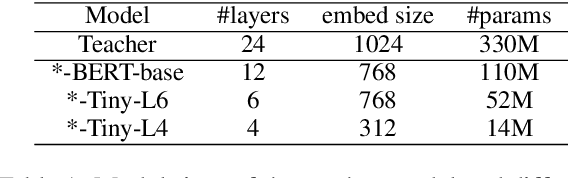
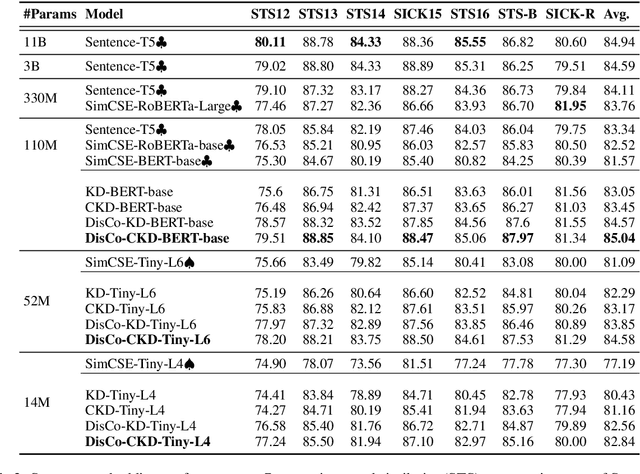

Contrastive learning has been proven suitable for learning sentence embeddings and can significantly improve the semantic textual similarity (STS) tasks. Recently, large contrastive learning models, e.g., Sentence-T5, tend to be proposed to learn more powerful sentence embeddings. Though effective, such large models are hard to serve online due to computational resources or time cost limits. To tackle that, knowledge distillation (KD) is commonly adopted, which can compress a large "teacher" model into a small "student" model but generally suffer from some performance loss. Here we propose an enhanced KD framework termed Distill-Contrast (DisCo). The proposed DisCo framework firstly utilizes KD to transfer the capability of a large sentence embedding model to a small student model on large unlabelled data, and then finetunes the student model with contrastive learning on labelled training data. For the KD process in DisCo, we further propose Contrastive Knowledge Distillation (CKD) to enhance the consistencies among teacher model training, KD, and student model finetuning, which can probably improve performance like prompt learning. Extensive experiments on 7 STS benchmarks show that student models trained with the proposed DisCo and CKD suffer from little or even no performance loss and consistently outperform the corresponding counterparts of the same parameter size. Amazingly, our 110M student model can even outperform the latest state-of-the-art (SOTA) model, i.e., Sentence-T5(11B), with only 1% parameters.
TransAug: Translate as Augmentation for Sentence Embeddings
Oct 30, 2021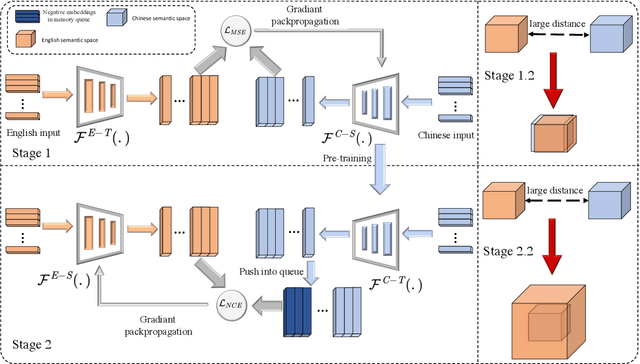

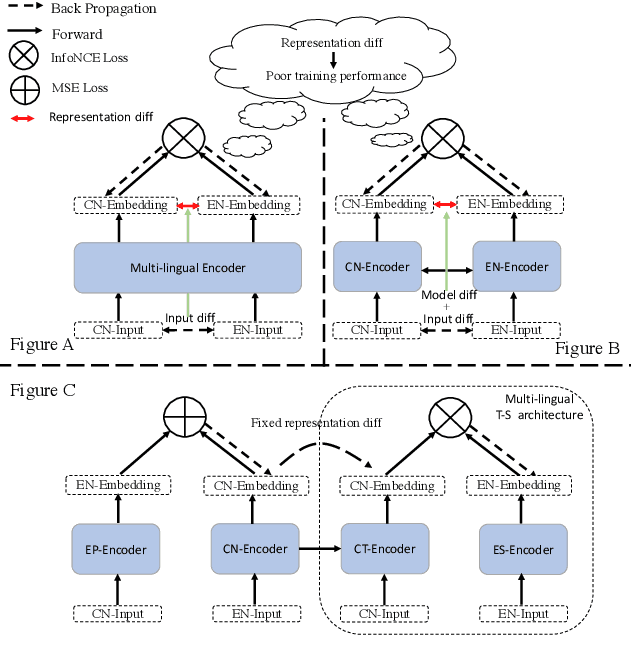

While contrastive learning greatly advances the representation of sentence embeddings, it is still limited by the size of the existing sentence datasets. In this paper, we present TransAug (Translate as Augmentation), which provide the first exploration of utilizing translated sentence pairs as data augmentation for text, and introduce a two-stage paradigm to advances the state-of-the-art sentence embeddings. Instead of adopting an encoder trained in other languages setting, we first distill a Chinese encoder from a SimCSE encoder (pretrained in English), so that their embeddings are close in semantic space, which can be regraded as implicit data augmentation. Then, we only update the English encoder via cross-lingual contrastive learning and frozen the distilled Chinese encoder. Our approach achieves a new state-of-art on standard semantic textual similarity (STS), outperforming both SimCSE and Sentence-T5, and the best performance in corresponding tracks on transfer tasks evaluated by SentEval.
ESimCSE: Enhanced Sample Building Method for Contrastive Learning of Unsupervised Sentence Embedding
Sep 09, 2021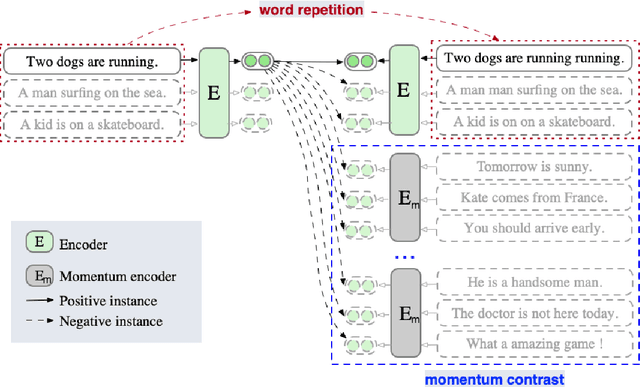
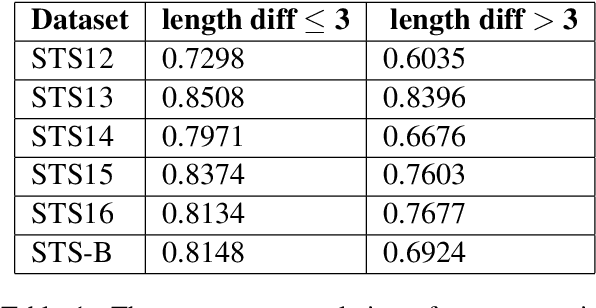
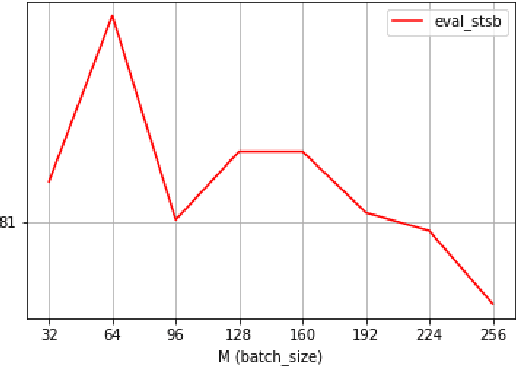

Contrastive learning has been attracting much attention for learning unsupervised sentence embeddings. The current state-of-the-art unsupervised method is the unsupervised SimCSE (unsup-SimCSE). Unsup-SimCSE takes dropout as a minimal data augmentation method, and passes the same input sentence to a pre-trained Transformer encoder (with dropout turned on) twice to obtain the two corresponding embeddings to build a positive pair. As the length information of a sentence will generally be encoded into the sentence embeddings due to the usage of position embedding in Transformer, each positive pair in unsup-SimCSE actually contains the same length information. And thus unsup-SimCSE trained with these positive pairs is probably biased, which would tend to consider that sentences of the same or similar length are more similar in semantics. Through statistical observations, we find that unsup-SimCSE does have such a problem. To alleviate it, we apply a simple repetition operation to modify the input sentence, and then pass the input sentence and its modified counterpart to the pre-trained Transformer encoder, respectively, to get the positive pair. Additionally, we draw inspiration from the community of computer vision and introduce a momentum contrast, enlarging the number of negative pairs without additional calculations. The proposed two modifications are applied on positive and negative pairs separately, and build a new sentence embedding method, termed Enhanced Unsup-SimCSE (ESimCSE). We evaluate the proposed ESimCSE on several benchmark datasets w.r.t the semantic text similarity (STS) task. Experimental results show that ESimCSE outperforms the state-of-the-art unsup-SimCSE by an average Spearman correlation of 2.02% on BERT-base.