 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWildSVG: Towards Reliable SVG Generation Under Real-Word Conditions
Feb 24, 2026We introduce the task of SVG extraction, which consists in translating specific visual inputs from an image into scalable vector graphics. Existing multimodal models achieve strong results when generating SVGs from clean renderings or textual descriptions, but they fall short in real-world scenarios where natural images introduce noise, clutter, and domain shifts. A central challenge in this direction is the lack of suitable benchmarks. To address this need, we introduce the WildSVG Benchmark, formed by two complementary datasets: Natural WildSVG, built from real images containing company logos paired with their SVG annotations, and Synthetic WildSVG, which blends complex SVG renderings into real scenes to simulate difficult conditions. Together, these resources provide the first foundation for systematic benchmarking SVG extraction. We benchmark state-of-the-art multimodal models and find that current approaches perform well below what is needed for reliable SVG extraction in real scenarios. Nonetheless, iterative refinement methods point to a promising path forward, and model capabilities are steadily improving
ActiShade: Activating Overshadowed Knowledge to Guide Multi-Hop Reasoning in Large Language Models
Jan 12, 2026In multi-hop reasoning, multi-round retrieval-augmented generation (RAG) methods typically rely on LLM-generated content as the retrieval query. However, these approaches are inherently vulnerable to knowledge overshadowing - a phenomenon where critical information is overshadowed during generation. As a result, the LLM-generated content may be incomplete or inaccurate, leading to irrelevant retrieval and causing error accumulation during the iteration process. To address this challenge, we propose ActiShade, which detects and activates overshadowed knowledge to guide large language models (LLMs) in multi-hop reasoning. Specifically, ActiShade iteratively detects the overshadowed keyphrase in the given query, retrieves documents relevant to both the query and the overshadowed keyphrase, and generates a new query based on the retrieved documents to guide the next-round iteration. By supplementing the overshadowed knowledge during the formulation of next-round queries while minimizing the introduction of irrelevant noise, ActiShade reduces the error accumulation caused by knowledge overshadowing. Extensive experiments show that ActiShade outperforms existing methods across multiple datasets and LLMs.
CoT-MAE v2: Contextual Masked Auto-Encoder with Multi-view Modeling for Passage Retrieval
Apr 05, 2023



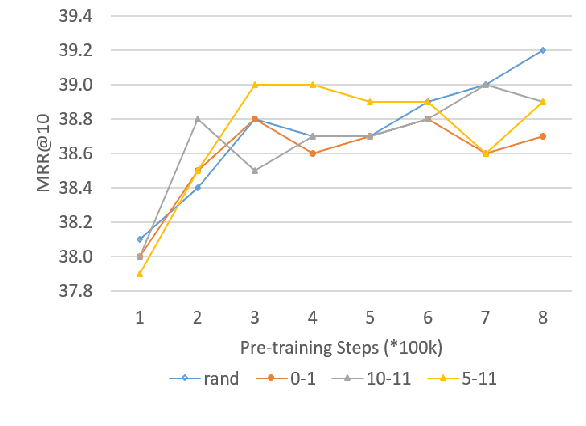
Growing techniques have been emerging to improve the performance of passage retrieval. As an effective representation bottleneck pretraining technique, the contextual masked auto-encoder utilizes contextual embedding to assist in the reconstruction of passages. However, it only uses a single auto-encoding pre-task for dense representation pre-training. This study brings multi-view modeling to the contextual masked auto-encoder. Firstly, multi-view representation utilizes both dense and sparse vectors as multi-view representations, aiming to capture sentence semantics from different aspects. Moreover, multiview decoding paradigm utilizes both autoencoding and auto-regressive decoders in representation bottleneck pre-training, aiming to provide both reconstructive and generative signals for better contextual representation pretraining. We refer to this multi-view pretraining method as CoT-MAE v2. Through extensive experiments, we show that CoT-MAE v2 is effective and robust on large-scale passage retrieval benchmarks and out-of-domain zero-shot benchmarks.
ConTextual Mask Auto-Encoder for Dense Passage Retrieval
Aug 16, 2022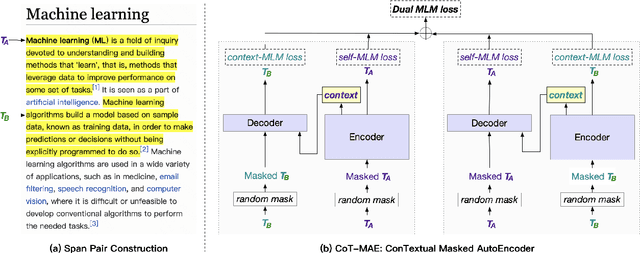


Dense passage retrieval aims to retrieve the relevant passages of a query from a large corpus based on dense representations (i.e., vectors) of the query and the passages. Recent studies have explored improving pre-trained language models to boost dense retrieval performance. This paper proposes CoT-MAE (ConTextual Masked Auto-Encoder), a simple yet effective generative pre-training method for dense passage retrieval. CoT-MAE employs an asymmetric encoder-decoder architecture that learns to compress the sentence semantics into a dense vector through self-supervised and context-supervised masked auto-encoding. Precisely, self-supervised masked auto-encoding learns to model the semantics of the tokens inside a text span, and context-supervised masked auto-encoding learns to model the semantical correlation between the text spans. We conduct experiments on large-scale passage retrieval benchmarks and show considerable improvements over strong baselines, demonstrating the high efficiency of CoT-MAE.
Text Smoothing: Enhance Various Data Augmentation Methods on Text Classification Tasks
Feb 28, 2022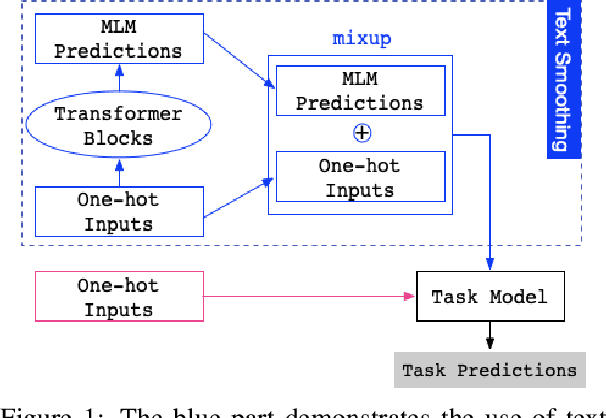
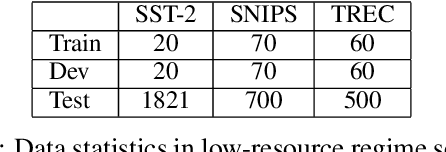
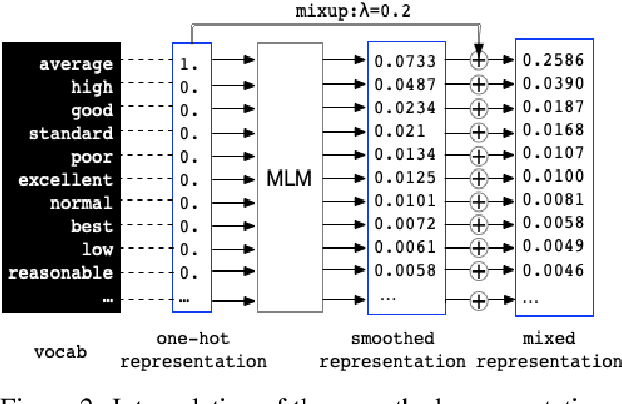
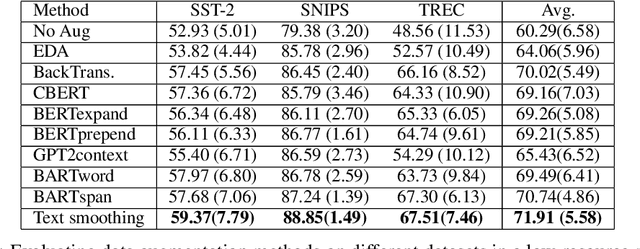
Before entering the neural network, a token is generally converted to the corresponding one-hot representation, which is a discrete distribution of the vocabulary. Smoothed representation is the probability of candidate tokens obtained from a pre-trained masked language model, which can be seen as a more informative substitution to the one-hot representation. We propose an efficient data augmentation method, termed text smoothing, by converting a sentence from its one-hot representation to a controllable smoothed representation. We evaluate text smoothing on different benchmarks in a low-resource regime. Experimental results show that text smoothing outperforms various mainstream data augmentation methods by a substantial margin. Moreover, text smoothing can be combined with those data augmentation methods to achieve better performance.
Imbalanced Sentiment Classification Enhanced with Discourse Marker
Mar 28, 2019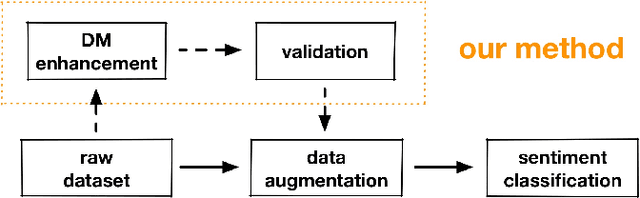



Imbalanced data commonly exists in real world, espacially in sentiment-related corpus, making it difficult to train a classifier to distinguish latent sentiment in text data. We observe that humans often express transitional emotion between two adjacent discourses with discourse markers like "but", "though", "while", etc, and the head discourse and the tail discourse 3 usually indicate opposite emotional tendencies. Based on this observation, we propose a novel plug-and-play method, which first samples discourses according to transitional discourse markers and then validates sentimental polarities with the help of a pretrained attention-based model. Our method increases sample diversity in the first place, can serve as a upstream preprocessing part in data augmentation. We conduct experiments on three public sentiment datasets, with several frequently used algorithms. Results show that our method is found to be consistently effective, even in highly imbalanced scenario, and easily be integrated with oversampling method to boost the performance on imbalanced sentiment classification.