 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransAug: Translate as Augmentation for Sentence Embeddings
Paper and Code
Oct 30, 2021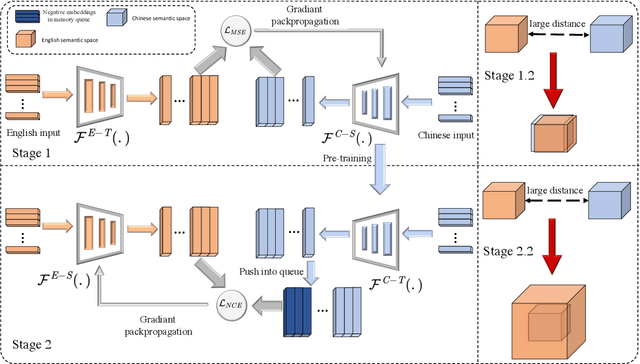

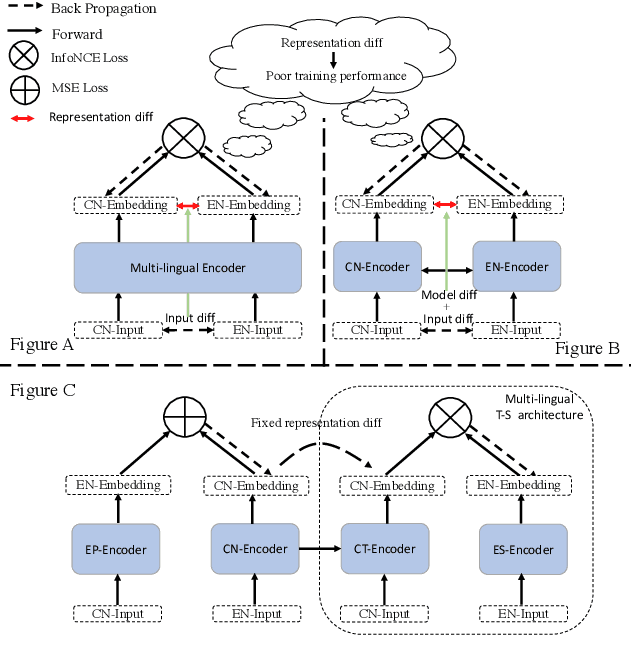

While contrastive learning greatly advances the representation of sentence embeddings, it is still limited by the size of the existing sentence datasets. In this paper, we present TransAug (Translate as Augmentation), which provide the first exploration of utilizing translated sentence pairs as data augmentation for text, and introduce a two-stage paradigm to advances the state-of-the-art sentence embeddings. Instead of adopting an encoder trained in other languages setting, we first distill a Chinese encoder from a SimCSE encoder (pretrained in English), so that their embeddings are close in semantic space, which can be regraded as implicit data augmentation. Then, we only update the English encoder via cross-lingual contrastive learning and frozen the distilled Chinese encoder. Our approach achieves a new state-of-art on standard semantic textual similarity (STS), outperforming both SimCSE and Sentence-T5, and the best performance in corresponding tracks on transfer tasks evaluated by SentEval.