 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaP: Redundancy-aware Video-language Pre-training for Text-Video Retrieval
Paper and Code

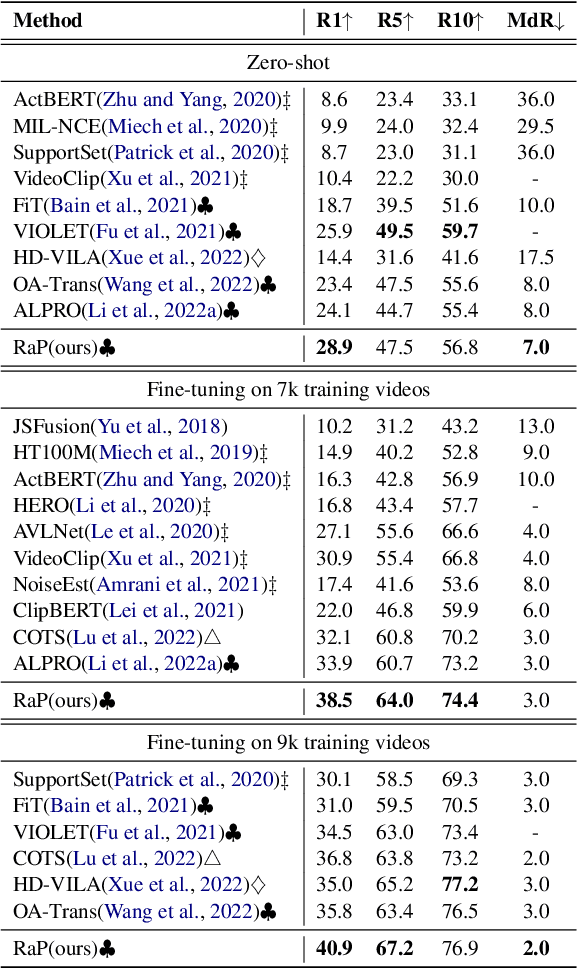
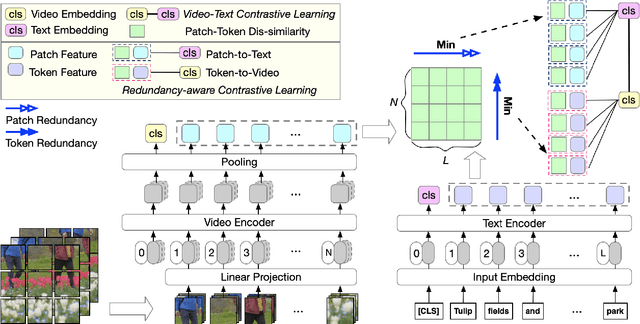
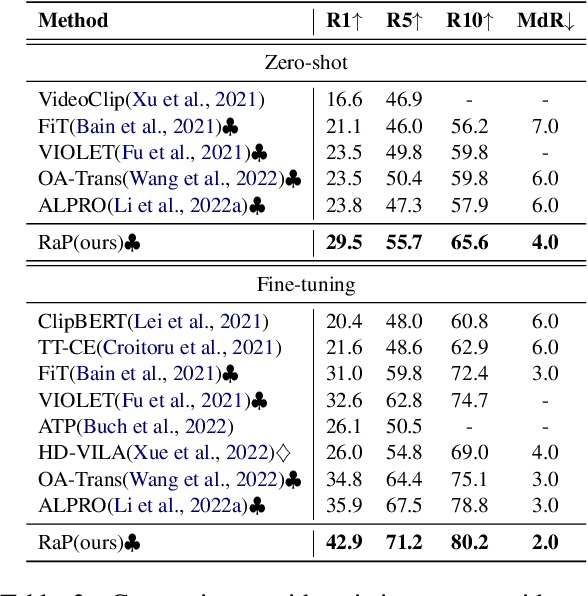
Video language pre-training methods have mainly adopted sparse sampling techniques to alleviate the temporal redundancy of videos. Though effective, sparse sampling still suffers inter-modal redundancy: visual redundancy and textual redundancy. Compared with highly generalized text, sparsely sampled frames usually contain text-independent portions, called visual redundancy. Sparse sampling is also likely to miss important frames corresponding to some text portions, resulting in textual redundancy. Inter-modal redundancy leads to a mismatch of video and text information, hindering the model from better learning the shared semantics across modalities. To alleviate it, we propose Redundancy-aware Video-language Pre-training. We design a redundancy measurement of video patches and text tokens by calculating the cross-modal minimum dis-similarity. Then, we penalize the highredundant video patches and text tokens through a proposed redundancy-aware contrastive learning. We evaluate our method on four benchmark datasets, MSRVTT, MSVD, DiDeMo, and LSMDC, achieving a significant improvement over the previous stateof-the-art results. Our code are available at https://github.com/caskcsg/VLP/tree/main/RaP.