 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Copy-Mechanism in Dialogue State Tracking
Feb 22, 2020
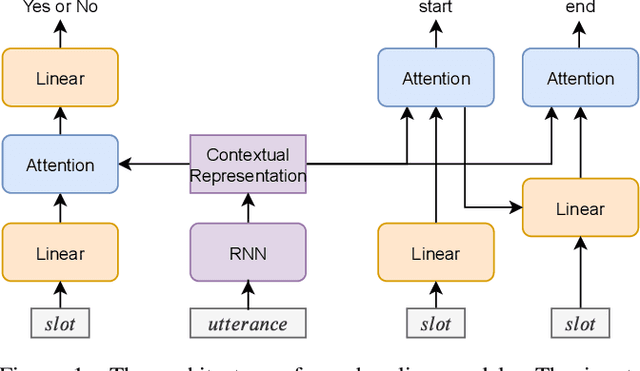
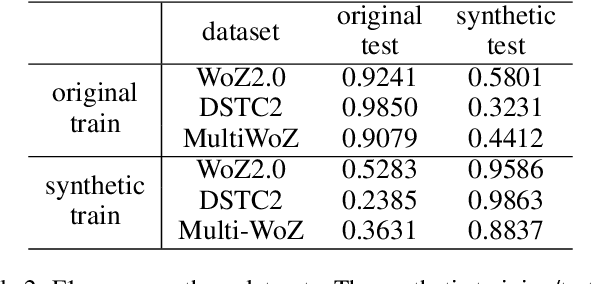
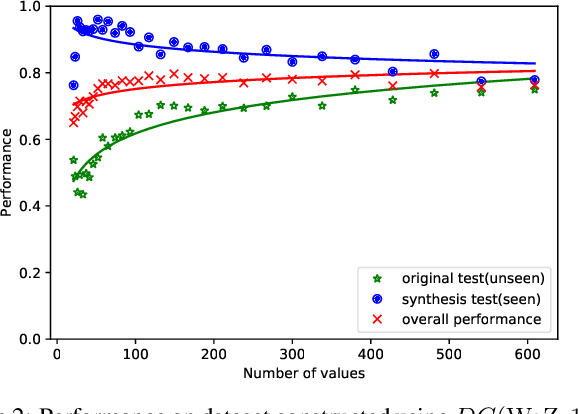
While several state-of-the-art approaches to dialogue state tracking (DST) have shown promising performances on several benchmarks, there is still a significant performance gap between seen slot values (i.e., values that occur in both training set and test set) and unseen ones (values that occur in training set but not in test set). Recently, the copy-mechanism has been widely used in DST models to handle unseen slot values, which copies slot values from user utterance directly. In this paper, we aim to find out the factors that influence the generalization ability of a common copy-mechanism model for DST. Our key observations include: 1) the copy-mechanism tends to memorize values rather than infer them from contexts, which is the primary reason for unsatisfactory generalization performance; 2) greater diversity of slot values in the training set increase the performance on unseen values but slightly decrease the performance on seen values. Moreover, we propose a simple but effective algorithm of data augmentation to train copy-mechanism models, which augments the input dataset by copying user utterances and replacing the real slot values with randomly generated strings. Users could use two hyper-parameters to realize a trade-off between the performances on seen values and unseen ones, as well as a trade-off between overall performance and computational cost. Experimental results on three widely used datasets (WoZ 2.0, DSTC2, and Multi-WoZ 2.0) show the effectiveness of our approach.