 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCloudCons: A Comprehensive End-to-End Benchmark for Cloud Resource Consolidation
Jun 11, 2026Driven by conservative over-provisioning to guarantee service reliability, resource utilization in cloud data centers remains at low levels. To mitigate this, the forecast-then-optimize paradigm has emerged to optimize consolidation by anticipating future demands. While emerging time series foundation models promise to enhance this paradigm through zero-shot generalization, existing benchmarks focus solely on prediction error metrics. The actual decision utility of these advanced models remains unverified, rendering their practical value for downstream tasks uncertain. To bridge this gap, we propose CloudCons, a comprehensive end-to-end benchmark designed to evaluate forecasting models within the specific context of cloud resource consolidation. We build high-quality datasets that cover diverse workloads from Huawei Cloud, Microsoft Azure, and Google Borg, capturing distinct service characteristics ranging from synchronized diurnal rhythms to stochastic, pulse-like bursts and high-frequency noise. We conduct an extensive evaluation of statistical, deep learning, and foundation models. Our experiments reveal a pivotal finding: while foundation models demonstrate superior zero-shot forecasting accuracy, this advantage does not inherently translate into better decision utility. Of practical significance, we systematically analyze how the selection of predictive quantiles acts as a critical lever. We provide actionable guidelines for calibrating these selections to balance the trade-off between resource efficiency and service reliability, offering vital insights for real-world deployment decisions.
TSFMAudit: Data Contamination Auditing in Forecasting Time Series Foundation Models
May 24, 2026Time series foundation models (TSFMs) are increasingly pretrained on large corpora, raising concerns that evaluation datasets may have been exposed during pretraining and thus yield overly optimistic performance estimates. Auditing such contamination is challenging in time series because signals are continuous and heterogeneous, and often lack corpus documentation. To the best of our knowledge, this is the first work to study pretraining contamination auditing for TSFMs. We formalize the problem of pretraining contamination auditing for TSFMs and propose TSFMAudit, a method based on probe adaptation dynamics. Our key intuition is that contamination manifests as unusually efficient adaptation: after a fine tuning probe, contaminated datasets tend to exhibit faster loss reduction with smaller backbone movement. We evaluate TSFMAudit on 6 TSFMs and 187 datasets using documented training source evidence as supervision, and compare against 10 competitive baselines adapted from the LLM literature.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
A Koopman Operator-based NMPC Framework for Mobile Robot Navigation under Uncertainty
Apr 29, 2025

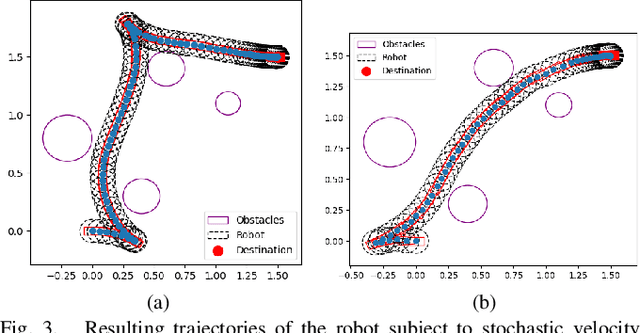

Mobile robot navigation can be challenged by system uncertainty. For example, ground friction may vary abruptly causing slipping, and noisy sensor data can lead to inaccurate feedback control. Traditional model-based methods may be limited when considering such variations, making them fragile to varying types of uncertainty. One way to address this is by leveraging learned prediction models by means of the Koopman operator into nonlinear model predictive control (NMPC). This paper describes the formulation of, and provides the solution to, an NMPC problem using a lifted bilinear model that can accurately predict affine input systems with stochastic perturbations. System constraints are defined in the Koopman space, while the optimization problem is solved in the state space to reduce computational complexity. Training data to estimate the Koopman operator for the system are given via randomized control inputs. The output of the developed method enables closed-loop navigation control over environments populated with obstacles. The effectiveness of the proposed method has been tested through numerical simulations using a wheeled robot with additive stochastic velocity perturbations, Gazebo simulations with a realistic digital twin robot, and physical hardware experiments without knowledge of the true dynamics.
Learning-based Estimation of Forward Kinematics for an Orthotic Parallel Robotic Mechanism
Mar 14, 2025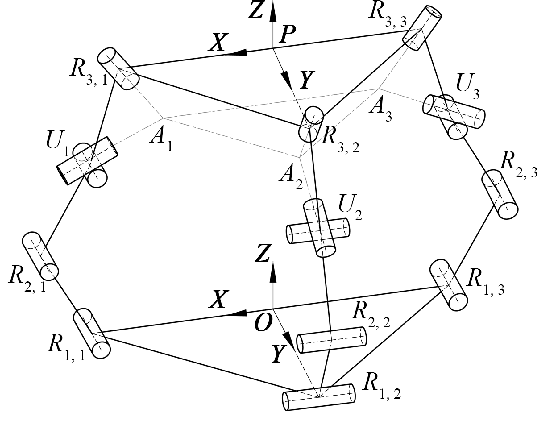
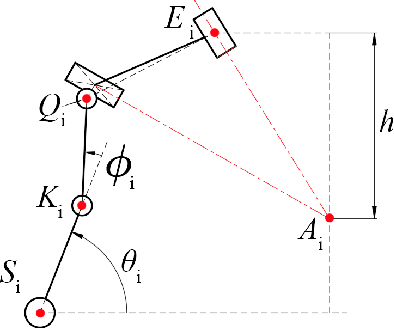
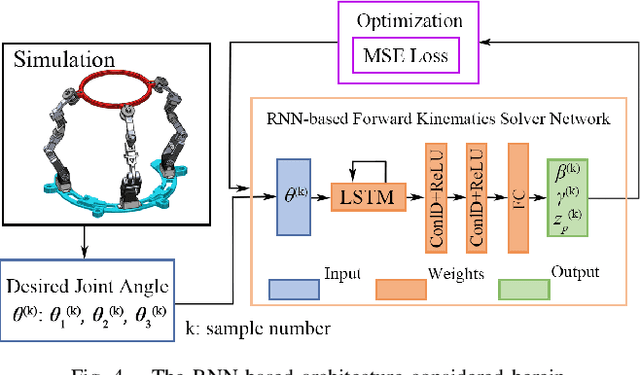
This paper introduces a 3D parallel robot with three identical five-degree-of-freedom chains connected to a circular brace end-effector, aimed to serve as an assistive device for patients with cervical spondylosis. The inverse kinematics of the system is solved analytically, whereas learning-based methods are deployed to solve the forward kinematics. The methods considered herein include a Koopman operator-based approach as well as a neural network-based approach. The task is to predict the position and orientation of end-effector trajectories. The dataset used to train these methods is based on the analytical solutions derived via inverse kinematics. The methods are tested both in simulation and via physical hardware experiments with the developed robot. Results validate the suitability of deploying learning-based methods for studying parallel mechanism forward kinematics that are generally hard to resolve analytically.
Event Temporal Relation Extraction based on Retrieval-Augmented on LLMs
Mar 22, 2024

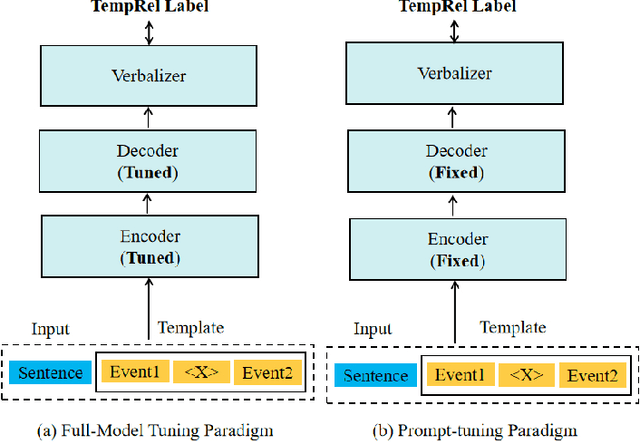

Event temporal relation (TempRel) is a primary subject of the event relation extraction task. However, the inherent ambiguity of TempRel increases the difficulty of the task. With the rise of prompt engineering, it is important to design effective prompt templates and verbalizers to extract relevant knowledge. The traditional manually designed templates struggle to extract precise temporal knowledge. This paper introduces a novel retrieval-augmented TempRel extraction approach, leveraging knowledge retrieved from large language models (LLMs) to enhance prompt templates and verbalizers. Our method capitalizes on the diverse capabilities of various LLMs to generate a wide array of ideas for template and verbalizer design. Our proposed method fully exploits the potential of LLMs for generation tasks and contributes more knowledge to our design. Empirical evaluations across three widely recognized datasets demonstrate the efficacy of our method in improving the performance of event temporal relation extraction tasks.
Supervisor Synthesis of POMDP based on Automata Learning
Mar 24, 2017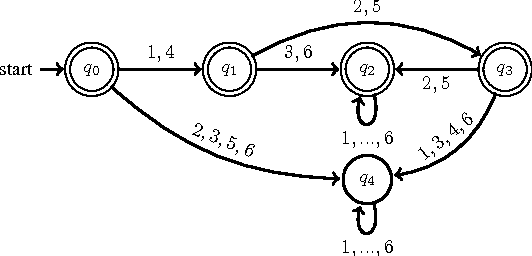
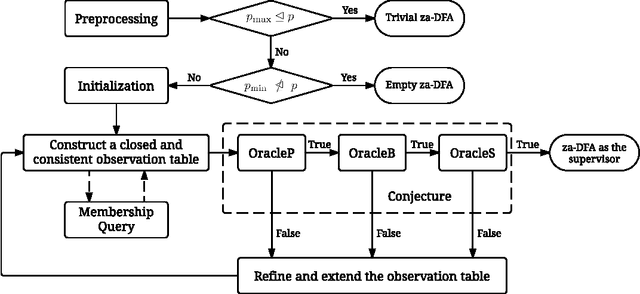
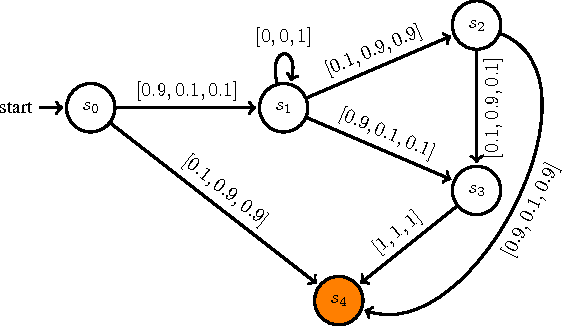
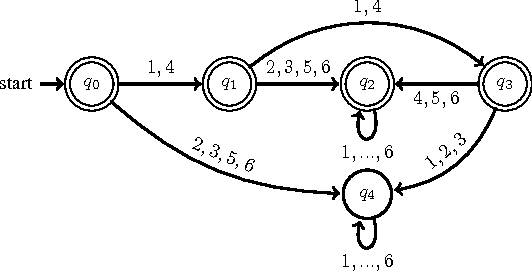
As a general and thus popular model for autonomous systems, partially observable Markov decision process (POMDP) can capture uncertainties from different sources like sensing noises, actuation errors, and uncertain environments. However, its comprehensiveness makes the planning and control in POMDP difficult. Traditional POMDP planning problems target to find the optimal policy to maximize the expectation of accumulated rewards. But for safety critical applications, guarantees of system performance described by formal specifications are desired, which motivates us to consider formal methods to synthesize supervisor for POMDP. With system specifications given by Probabilistic Computation Tree Logic (PCTL), we propose a supervisory control framework with a type of deterministic finite automata (DFA), za-DFA, as the controller form. While the existing work mainly relies on optimization techniques to learn fixed-size finite state controllers (FSCs), we develop an $L^*$ learning based algorithm to determine both space and transitions of za-DFA. Membership queries and different oracles for conjectures are defined. The learning algorithm is sound and complete. An example is given in detailed steps to illustrate the supervisor synthesis algorithm.