 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVBGS-SLAM: Variational Bayesian Gaussian Splatting Simultaneous Localization and Mapping
Apr 03, 20263D Gaussian Splatting (3DGS) has shown promising results for 3D scene modeling using mixtures of Gaussians, yet its existing simultaneous localization and mapping (SLAM) variants typically rely on direct, deterministic pose optimization against the splat map, making them sensitive to initialization and susceptible to catastrophic forgetting as map evolves. We propose Variational Bayesian Gaussian Splatting SLAM (VBGS-SLAM), a novel framework that couples the splat map refinement and camera pose tracking in a generative probabilistic form. By leveraging conjugate properties of multivariate Gaussians and variational inference, our method admits efficient closed-form updates and explicitly maintains posterior uncertainty over both poses and scene parameters. This uncertainty-aware method mitigates drift and enhances robustness in challenging conditions, while preserving the efficiency and rendering quality of existing 3DGS. Our experiments demonstrate superior tracking performance and robustness in long sequence prediction, alongside efficient, high-quality novel view synthesis across diverse synthetic and real-world scenes.
GCGNet: Graph-Consistent Generative Network for Time Series Forecasting with Exogenous Variables
Mar 09, 2026Exogenous variables offer valuable supplementary information for predicting future endogenous variables. Forecasting with exogenous variables needs to consider both past-to-future dependencies (i.e., temporal correlations) and the influence of exogenous variables on endogenous variables (i.e., channel correlations). This is pivotal when future exogenous variables are available, because they may directly affect the future endogenous variables. Many methods have been proposed for time series forecasting with exogenous variables, focusing on modeling temporal and channel correlations. However, most of them use a two-step strategy, modeling temporal and channel correlations separately, which limits their ability to capture joint correlations across time and channels. Furthermore, in real-world scenarios, time series are frequently affected by various forms of noises, underscoring the critical importance of robustness in such correlations modeling. To address these limitations, we propose GCGNet, a Graph-Consistent Generative Network for time series forecasting with exogenous variables. Specifically, GCGNet first employs a Variational Generator to produce coarse predictions. A Graph Structure Aligner then further guides it by evaluating the consistency between the generated and true correlations, where the correlations are represented as graphs, and are robust to noises. Finally, a Graph Refiner is proposed to refine the predictions to prevent degeneration and improve accuracy. Extensive experiments on 12 real-world datasets demonstrate that GCGNet outperforms state-of-the-art baselines.
Video-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Jan 30, 2026Existing multimodal large language models for long-video understanding predominantly rely on uniform sampling and single-turn inference, limiting their ability to identify sparse yet critical evidence amid extensive redundancy. We introduce Video-o3, a novel framework that supports iterative discovery of salient visual clues, fine-grained inspection of key segments, and adaptive termination once sufficient evidence is acquired. Technically, we address two core challenges in interleaved tool invocation. First, to mitigate attention dispersion induced by the heterogeneity of reasoning and tool-calling, we propose Task-Decoupled Attention Masking, which isolates per-step concentration while preserving shared global context. Second, to control context length growth in multi-turn interactions, we introduce a Verifiable Trajectory-Guided Reward that balances exploration coverage with reasoning efficiency. To support training at scale, we further develop a data synthesis pipeline and construct Seeker-173K, comprising 173K high-quality tool-interaction trajectories for effective supervised and reinforcement learning. Extensive experiments show that Video-o3 substantially outperforms state-of-the-art methods, achieving 72.1% accuracy on MLVU and 46.5% on Video-Holmes. These results demonstrate Video-o3's strong multi-hop evidence-seeking and reasoning capabilities, and validate the effectiveness of native tool invocation in long-video scenarios.
DAG: A Dual Causal Network for Time Series Forecasting with Exogenous Variables
Sep 18, 2025Time series forecasting is crucial in various fields such as economics, traffic, and AIOps. However, in real-world applications, focusing solely on the endogenous variables (i.e., target variables), is often insufficient to ensure accurate predictions. Considering exogenous variables (i.e., covariates) provides additional predictive information, thereby improving forecasting accuracy. However, existing methods for time series forecasting with exogenous variables (TSF-X) have the following shortcomings: 1) they do not leverage future exogenous variables, 2) they fail to account for the causal relationships between endogenous and exogenous variables. As a result, their performance is suboptimal. In this study, to better leverage exogenous variables, especially future exogenous variable, we propose a general framework DAG, which utilizes dual causal network along both the temporal and channel dimensions for time series forecasting with exogenous variables. Specifically, we first introduce the Temporal Causal Module, which includes a causal discovery module to capture how historical exogenous variables affect future exogenous variables. Following this, we construct a causal injection module that incorporates the discovered causal relationships into the process of forecasting future endogenous variables based on historical endogenous variables. Next, we propose the Channel Causal Module, which follows a similar design principle. It features a causal discovery module models how historical exogenous variables influence historical endogenous variables, and a causal injection module incorporates the discovered relationships to enhance the prediction of future endogenous variables based on future exogenous variables.
Agent-as-a-Service based on Agent Network
May 13, 2025The rise of large model-based AI agents has spurred interest in Multi-Agent Systems (MAS) for their capabilities in decision-making, collaboration, and adaptability. While the Model Context Protocol (MCP) addresses tool invocation and data exchange challenges via a unified protocol, it lacks support for organizing agent-level collaboration. To bridge this gap, we propose Agent-as-a-Service based on Agent Network (AaaS-AN), a service-oriented paradigm grounded in the Role-Goal-Process-Service (RGPS) standard. AaaS-AN unifies the entire agent lifecycle, including construction, integration, interoperability, and networked collaboration, through two core components: (1) a dynamic Agent Network, which models agents and agent groups as vertexes that self-organize within the network based on task and role dependencies; (2) service-oriented agents, incorporating service discovery, registration, and interoperability protocols. These are orchestrated by a Service Scheduler, which leverages an Execution Graph to enable distributed coordination, context tracking, and runtime task management. We validate AaaS-AN on mathematical reasoning and application-level code generation tasks, which outperforms state-of-the-art baselines. Notably, we constructed a MAS based on AaaS-AN containing agent groups, Robotic Process Automation (RPA) workflows, and MCP servers over 100 agent services. We also release a dataset containing 10,000 long-horizon multi-agent workflows to facilitate future research on long-chain collaboration in MAS.
Learning-based Estimation of Forward Kinematics for an Orthotic Parallel Robotic Mechanism
Mar 14, 2025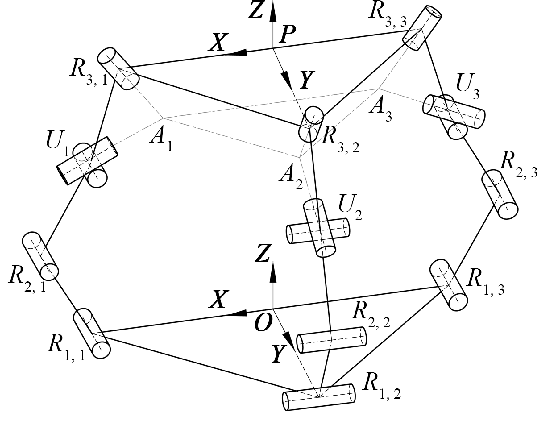
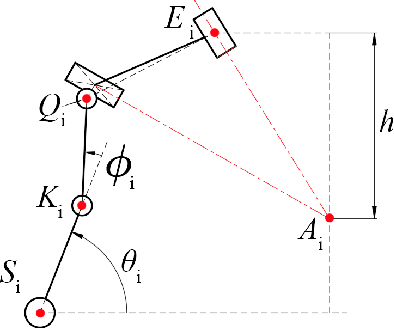
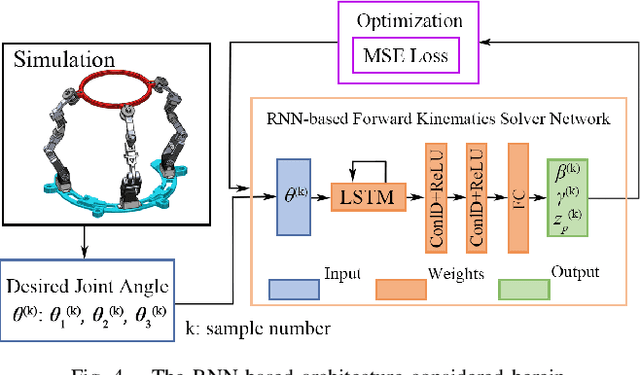
This paper introduces a 3D parallel robot with three identical five-degree-of-freedom chains connected to a circular brace end-effector, aimed to serve as an assistive device for patients with cervical spondylosis. The inverse kinematics of the system is solved analytically, whereas learning-based methods are deployed to solve the forward kinematics. The methods considered herein include a Koopman operator-based approach as well as a neural network-based approach. The task is to predict the position and orientation of end-effector trajectories. The dataset used to train these methods is based on the analytical solutions derived via inverse kinematics. The methods are tested both in simulation and via physical hardware experiments with the developed robot. Results validate the suitability of deploying learning-based methods for studying parallel mechanism forward kinematics that are generally hard to resolve analytically.
MedMimic: Physician-Inspired Multimodal Fusion for Early Diagnosis of Fever of Unknown Origin
Feb 07, 2025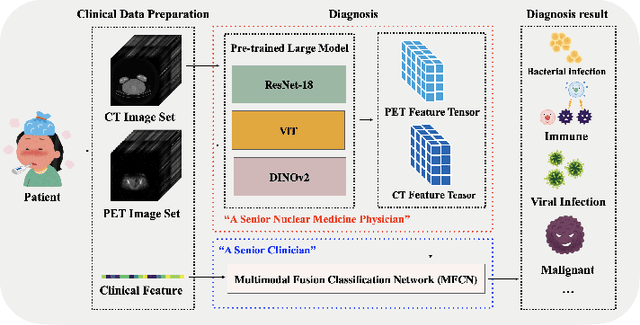
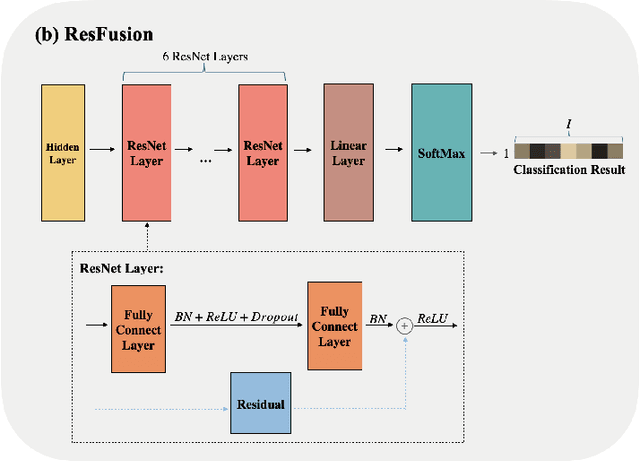
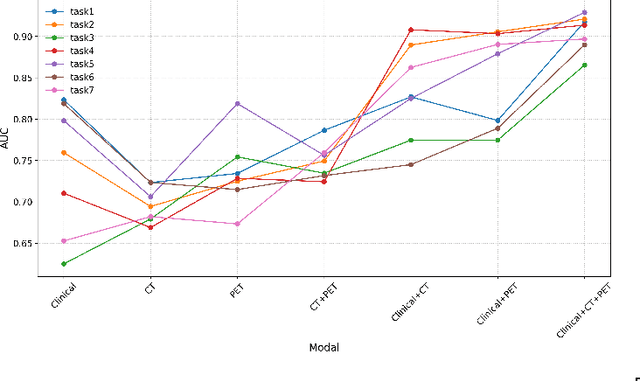
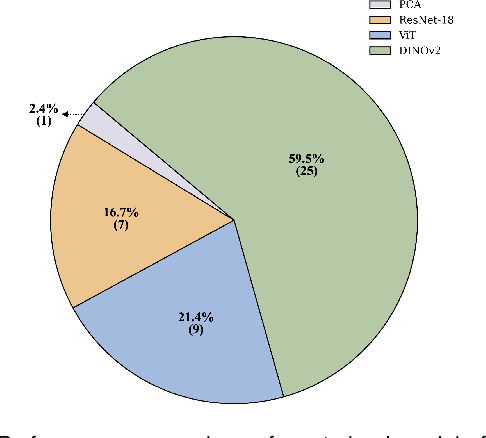
Fever of unknown origin FUO remains a diagnostic challenge. MedMimic is introduced as a multimodal framework inspired by real-world diagnostic processes. It uses pretrained models such as DINOv2, Vision Transformer, and ResNet-18 to convert high-dimensional 18F-FDG PET/CT imaging into low-dimensional, semantically meaningful features. A learnable self-attention-based fusion network then integrates these imaging features with clinical data for classification. Using 416 FUO patient cases from Sichuan University West China Hospital from 2017 to 2023, the multimodal fusion classification network MFCN achieved macro-AUROC scores ranging from 0.8654 to 0.9291 across seven tasks, outperforming conventional machine learning and single-modality deep learning methods. Ablation studies and five-fold cross-validation further validated its effectiveness. By combining the strengths of pretrained large models and deep learning, MedMimic offers a promising solution for disease classification.
Motion-Aware Generative Frame Interpolation
Jan 07, 2025Generative frame interpolation, empowered by large-scale pre-trained video generation models, has demonstrated remarkable advantages in complex scenes. However, existing methods heavily rely on the generative model to independently infer the correspondences between input frames, an ability that is inadequately developed during pre-training. In this work, we propose a novel framework, termed Motion-aware Generative frame interpolation (MoG), to significantly enhance the model's motion awareness by integrating explicit motion guidance. Specifically we investigate two key questions: what can serve as an effective motion guidance, and how we can seamlessly embed this guidance into the generative model. For the first question, we reveal that the intermediate flow from flow-based interpolation models could efficiently provide task-oriented motion guidance. Regarding the second, we first obtain guidance-based representations of intermediate frames by warping input frames' representations using guidance, and then integrate them into the model at both latent and feature levels. To demonstrate the versatility of our method, we train MoG on both real-world and animation datasets. Comprehensive evaluations show that our MoG significantly outperforms the existing methods in both domains, achieving superior video quality and improved fidelity.
VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
Dec 31, 2024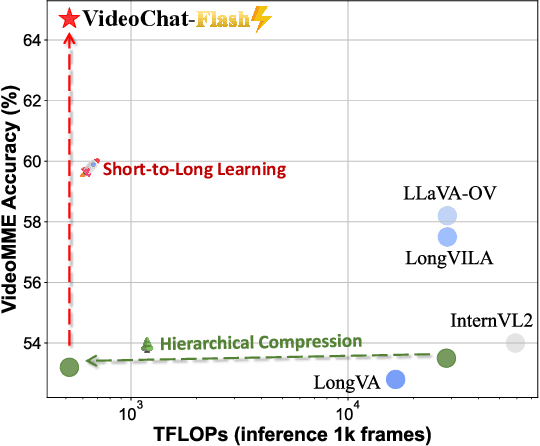
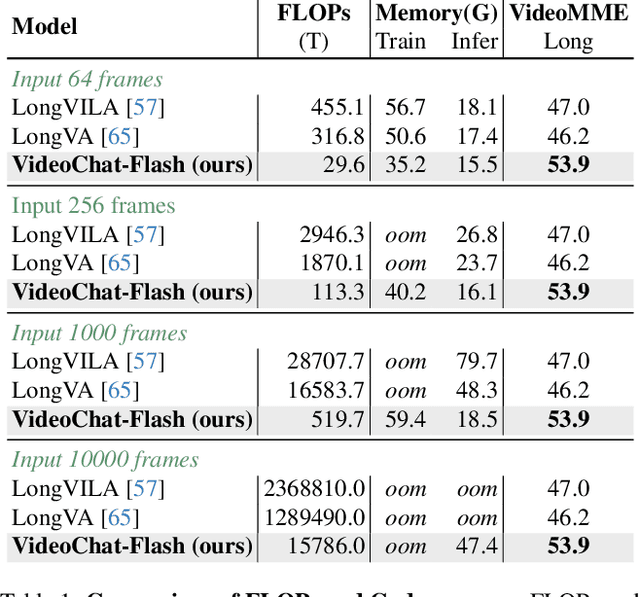

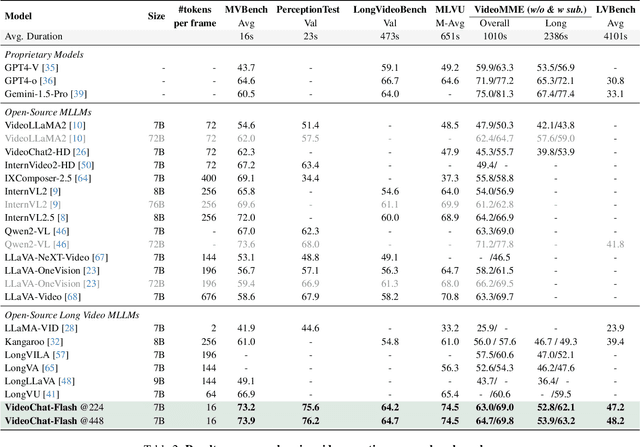
Long-context modeling is a critical capability for multimodal large language models (MLLMs), enabling them to process long-form contents with implicit memorization. Despite its advances, handling extremely long videos remains challenging due to the difficulty in maintaining crucial features over extended sequences. This paper introduces a Hierarchical visual token Compression (HiCo) method designed for high-fidelity representation and a practical context modeling system VideoChat-Flash tailored for multimodal long-sequence processing. HiCo capitalizes on the redundancy of visual information in long videos to compress long video context from the clip-level to the video-level, reducing the compute significantly while preserving essential details. VideoChat-Flash features a multi-stage short-to-long learning scheme, a rich dataset of real-world long videos named LongVid, and an upgraded "Needle-In-A-video-Haystack" (NIAH) for evaluating context capacities. In extensive experiments, VideoChat-Flash shows the leading performance on both mainstream long and short video benchmarks at the 7B model scale. It firstly gets 99.1% accuracy over 10,000 frames in NIAH among open-source models.
Efficient Test-Time Prompt Tuning for Vision-Language Models
Aug 11, 2024



Vision-language models have showcased impressive zero-shot classification capabilities when equipped with suitable text prompts. Previous studies have shown the effectiveness of test-time prompt tuning; however, these methods typically require per-image prompt adaptation during inference, which incurs high computational budgets and limits scalability and practical deployment. To overcome this issue, we introduce Self-TPT, a novel framework leveraging Self-supervised learning for efficient Test-time Prompt Tuning. The key aspect of Self-TPT is that it turns to efficient predefined class adaptation via self-supervised learning, thus avoiding computation-heavy per-image adaptation at inference. Self-TPT begins by co-training the self-supervised and the classification task using source data, then applies the self-supervised task exclusively for test-time new class adaptation. Specifically, we propose Contrastive Prompt Learning (CPT) as the key task for self-supervision. CPT is designed to minimize the intra-class distances while enhancing inter-class distinguishability via contrastive learning. Furthermore, empirical evidence suggests that CPT could closely mimic back-propagated gradients of the classification task, offering a plausible explanation for its effectiveness. Motivated by this finding, we further introduce a gradient matching loss to explicitly enhance the gradient similarity. We evaluated Self-TPT across three challenging zero-shot benchmarks. The results consistently demonstrate that Self-TPT not only significantly reduces inference costs but also achieves state-of-the-art performance, effectively balancing the efficiency-efficacy trade-off.