 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPL: Decoupled Prompt Learning for Vision-Language Models
Paper and Code
Aug 19, 2023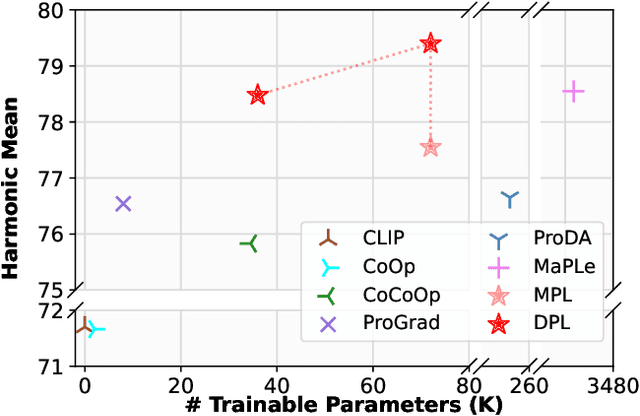
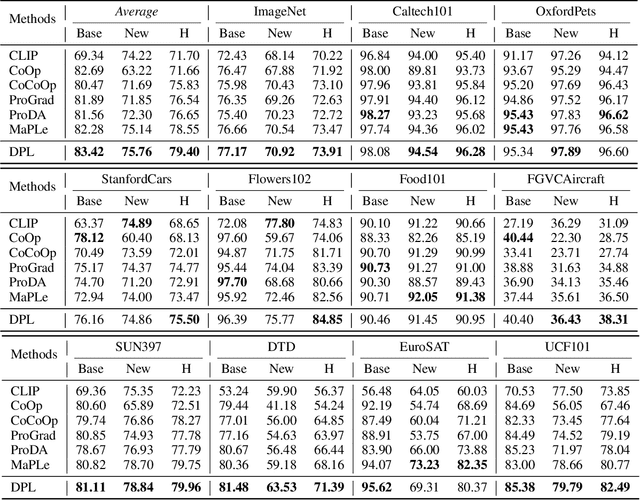
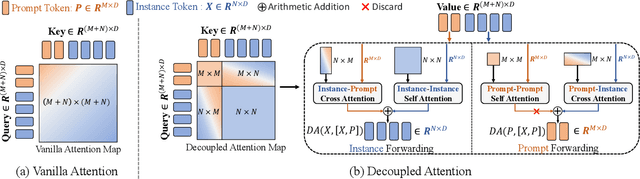
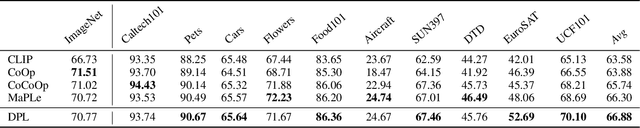
Prompt learning has emerged as an efficient and effective approach for transferring foundational Vision-Language Models (e.g., CLIP) to downstream tasks. However, current methods tend to overfit to seen categories, thereby limiting their generalization ability for unseen classes. In this paper, we propose a new method, Decoupled Prompt Learning (DPL), which reformulates the attention in prompt learning to alleviate this problem. Specifically, we theoretically investigate the collaborative process between prompts and instances (i.e., image patches/text tokens) by reformulating the original self-attention into four separate sub-processes. Through detailed analysis, we observe that certain sub-processes can be strengthened to bolster robustness and generalizability by some approximation techniques. Furthermore, we introduce language-conditioned textual prompting based on decoupled attention to naturally preserve the generalization of text input. Our approach is flexible for both visual and textual modalities, making it easily extendable to multi-modal prompt learning. By combining the proposed techniques, our approach achieves state-of-the-art performance on three representative benchmarks encompassing 15 image recognition datasets, while maintaining parameter-efficient. Moreover, our DPL does not rely on any auxiliary regularization task or extra training data, further demonstrating its remarkable generalization ability.