 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRayFusion: Ray Fusion Enhanced Collaborative Visual Perception
Oct 09, 2025



Collaborative visual perception methods have gained widespread attention in the autonomous driving community in recent years due to their ability to address sensor limitation problems. However, the absence of explicit depth information often makes it difficult for camera-based perception systems, e.g., 3D object detection, to generate accurate predictions. To alleviate the ambiguity in depth estimation, we propose RayFusion, a ray-based fusion method for collaborative visual perception. Using ray occupancy information from collaborators, RayFusion reduces redundancy and false positive predictions along camera rays, enhancing the detection performance of purely camera-based collaborative perception systems. Comprehensive experiments show that our method consistently outperforms existing state-of-the-art models, substantially advancing the performance of collaborative visual perception. The code is available at https://github.com/wangsh0111/RayFusion.
MIDAS: Modeling Ground-Truth Distributions with Dark Knowledge for Domain Generalized Stereo Matching
Mar 06, 2025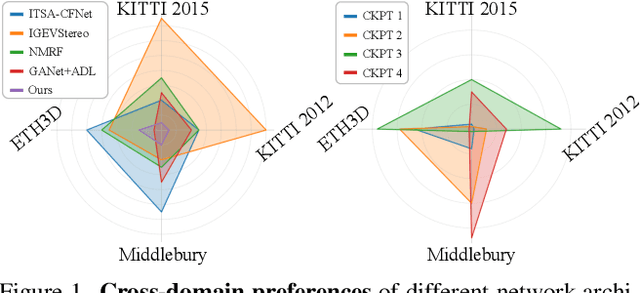



Despite the significant advances in domain generalized stereo matching, existing methods still exhibit domain-specific preferences when transferring from synthetic to real domains, hindering their practical applications in complex and diverse scenarios. The probability distributions predicted by the stereo network naturally encode rich similarity and uncertainty information. Inspired by this observation, we propose to extract these two types of dark knowledge from the pre-trained network to model intuitive multi-modal ground-truth distributions for both edge and non-edge regions. To mitigate the inherent domain preferences of a single network, we adopt network ensemble and further distinguish between objective and biased knowledge in the Laplace parameter space. Finally, the objective knowledge and the original disparity labels are jointly modeled as a mixture of Laplacians to provide fine-grained supervision for the stereo network training. Extensive experiments demonstrate that: 1) Our method is generic and effectively improves the generalization of existing networks. 2) PCWNet with our method achieves the state-of-the-art generalization performance on both KITTI 2015 and 2012 datasets. 3) Our method outperforms existing methods in comprehensive ranking across four popular real-world datasets.
SCKD: Semi-Supervised Cross-Modality Knowledge Distillation for 4D Radar Object Detection
Dec 19, 20243D object detection is one of the fundamental perception tasks for autonomous vehicles. Fulfilling such a task with a 4D millimeter-wave radar is very attractive since the sensor is able to acquire 3D point clouds similar to Lidar while maintaining robust measurements under adverse weather. However, due to the high sparsity and noise associated with the radar point clouds, the performance of the existing methods is still much lower than expected. In this paper, we propose a novel Semi-supervised Cross-modality Knowledge Distillation (SCKD) method for 4D radar-based 3D object detection. It characterizes the capability of learning the feature from a Lidar-radar-fused teacher network with semi-supervised distillation. We first propose an adaptive fusion module in the teacher network to boost its performance. Then, two feature distillation modules are designed to facilitate the cross-modality knowledge transfer. Finally, a semi-supervised output distillation is proposed to increase the effectiveness and flexibility of the distillation framework. With the same network structure, our radar-only student trained by SCKD boosts the mAP by 10.38% over the baseline and outperforms the state-of-the-art works on the VoD dataset. The experiment on ZJUODset also shows 5.12% mAP improvements on the moderate difficulty level over the baseline when extra unlabeled data are available. Code is available at https://github.com/Ruoyu-Xu/SCKD.