 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLite-SAM Is Actually What You Need for Segment Everything
Jul 12, 2024

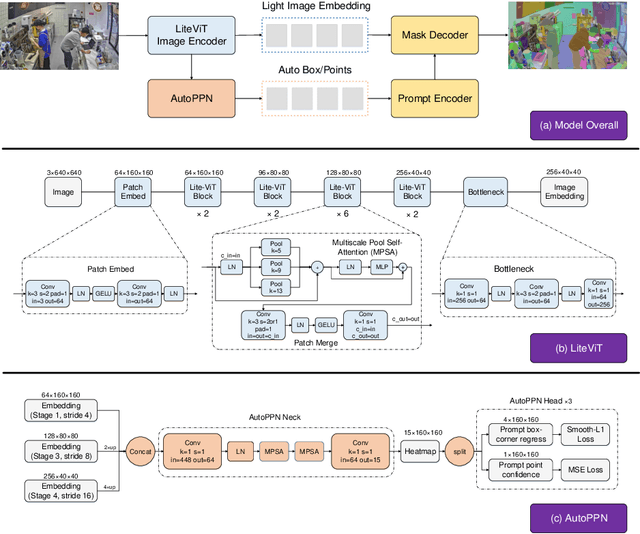

This paper introduces Lite-SAM, an efficient end-to-end solution for the SegEvery task designed to reduce computational costs and redundancy. Lite-SAM is composed of four main components: a streamlined CNN-Transformer hybrid encoder (LiteViT), an automated prompt proposal network (AutoPPN), a traditional prompt encoder, and a mask decoder. All these components are integrated within the SAM framework. Our LiteViT, a high-performance lightweight backbone network, has only 1.16M parameters, which is a 23% reduction compared to the lightest existing backbone network Shufflenet. We also introduce AutoPPN, an innovative end-to-end method for prompt boxes and points generation. This is an improvement over traditional grid search sampling methods, and its unique design allows for easy integration into any SAM series algorithm, extending its usability. we have thoroughly benchmarked Lite-SAM across a plethora of both public and private datasets. The evaluation encompassed a broad spectrum of universal metrics, including the number of parameters, SegEvery execution time, and accuracy. The findings reveal that Lite-SAM, operating with a lean 4.2M parameters, significantly outpaces its counterparts, demonstrating performance improvements of 43x, 31x, 20x, 21x, and 1.6x over SAM, MobileSAM, Edge-SAM, EfficientViT-SAM, and MobileSAM-v2 respectively, all the while maintaining competitive accuracy. This underscores Lite-SAM's prowess in achieving an optimal equilibrium between performance and precision, thereby setting a new state-of-the-art(SOTA) benchmark in the domain.
Pixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks
Nov 19, 2018
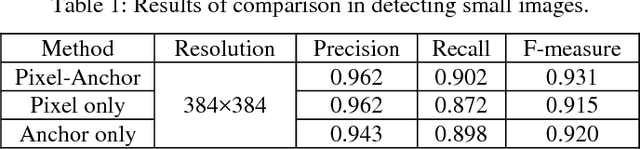

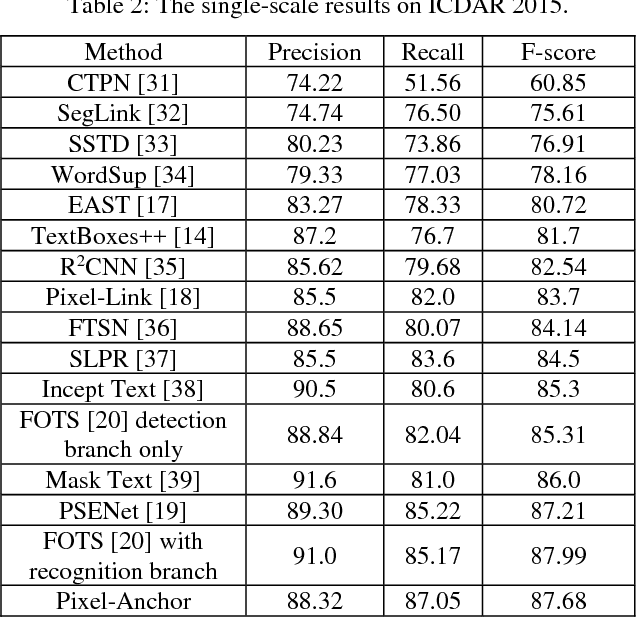
Recently, semantic segmentation and general object detection frameworks have been widely adopted by scene text detecting tasks. However, both of them alone have obvious shortcomings in practice. In this paper, we propose a novel end-to-end trainable deep neural network framework, named Pixel-Anchor, which combines semantic segmentation and SSD in one network by feature sharing and anchor-level attention mechanism to detect oriented scene text. To deal with scene text which has large variances in size and aspect ratio, we combine FPN and ASPP operation as our encoder-decoder structure in the semantic segmentation part, and propose a novel Adaptive Predictor Layer in the SSD. Pixel-Anchor detects scene text in a single network forward pass, no complex post-processing other than an efficient fusion Non-Maximum Suppression is involved. We have benchmarked the proposed Pixel-Anchor on the public datasets. Pixel-Anchor outperforms the competing methods in terms of text localization accuracy and run speed, more specifically, on the ICDAR 2015 dataset, the proposed algorithm achieves an F-score of 0.8768 at 10 FPS for 960 x 1728 resolution images.