 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks
Nov 19, 2018
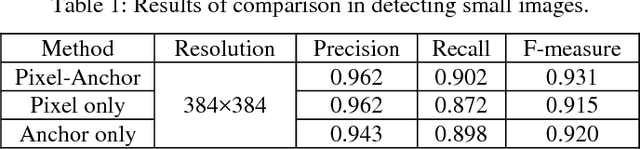

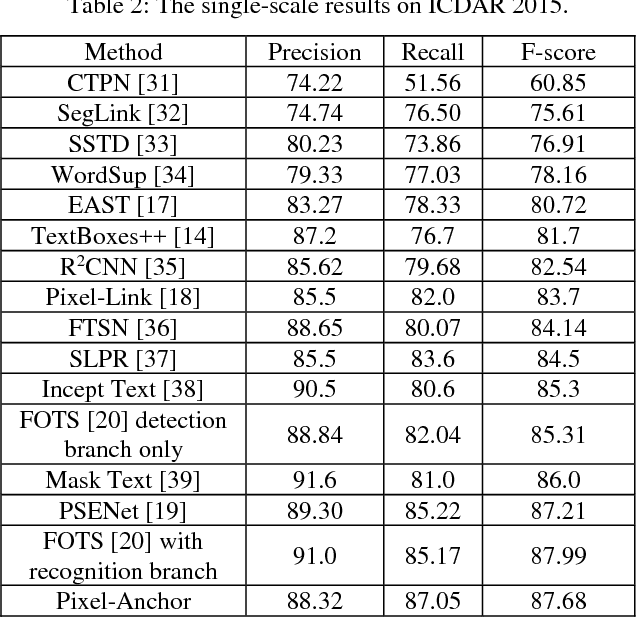
Recently, semantic segmentation and general object detection frameworks have been widely adopted by scene text detecting tasks. However, both of them alone have obvious shortcomings in practice. In this paper, we propose a novel end-to-end trainable deep neural network framework, named Pixel-Anchor, which combines semantic segmentation and SSD in one network by feature sharing and anchor-level attention mechanism to detect oriented scene text. To deal with scene text which has large variances in size and aspect ratio, we combine FPN and ASPP operation as our encoder-decoder structure in the semantic segmentation part, and propose a novel Adaptive Predictor Layer in the SSD. Pixel-Anchor detects scene text in a single network forward pass, no complex post-processing other than an efficient fusion Non-Maximum Suppression is involved. We have benchmarked the proposed Pixel-Anchor on the public datasets. Pixel-Anchor outperforms the competing methods in terms of text localization accuracy and run speed, more specifically, on the ICDAR 2015 dataset, the proposed algorithm achieves an F-score of 0.8768 at 10 FPS for 960 x 1728 resolution images.