 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionAD: Multi-modality Fusion for Prediction and Planning Tasks of Autonomous Driving
Aug 14, 2023



Building a multi-modality multi-task neural network toward accurate and robust performance is a de-facto standard in perception task of autonomous driving. However, leveraging such data from multiple sensors to jointly optimize the prediction and planning tasks remains largely unexplored. In this paper, we present FusionAD, to the best of our knowledge, the first unified framework that fuse the information from two most critical sensors, camera and LiDAR, goes beyond perception task. Concretely, we first build a transformer based multi-modality fusion network to effectively produce fusion based features. In constrast to camera-based end-to-end method UniAD, we then establish a fusion aided modality-aware prediction and status-aware planning modules, dubbed FMSPnP that take advantages of multi-modality features. We conduct extensive experiments on commonly used benchmark nuScenes dataset, our FusionAD achieves state-of-the-art performance and surpassing baselines on average 15% on perception tasks like detection and tracking, 10% on occupancy prediction accuracy, reducing prediction error from 0.708 to 0.389 in ADE score and reduces the collision rate from 0.31% to only 0.12%.
A Deep Learning Technique using a Sequence of Follow Up X-Rays for Disease classification
Mar 28, 2022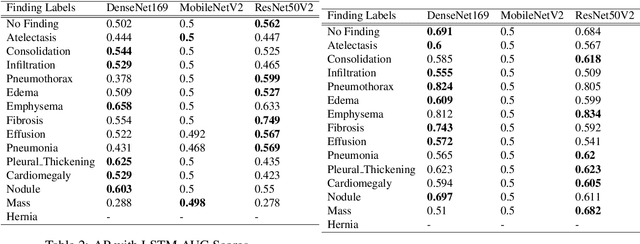
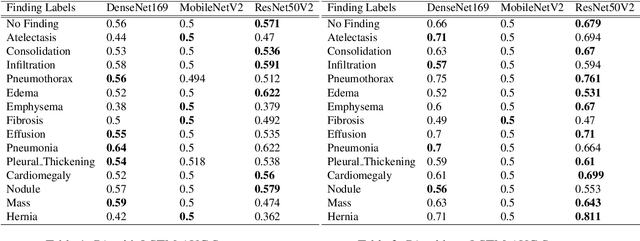
The ability to predict lung and heart based diseases using deep learning techniques is central to many researchers, particularly in the medical field around the world. In this paper, we present a unique outlook of a very familiar problem of disease classification using X-rays. We present a hypothesis that X-rays of patients included with the follow up history of their most recent three chest X-ray images would perform better in disease classification in comparison to one chest X-ray image input using an internal CNN to perform feature extraction. We have discovered that our generic deep learning architecture which we propose for solving this problem performs well with 3 input X ray images provided per sample for each patient. In this paper, we have also established that without additional layers before the output classification, the CNN models will improve the performance of predicting the disease labels for each patient. We have provided our results in ROC curves and AUROC scores. We define a fresh approach of collecting three X-ray images for training deep learning models, which we have concluded has clearly improved the performance of the models. We have shown that ResNet, in general, has a better result than any other CNN model used in the feature extraction phase. With our original approach to data pre-processing, image training, and pre-trained models, we believe that the current research will assist many medical institutions around the world, and this will improve the prediction of patients' symptoms and diagnose them with more accurate cure.
Interpretable Compositional Convolutional Neural Networks
Jul 09, 2021
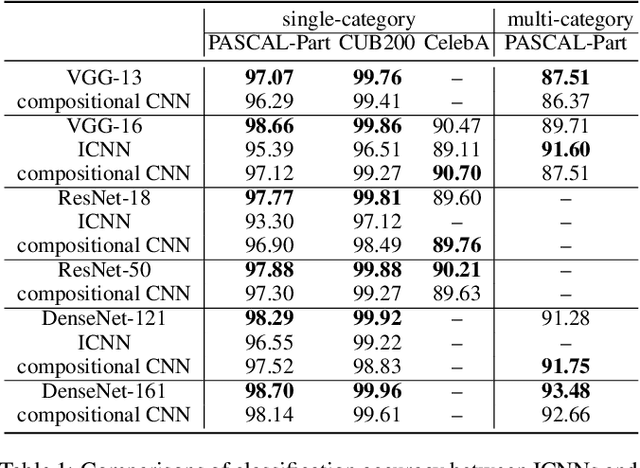
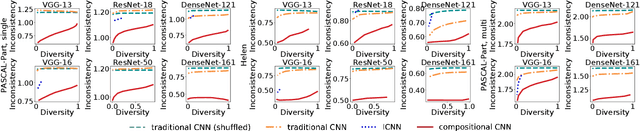

The reasonable definition of semantic interpretability presents the core challenge in explainable AI. This paper proposes a method to modify a traditional convolutional neural network (CNN) into an interpretable compositional CNN, in order to learn filters that encode meaningful visual patterns in intermediate convolutional layers. In a compositional CNN, each filter is supposed to consistently represent a specific compositional object part or image region with a clear meaning. The compositional CNN learns from image labels for classification without any annotations of parts or regions for supervision. Our method can be broadly applied to different types of CNNs. Experiments have demonstrated the effectiveness of our method.
Utility Analysis of Network Architectures for 3D Point Cloud Processing
Nov 20, 2019
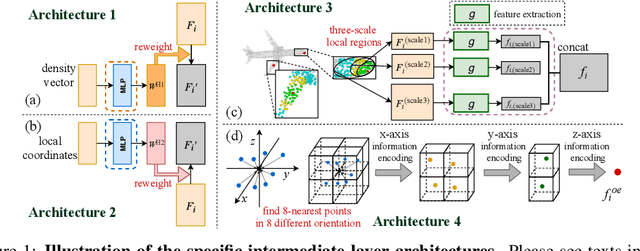

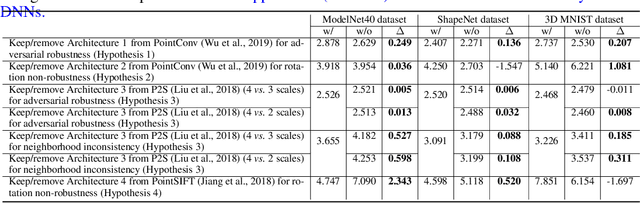
In this paper, we diagnose deep neural networks for 3D point cloud processing to explore utilities of different network architectures. We propose a number of hypotheses on the effects of specific network architectures on the representation capacity of DNNs. In order to prove the hypotheses, we design five metrics to diagnose various types of DNNs from the following perspectives, information discarding, information concentration, rotation robustness, adversarial robustness, and neighborhood inconsistency. We conduct comparative studies based on such metrics to verify the hypotheses. We further use the verified hypotheses to revise architectures of existing DNNs to improve their utilities. Experiments demonstrate the effectiveness of our method.
3D-Rotation-Equivariant Quaternion Neural Networks
Nov 20, 2019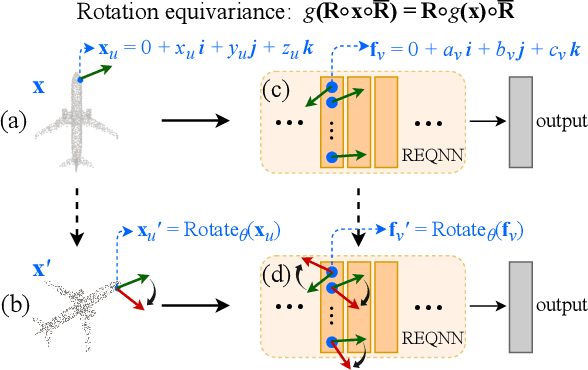
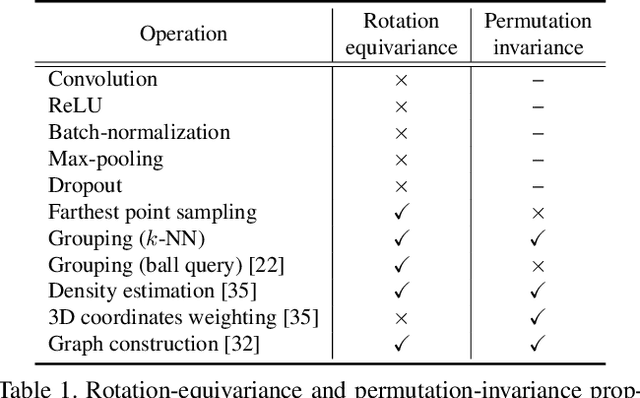
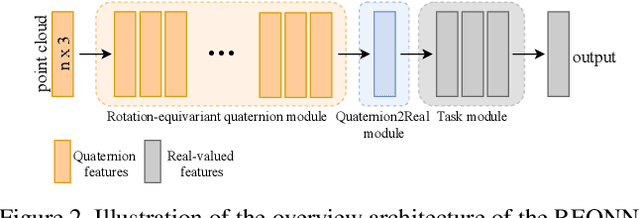

This paper proposes a set of rules to revise various neural networks for 3D point cloud processing to rotation-equivariant quaternion neural networks (REQNNs). We find that when a neural network uses quaternion features under certain conditions, the network feature naturally has the rotation-equivariance property. Rotation equivariance means that applying a specific rotation transformation to the input point cloud is equivalent to applying the same rotation transformation to all intermediate-layer quaternion features. Besides, the REQNN also ensures that the intermediate-layer features are invariant to the permutation of input points. Compared with the original neural network, the REQNN exhibits higher rotation robustness.