 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBohrium + SciMaster: Building the Infrastructure and Ecosystem for Agentic Science at Scale
Dec 23, 2025



AI agents are emerging as a practical way to run multi-step scientific workflows that interleave reasoning with tool use and verification, pointing to a shift from isolated AI-assisted steps toward \emph{agentic science at scale}. This shift is increasingly feasible, as scientific tools and models can be invoked through stable interfaces and verified with recorded execution traces, and increasingly necessary, as AI accelerates scientific output and stresses the peer-review and publication pipeline, raising the bar for traceability and credible evaluation. However, scaling agentic science remains difficult: workflows are hard to observe and reproduce; many tools and laboratory systems are not agent-ready; execution is hard to trace and govern; and prototype AI Scientist systems are often bespoke, limiting reuse and systematic improvement from real workflow signals. We argue that scaling agentic science requires an infrastructure-and-ecosystem approach, instantiated in Bohrium+SciMaster. Bohrium acts as a managed, traceable hub for AI4S assets -- akin to a HuggingFace of AI for Science -- that turns diverse scientific data, software, compute, and laboratory systems into agent-ready capabilities. SciMaster orchestrates these capabilities into long-horizon scientific workflows, on which scientific agents can be composed and executed. Between infrastructure and orchestration, a \emph{scientific intelligence substrate} organizes reusable models, knowledge, and components into executable building blocks for workflow reasoning and action, enabling composition, auditability, and improvement through use. We demonstrate this stack with eleven representative master agents in real workflows, achieving orders-of-magnitude reductions in end-to-end scientific cycle time and generating execution-grounded signals from real workloads at multi-million scale.
PhysMaster: Building an Autonomous AI Physicist for Theoretical and Computational Physics Research
Dec 22, 2025Advances in LLMs have produced agents with knowledge and operational capabilities comparable to human scientists, suggesting potential to assist, accelerate, and automate research. However, existing studies mainly evaluate such systems on well-defined benchmarks or general tasks like literature retrieval, limiting their end-to-end problem-solving ability in open scientific scenarios. This is particularly true in physics, which is abstract, mathematically intensive, and requires integrating analytical reasoning with code-based computation. To address this, we propose PhysMaster, an LLM-based agent functioning as an autonomous theoretical and computational physicist. PhysMaster couples absract reasoning with numerical computation and leverages LANDAU, the Layered Academic Data Universe, which preserves retrieved literature, curated prior knowledge, and validated methodological traces, enhancing decision reliability and stability. It also employs an adaptive exploration strategy balancing efficiency and open-ended exploration, enabling robust performance in ultra-long-horizon tasks. We evaluate PhysMaster on problems from high-energy theory, condensed matter theory to astrophysics, including: (i) acceleration, compressing labor-intensive research from months to hours; (ii) automation, autonomously executing hypothesis-driven loops ; and (iii) autonomous discovery, independently exploring open problems.
BrowseMaster: Towards Scalable Web Browsing via Tool-Augmented Programmatic Agent Pair
Aug 12, 2025Effective information seeking in the vast and ever-growing digital landscape requires balancing expansive search with strategic reasoning. Current large language model (LLM)-based agents struggle to achieve this balance due to limitations in search breadth and reasoning depth, where slow, serial querying restricts coverage of relevant sources and noisy raw inputs disrupt the continuity of multi-step reasoning. To address these challenges, we propose BrowseMaster, a scalable framework built around a programmatically augmented planner-executor agent pair. The planner formulates and adapts search strategies based on task constraints, while the executor conducts efficient, targeted retrieval to supply the planner with concise, relevant evidence. This division of labor preserves coherent, long-horizon reasoning while sustaining broad and systematic exploration, overcoming the trade-off that limits existing agents. Extensive experiments on challenging English and Chinese benchmarks show that BrowseMaster consistently outperforms open-source and proprietary baselines, achieving scores of 30.0 on BrowseComp-en and 46.5 on BrowseComp-zh, which demonstrates its strong capability in complex, reasoning-heavy information-seeking tasks at scale.
RoCo-Sim: Enhancing Roadside Collaborative Perception through Foreground Simulation
Mar 13, 2025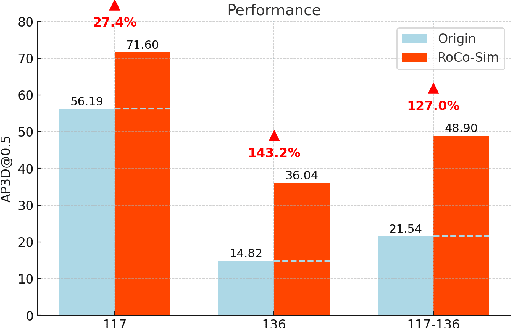
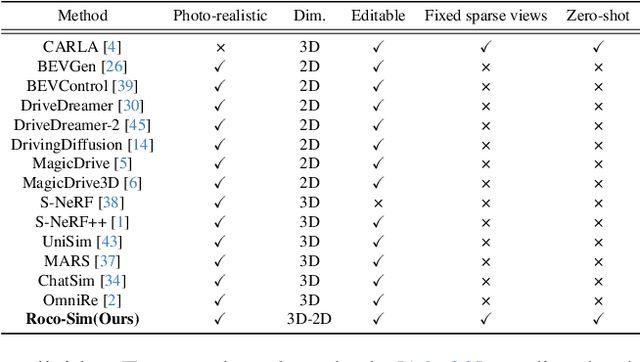


Roadside Collaborative Perception refers to a system where multiple roadside units collaborate to pool their perceptual data, assisting vehicles in enhancing their environmental awareness. Existing roadside perception methods concentrate on model design but overlook data issues like calibration errors, sparse information, and multi-view consistency, leading to poor performance on recent published datasets. To significantly enhance roadside collaborative perception and address critical data issues, we present the first simulation framework RoCo-Sim for road-side collaborative perception. RoCo-Sim is capable of generating diverse, multi-view consistent simulated roadside data through dynamic foreground editing and full-scene style transfer of a single image. RoCo-Sim consists of four components: (1) Camera Extrinsic Optimization ensures accurate 3D to 2D projection for roadside cameras; (2) A novel Multi-View Occlusion-Aware Sampler (MOAS) determines the placement of diverse digital assets within 3D space; (3) DepthSAM innovatively models foreground-background relationships from single-frame fixed-view images, ensuring multi-view consistency of foreground; and (4) Scalable Post-Processing Toolkit generates more realistic and enriched scenes through style transfer and other enhancements. RoCo-Sim significantly improves roadside 3D object detection, outperforming SOTA methods by 83.74 on Rcooper-Intersection and 83.12 on TUMTraf-V2X for AP70. RoCo-Sim fills a critical gap in roadside perception simulation. Code and pre-trained models will be released soon: https://github.com/duyuwen-duen/RoCo-Sim
ChatDyn: Language-Driven Multi-Actor Dynamics Generation in Street Scenes
Dec 11, 2024Generating realistic and interactive dynamics of traffic participants according to specific instruction is critical for street scene simulation. However, there is currently a lack of a comprehensive method that generates realistic dynamics of different types of participants including vehicles and pedestrians, with different kinds of interactions between them. In this paper, we introduce ChatDyn, the first system capable of generating interactive, controllable and realistic participant dynamics in street scenes based on language instructions. To achieve precise control through complex language, ChatDyn employs a multi-LLM-agent role-playing approach, which utilizes natural language inputs to plan the trajectories and behaviors for different traffic participants. To generate realistic fine-grained dynamics based on the planning, ChatDyn designs two novel executors: the PedExecutor, a unified multi-task executor that generates realistic pedestrian dynamics under different task plannings; and the VehExecutor, a physical transition-based policy that generates physically plausible vehicle dynamics. Extensive experiments show that ChatDyn can generate realistic driving scene dynamics with multiple vehicles and pedestrians, and significantly outperforms previous methods on subtasks. Code and model will be available at https://vfishc.github.io/chatdyn.