 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhotovoltaic Defect Image Generator with Boundary Alignment Smoothing Constraint for Domain Shift Mitigation
May 09, 2025Accurate defect detection of photovoltaic (PV) cells is critical for ensuring quality and efficiency in intelligent PV manufacturing systems. However, the scarcity of rich defect data poses substantial challenges for effective model training. While existing methods have explored generative models to augment datasets, they often suffer from instability, limited diversity, and domain shifts. To address these issues, we propose PDIG, a Photovoltaic Defect Image Generator based on Stable Diffusion (SD). PDIG leverages the strong priors learned from large-scale datasets to enhance generation quality under limited data. Specifically, we introduce a Semantic Concept Embedding (SCE) module that incorporates text-conditioned priors to capture the relational concepts between defect types and their appearances. To further enrich the domain distribution, we design a Lightweight Industrial Style Adaptor (LISA), which injects industrial defect characteristics into the SD model through cross-disentangled attention. At inference, we propose a Text-Image Dual-Space Constraints (TIDSC) module, enforcing the quality of generated images via positional consistency and spatial smoothing alignment. Extensive experiments demonstrate that PDIG achieves superior realism and diversity compared to state-of-the-art methods. Specifically, our approach improves Frechet Inception Distance (FID) by 19.16 points over the second-best method and significantly enhances the performance of downstream defect detection tasks.
OSDM-MReg: Multimodal Image Registration based One Step Diffusion Model
Apr 08, 2025Multimodal remote sensing image registration aligns images from different sensors for data fusion and analysis. However, current methods often fail to extract modality-invariant features when aligning image pairs with large nonlinear radiometric differences. To address this issues, we propose OSDM-MReg, a novel multimodal image registration framework based image-to-image translation to eliminate the gap of multimodal images. Firstly, we propose a novel one-step unaligned target-guided conditional denoising diffusion probabilistic models(UTGOS-CDDPM)to translate multimodal images into a unified domain. In the inference stage, traditional conditional DDPM generate translated source image by a large number of iterations, which severely slows down the image registration task. To address this issues, we use the unaligned traget image as a condition to promote the generation of low-frequency features of the translated source image. Furthermore, during the training stage, we add the inverse process of directly predicting the translated image to ensure that the translated source image can be generated in one step during the testing stage. Additionally, to supervised the detail features of translated source image, we propose a new perceptual loss that focuses on the high-frequency feature differences between the translated and ground-truth images. Finally, a multimodal multiscale image registration network (MM-Reg) fuse the multimodal feature of the unimodal images and multimodal images by proposed multimodal feature fusion strategy. Experiments demonstrate superior accuracy and efficiency across various multimodal registration tasks, particularly for SAR-optical image pairs.
Multi-Domain Features Guided Supervised Contrastive Learning for Radar Target Detection
Dec 17, 2024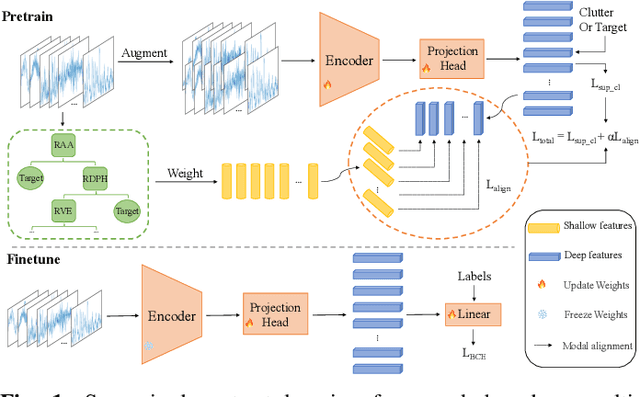
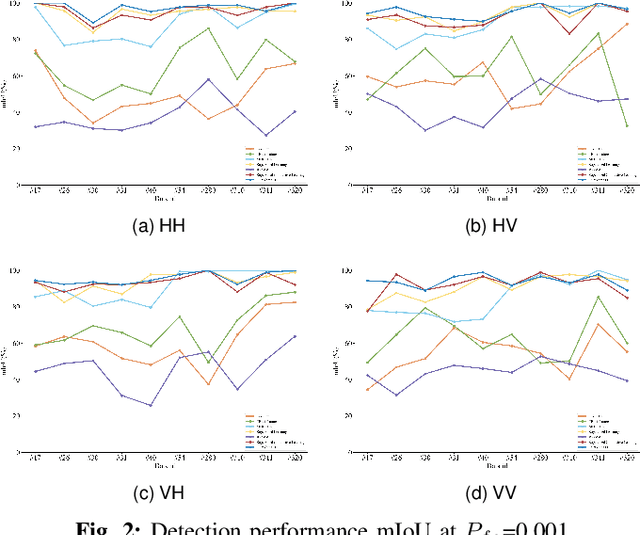
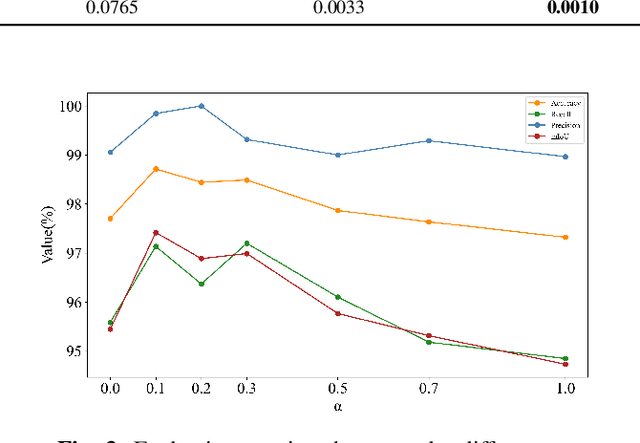
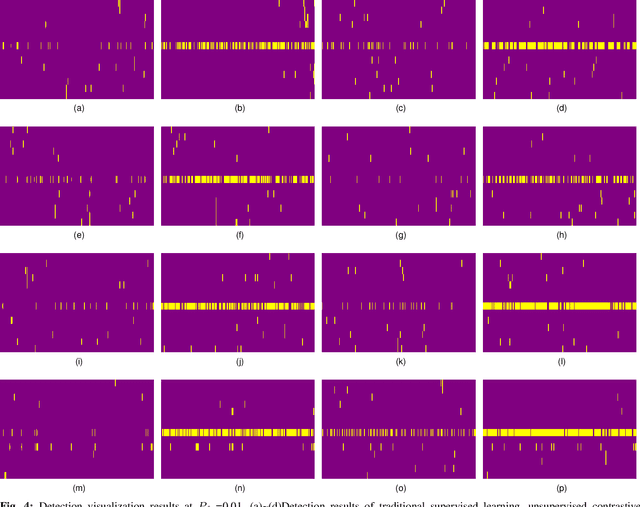
Detecting small targets in sea clutter is challenging due to dynamic maritime conditions. Existing solutions either model sea clutter for detection or extract target features based on clutter-target echo differences, including statistical and deep features. While more common, the latter often excels in controlled scenarios but struggles with robust detection and generalization in diverse environments, limiting practical use. In this letter, we propose a multi-domain features guided supervised contrastive learning (MDFG_SCL) method, which integrates statistical features derived from multi-domain differences with deep features obtained through supervised contrastive learning, thereby capturing both low-level domain-specific variations and high-level semantic information. This comprehensive feature integration enables the model to effectively distinguish between small targets and sea clutter, even under challenging conditions. Experiments conducted on real-world datasets demonstrate that the proposed shallow-to-deep detector not only achieves effective identification of small maritime targets but also maintains superior detection performance across varying sea conditions, outperforming the mainstream unsupervised contrastive learning and supervised contrastive learning methods.