 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Layer Normalization for Universal Approximation
May 19, 2025Universal approximation theorem (UAT) is a fundamental theory for deep neural networks (DNNs), demonstrating their powerful representation capacity to represent and approximate any function. The analyses and proofs of UAT are based on traditional network with only linear and nonlinear activation functions, but omitting normalization layers, which are commonly employed to enhance the training of modern networks. This paper conducts research on UAT of DNNs with normalization layers for the first time. We theoretically prove that an infinitely wide network -- composed solely of parallel layer normalization (PLN) and linear layers -- has universal approximation capacity. Additionally, we investigate the minimum number of neurons required to approximate $L$-Lipchitz continuous functions, with a single hidden-layer network. We compare the approximation capacity of PLN with traditional activation functions in theory. Different from the traditional activation functions, we identify that PLN can act as both activation function and normalization in deep neural networks at the same time. We also find that PLN can improve the performance when replacing LN in transformer architectures, which reveals the potential of PLN used in neural architectures.
One Snapshot is All You Need: A Generalized Method for mmWave Signal Generation
Mar 27, 2025Wireless sensing systems, particularly those using mmWave technology, offer distinct advantages over traditional vision-based approaches, such as enhanced privacy and effectiveness in poor lighting conditions. These systems, leveraging FMCW signals, have shown success in human-centric applications like localization, gesture recognition, and so on. However, comprehensive mmWave datasets for diverse applications are scarce, often constrained by pre-processed signatures (e.g., point clouds or RA heatmaps) and inconsistent annotation formats. To overcome these limitations, we propose mmGen, a novel and generalized framework tailored for full-scene mmWave signal generation. By constructing physical signal transmission models, mmGen synthesizes human-reflected and environment-reflected mmWave signals from the constructed 3D meshes. Additionally, we incorporate methods to account for material properties, antenna gains, and multipath reflections, enhancing the realism of the synthesized signals. We conduct extensive experiments using a prototype system with commercial mmWave devices and Kinect sensors. The results show that the average similarity of Range-Angle and micro-Doppler signatures between the synthesized and real-captured signals across three different environments exceeds 0.91 and 0.89, respectively, demonstrating the effectiveness and practical applicability of mmGen.
Parametric Reshaping of Portraits in Videos
May 05, 2022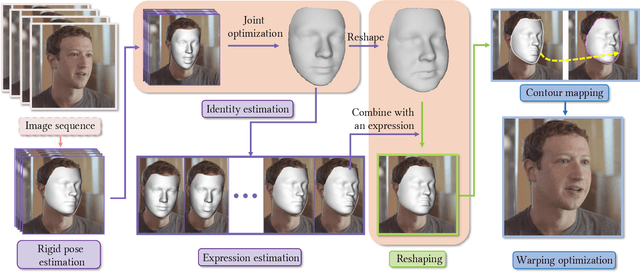

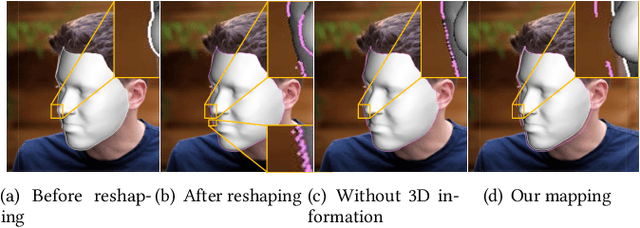

Sharing short personalized videos to various social media networks has become quite popular in recent years. This raises the need for digital retouching of portraits in videos. However, applying portrait image editing directly on portrait video frames cannot generate smooth and stable video sequences. To this end, we present a robust and easy-to-use parametric method to reshape the portrait in a video to produce smooth retouched results. Given an input portrait video, our method consists of two main stages: stabilized face reconstruction, and continuous video reshaping. In the first stage, we start by estimating face rigid pose transformations across video frames. Then we jointly optimize multiple frames to reconstruct an accurate face identity, followed by recovering face expressions over the entire video. In the second stage, we first reshape the reconstructed 3D face using a parametric reshaping model reflecting the weight change of the face, and then utilize the reshaped 3D face to guide the warping of video frames. We develop a novel signed distance function based dense mapping method for the warping between face contours before and after reshaping, resulting in stable warped video frames with minimum distortions. In addition, we use the 3D structure of the face to correct the dense mapping to achieve temporal consistency. We generate the final result by minimizing the background distortion through optimizing a content-aware warping mesh. Extensive experiments show that our method is able to create visually pleasing results by adjusting a simple reshaping parameter, which facilitates portrait video editing for social media and visual effects.