 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCASA: A Bridge Between Gradient of Policy Improvement and Policy Evaluation
Paper and Code
May 27, 2021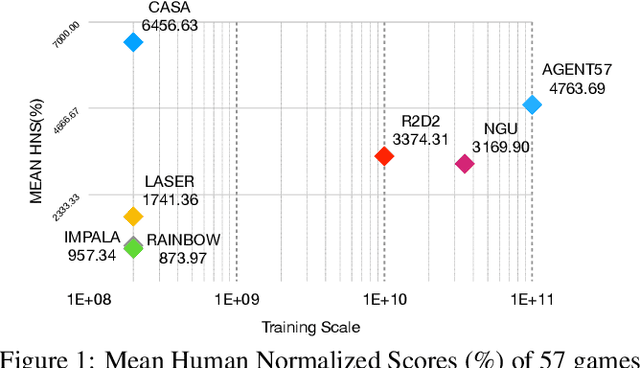
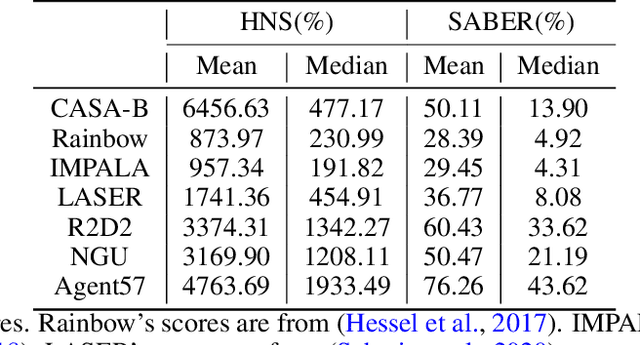
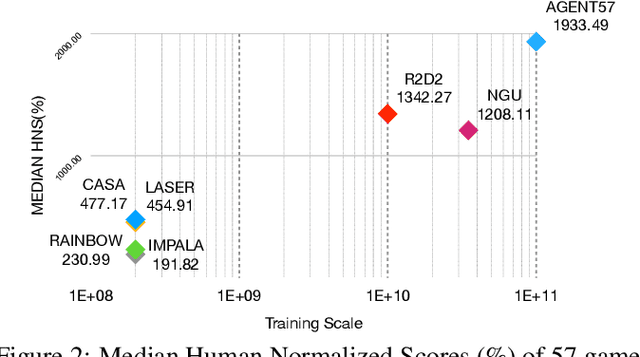

This paper introduces a novel design of model-free reinforcement learning, CASA, Critic AS an Actor. CASA follows the actor-critic framework that estimates state-value, state-action-value and policy simultaneously. We prove that CASA integrates a consistent path for the policy evaluation and the policy improvement, which completely eliminates the gradient conflict between the policy improvement and the policy evaluation. The policy evaluation is equivalent to a compensational policy improvement, which alleviates the function approximation error, and is also equivalent to an entropy-regularized policy improvement, which prevents the policy from being trapped into a suboptimal solution. Building on this design, an expectation-correct Doubly Robust Trace is introduced to learn state-value and state-action-value, and the convergence is guaranteed. Our experiments show that the design achieves State-Of-The-Art on Arcade Learning Environment.