 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePareto-Guided Optimization for Uncertainty-Aware Medical Image Segmentation
Jan 27, 2026Uncertainty in medical image segmentation is inherently non-uniform, with boundary regions exhibiting substantially higher ambiguity than interior areas. Conventional training treats all pixels equally, leading to unstable optimization during early epochs when predictions are unreliable. We argue that this instability hinders convergence toward Pareto-optimal solutions and propose a region-wise curriculum strategy that prioritizes learning from certain regions and gradually incorporates uncertain ones, reducing gradient variance. Methodologically, we introduce a Pareto-consistent loss that balances trade-offs between regional uncertainties by adaptively reshaping the loss landscape and constraining convergence dynamics between interior and boundary regions; this guides the model toward Pareto-approximate solutions. To address boundary ambiguity, we further develop a fuzzy labeling mechanism that maintains binary confidence in non-boundary areas while enabling smooth transitions near boundaries, stabilizing gradients, and expanding flat regions in the loss surface. Experiments on brain metastasis and non-metastatic tumor segmentation show consistent improvements across multiple configurations, with our method outperforming traditional crisp-set approaches in all tumor subregions.
Learning Compact Neural Networks with Deep Overparameterised Multitask Learning
Aug 25, 2023Compact neural network offers many benefits for real-world applications. However, it is usually challenging to train the compact neural networks with small parameter sizes and low computational costs to achieve the same or better model performance compared to more complex and powerful architecture. This is particularly true for multitask learning, with different tasks competing for resources. We present a simple, efficient and effective multitask learning overparameterisation neural network design by overparameterising the model architecture in training and sharing the overparameterised model parameters more effectively across tasks, for better optimisation and generalisation. Experiments on two challenging multitask datasets (NYUv2 and COCO) demonstrate the effectiveness of the proposed method across various convolutional networks and parameter sizes.
An Entropy Regularization Free Mechanism for Policy-based Reinforcement Learning
Jun 01, 2021



Policy-based reinforcement learning methods suffer from the policy collapse problem. We find valued-based reinforcement learning methods with {\epsilon}-greedy mechanism are capable of enjoying three characteristics, Closed-form Diversity, Objective-invariant Exploration and Adaptive Trade-off, which help value-based methods avoid the policy collapse problem. However, there does not exist a parallel mechanism for policy-based methods that achieves all three characteristics. In this paper, we propose an entropy regularization free mechanism that is designed for policy-based methods, which achieves Closed-form Diversity, Objective-invariant Exploration and Adaptive Trade-off. Our experiments show that our mechanism is super sample-efficient for policy-based methods and boosts a policy-based baseline to a new State-Of-The-Art on Arcade Learning Environment.
CASA: A Bridge Between Gradient of Policy Improvement and Policy Evaluation
May 27, 2021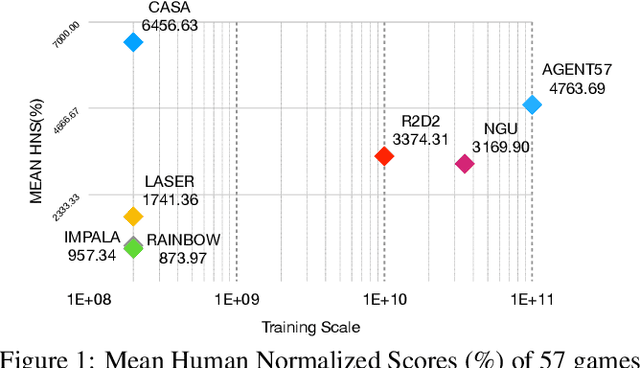
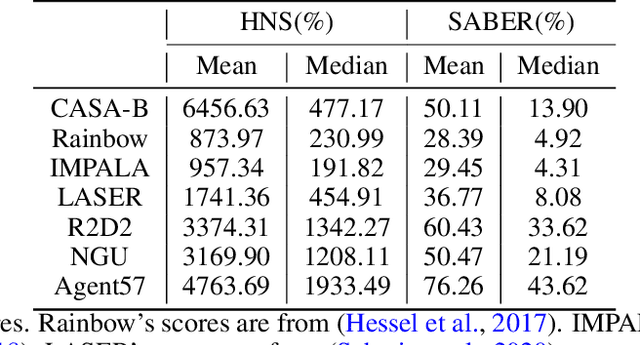
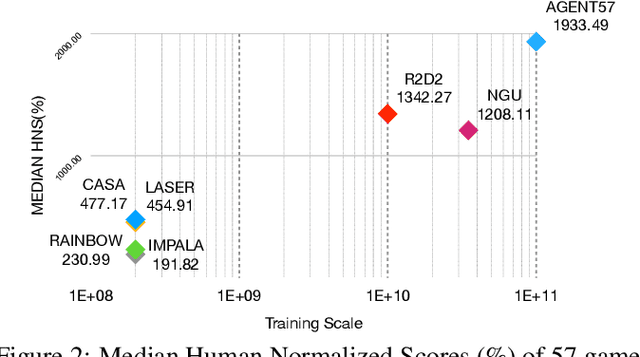

This paper introduces a novel design of model-free reinforcement learning, CASA, Critic AS an Actor. CASA follows the actor-critic framework that estimates state-value, state-action-value and policy simultaneously. We prove that CASA integrates a consistent path for the policy evaluation and the policy improvement, which completely eliminates the gradient conflict between the policy improvement and the policy evaluation. The policy evaluation is equivalent to a compensational policy improvement, which alleviates the function approximation error, and is also equivalent to an entropy-regularized policy improvement, which prevents the policy from being trapped into a suboptimal solution. Building on this design, an expectation-correct Doubly Robust Trace is introduced to learn state-value and state-action-value, and the convergence is guaranteed. Our experiments show that the design achieves State-Of-The-Art on Arcade Learning Environment.