 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove the efficiency of deep reinforcement learning through semantic exploration guided by natural language
Paper and Code
Sep 21, 2023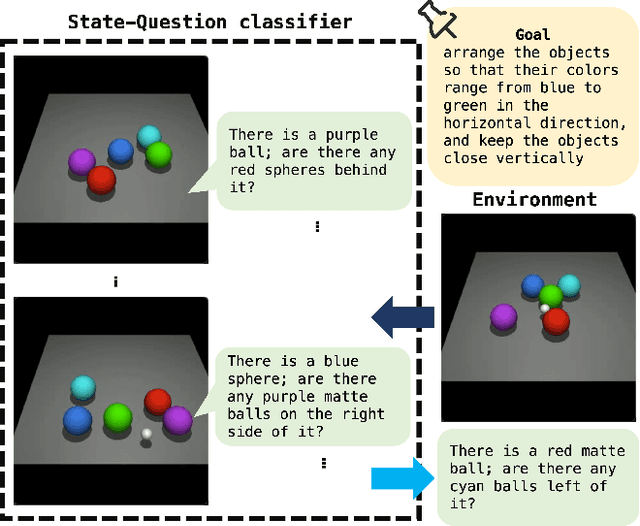
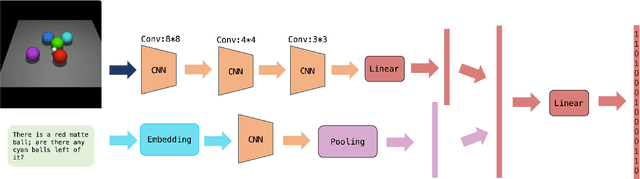
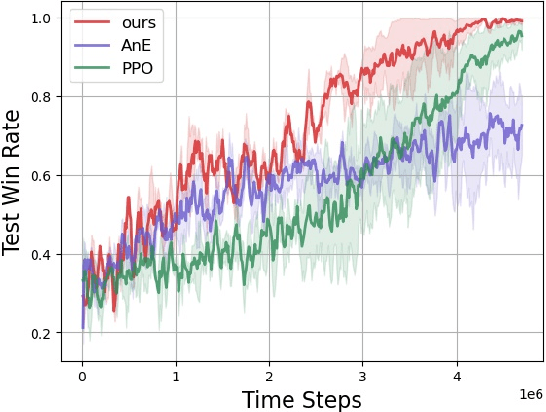
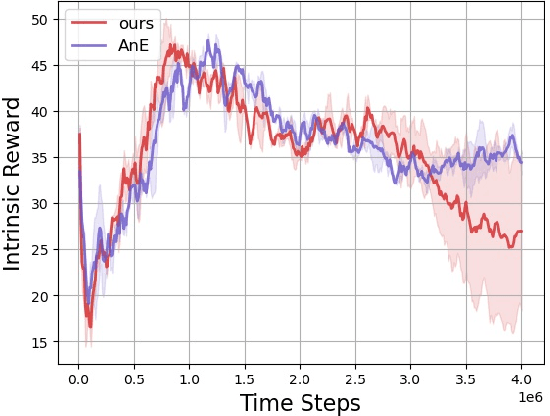
Reinforcement learning is a powerful technique for learning from trial and error, but it often requires a large number of interactions to achieve good performance. In some domains, such as sparse-reward tasks, an oracle that can provide useful feedback or guidance to the agent during the learning process is really of great importance. However, querying the oracle too frequently may be costly or impractical, and the oracle may not always have a clear answer for every situation. Therefore, we propose a novel method for interacting with the oracle in a selective and efficient way, using a retrieval-based approach. We assume that the interaction can be modeled as a sequence of templated questions and answers, and that there is a large corpus of previous interactions available. We use a neural network to encode the current state of the agent and the oracle, and retrieve the most relevant question from the corpus to ask the oracle. We then use the oracle's answer to update the agent's policy and value function. We evaluate our method on an object manipulation task. We show that our method can significantly improve the efficiency of RL by reducing the number of interactions needed to reach a certain level of performance, compared to baselines that do not use the oracle or use it in a naive way.