 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning with Exploration: Addressing Dynamics Bottleneck in Model-based Reinforcement Learning
Paper and Code
Oct 24, 2020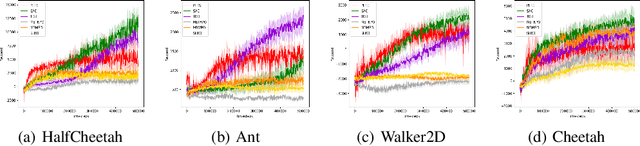

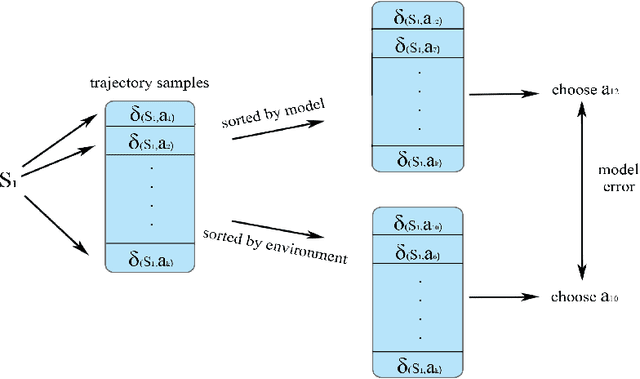
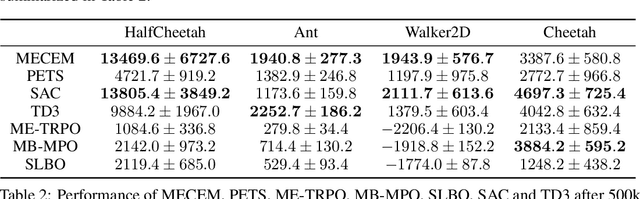
Model-based reinforcement learning is a framework in which an agent learns an environment model, makes planning and decision-making in this model, and finally interacts with the real environment. Model-based reinforcement learning has high sample efficiency compared with model-free reinforcement learning, and shows great potential in the real-world application. However, model-based reinforcement learning has been plagued by dynamics bottleneck. Dynamics bottleneck is the phenomenon that when the timestep to interact with the environment increases, the reward of the agent falls into the local optimum instead of increasing. In this paper, we analyze and explain how the coupling relationship between model and policy causes the dynamics bottleneck and shows improving the exploration ability of the agent can alleviate this issue. We then propose a new planning algorithm called Maximum Entropy Cross-Entropy Method (MECEM). MECEM can improve the agent's exploration ability by maximizing the distribution of action entropy in the planning process. We conduct experiments on fourteen well-recognized benchmark environments such as HalfCheetah, Ant and Swimmer. The results verify that our approach obtains the state-of-the-art performance on eleven benchmark environments and can effectively alleviate dynamics bottleneck on HalfCheetah, Ant and Walker2D.