 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWGSR-Bench: Wargame-based Game-theoretic Strategic Reasoning Benchmark for Large Language Models
Jun 12, 2025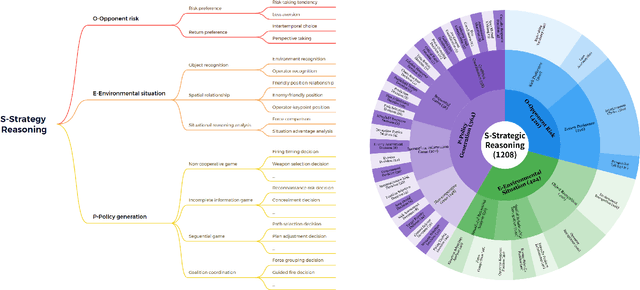
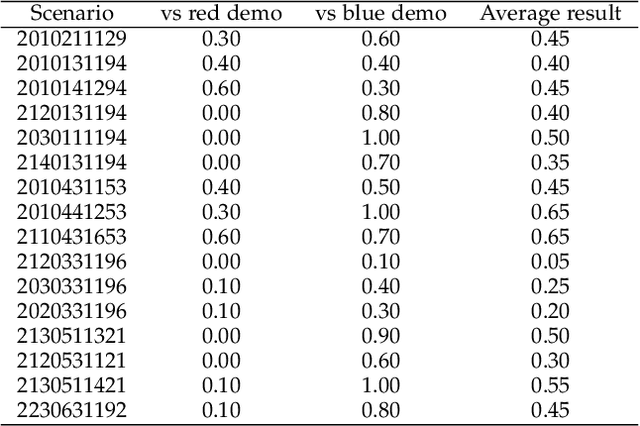
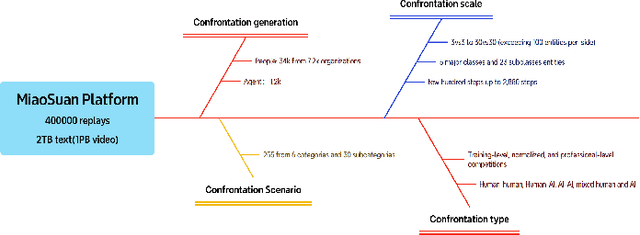
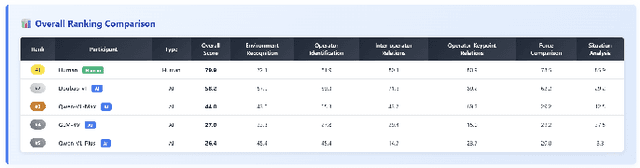
Recent breakthroughs in Large Language Models (LLMs) have led to a qualitative leap in artificial intelligence' s performance on reasoning tasks, particularly demonstrating remarkable capabilities in mathematical, symbolic, and commonsense reasoning. However, as a critical component of advanced human cognition, strategic reasoning, i.e., the ability to assess multi-agent behaviors in dynamic environments, formulate action plans, and adapt strategies, has yet to be systematically evaluated or modeled. To address this gap, this paper introduces WGSR-Bench, the first strategy reasoning benchmark for LLMs using wargame as its evaluation environment. Wargame, a quintessential high-complexity strategic scenario, integrates environmental uncertainty, adversarial dynamics, and non-unique strategic choices, making it an effective testbed for assessing LLMs' capabilities in multi-agent decision-making, intent inference, and counterfactual reasoning. WGSR-Bench designs test samples around three core tasks, i.e., Environmental situation awareness, Opponent risk modeling and Policy generation, which serve as the core S-POE architecture, to systematically assess main abilities of strategic reasoning. Finally, an LLM-based wargame agent is designed to integrate these parts for a comprehensive strategy reasoning assessment. With WGSR-Bench, we hope to assess the strengths and limitations of state-of-the-art LLMs in game-theoretic strategic reasoning and to advance research in large model-driven strategic intelligence.
Efficient-VQGAN: Towards High-Resolution Image Generation with Efficient Vision Transformers
Oct 09, 2023Vector-quantized image modeling has shown great potential in synthesizing high-quality images. However, generating high-resolution images remains a challenging task due to the quadratic computational overhead of the self-attention process. In this study, we seek to explore a more efficient two-stage framework for high-resolution image generation with improvements in the following three aspects. (1) Based on the observation that the first quantization stage has solid local property, we employ a local attention-based quantization model instead of the global attention mechanism used in previous methods, leading to better efficiency and reconstruction quality. (2) We emphasize the importance of multi-grained feature interaction during image generation and introduce an efficient attention mechanism that combines global attention (long-range semantic consistency within the whole image) and local attention (fined-grained details). This approach results in faster generation speed, higher generation fidelity, and improved resolution. (3) We propose a new generation pipeline incorporating autoencoding training and autoregressive generation strategy, demonstrating a better paradigm for image synthesis. Extensive experiments demonstrate the superiority of our approach in high-quality and high-resolution image reconstruction and generation.