 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Modalities of Text: Visual and Textual Generative Pre-training
Apr 17, 2024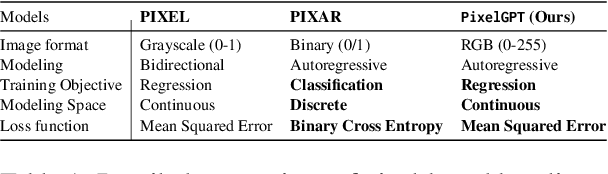
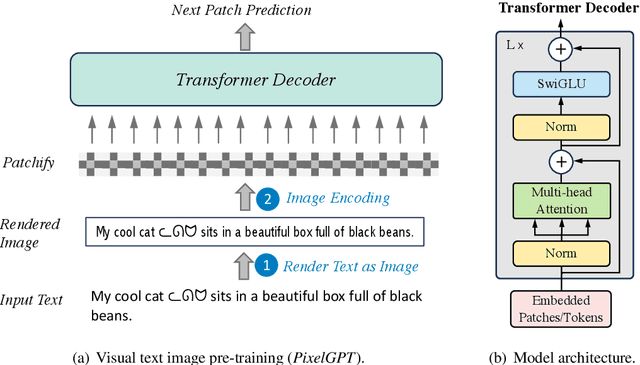
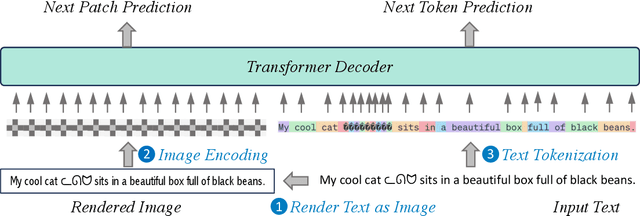

Harnessing visual texts represents a burgeoning frontier in the evolution of language modeling. In this paper, we introduce a novel pre-training framework for a suite of pixel-based autoregressive language models, pre-training on a corpus of over 400 million documents rendered as RGB images. Our approach is characterized by a dual-modality training regimen, engaging both visual data through next patch prediction with a regression head and textual data via next token prediction with a classification head. This study is particularly focused on investigating the synergistic interplay between visual and textual modalities of language. Our comprehensive evaluation across a diverse array of benchmarks reveals that the confluence of visual and textual data substantially augments the efficacy of pixel-based language models. Notably, our findings show that a unidirectional pixel-based model, devoid of textual data during training, can match the performance levels of advanced bidirectional pixel-based models on various language understanding benchmarks. This work highlights the considerable untapped potential of integrating visual and textual information for language modeling purposes. We will release our code, data, and checkpoints to inspire further research advancement.
On Training Data Influence of GPT Models
Apr 11, 2024



Amidst the rapid advancements in generative language models, the investigation of how training data shapes the performance of GPT models is still emerging. This paper presents GPTfluence, a novel approach that leverages a featurized simulation to assess the impact of training examples on the training dynamics of GPT models. Our approach not only traces the influence of individual training instances on performance trajectories, such as loss and other key metrics, on targeted test points but also enables a comprehensive comparison with existing methods across various training scenarios in GPT models, ranging from 14 million to 2.8 billion parameters, across a range of downstream tasks. Contrary to earlier methods that struggle with generalization to new data, GPTfluence introduces a parameterized simulation of training dynamics, demonstrating robust generalization capabilities to unseen training data. This adaptability is evident across both fine-tuning and instruction-tuning scenarios, spanning tasks in natural language understanding and generation. We will make our code and data publicly available.
UBARv2: Towards Mitigating Exposure Bias in Task-Oriented Dialogs
Sep 15, 2022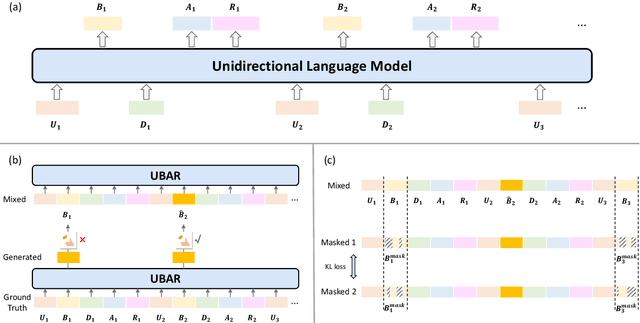
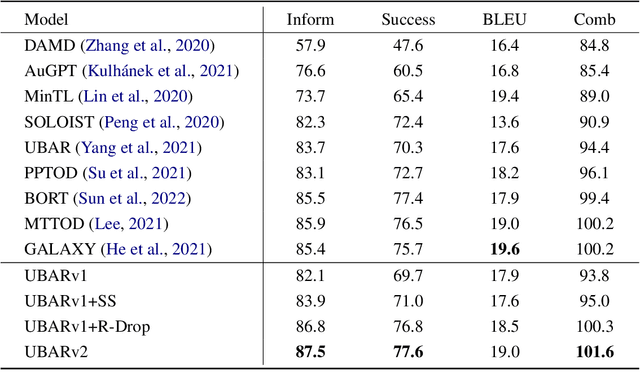
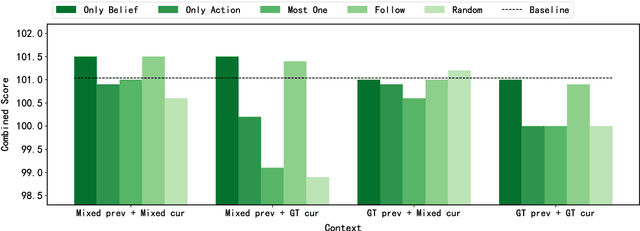

This paper studies the exposure bias problem in task-oriented dialog systems, where the model's generated content over multiple turns drives the dialog context away from the ground-truth distribution at training time, introducing error propagation and damaging the robustness of the TOD system. To bridge the gap between training and inference for multi-turn task-oriented dialogs, we propose session-level sampling which explicitly exposes the model to sampled generated content of dialog context during training. Additionally, we employ a dropout-based consistency regularization with the masking strategy R-Mask to further improve the robustness and performance of the model. The proposed UBARv2 achieves state-of-the-art performance on the standardized evaluation benchmark MultiWOZ and extensive experiments show the effectiveness of the proposed methods.