 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMA-RLHF: Reinforcement Learning from Human Feedback with Macro Actions
Oct 03, 2024



Reinforcement learning from human feedback (RLHF) has demonstrated effectiveness in aligning large language models (LLMs) with human preferences. However, token-level RLHF suffers from the credit assignment problem over long sequences, where delayed rewards make it challenging for the model to discern which actions contributed to successful outcomes. This hinders learning efficiency and slows convergence. In this paper, we propose MA-RLHF, a simple yet effective RLHF framework that incorporates macro actions -- sequences of tokens or higher-level language constructs -- into the learning process. By operating at this higher level of abstraction, our approach reduces the temporal distance between actions and rewards, facilitating faster and more accurate credit assignment. This results in more stable policy gradient estimates and enhances learning efficiency within each episode, all without increasing computational complexity during training or inference. We validate our approach through extensive experiments across various model sizes and tasks, including text summarization, dialogue generation, question answering, and program synthesis. Our method achieves substantial performance improvements over standard RLHF, with performance gains of up to 30% in text summarization and code generation, 18% in dialogue, and 8% in question answering tasks. Notably, our approach reaches parity with vanilla RLHF 1.7x to 2x faster in terms of training time and continues to outperform it with further training. We will make our code and data publicly available at https://github.com/ernie-research/MA-RLHF .
MQuinE: a cure for "Z-paradox" in knowledge graph embedding models
Feb 07, 2024



Knowledge graph embedding (KGE) models achieved state-of-the-art results on many knowledge graph tasks including link prediction and information retrieval. Despite the superior performance of KGE models in practice, we discover a deficiency in the expressiveness of some popular existing KGE models called \emph{Z-paradox}. Motivated by the existence of Z-paradox, we propose a new KGE model called \emph{MQuinE} that does not suffer from Z-paradox while preserves strong expressiveness to model various relation patterns including symmetric/asymmetric, inverse, 1-N/N-1/N-N, and composition relations with theoretical justification. Experiments on real-world knowledge bases indicate that Z-paradox indeed degrades the performance of existing KGE models, and can cause more than 20\% accuracy drop on some challenging test samples. Our experiments further demonstrate that MQuinE can mitigate the negative impact of Z-paradox and outperform existing KGE models by a visible margin on link prediction tasks.
A dual approach for federated learning
Feb 04, 2022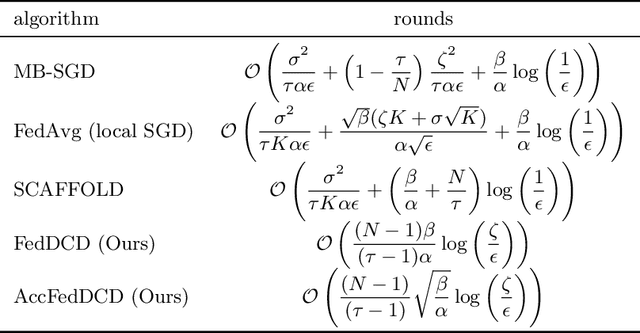
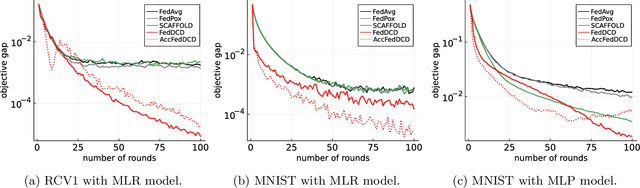
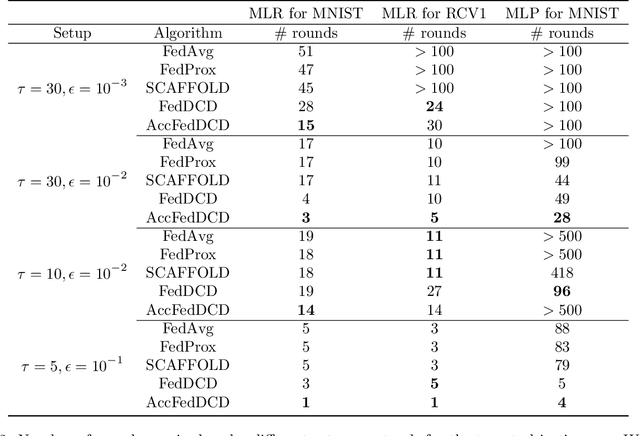
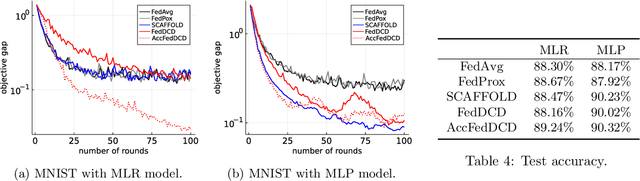
We study the federated optimization problem from a dual perspective and propose a new algorithm termed federated dual coordinate descent (FedDCD), which is based on a type of coordinate descent method developed by Necora et al.[Journal of Optimization Theory and Applications, 2017]. Additionally, we enhance the FedDCD method with inexact gradient oracles and Nesterov's acceleration. We demonstrate theoretically that our proposed approach achieves better convergence rates than the state-of-the-art primal federated optimization algorithms under certain situations. Numerical experiments on real-world datasets support our analysis.
Fair and efficient contribution valuation for vertical federated learning
Jan 07, 2022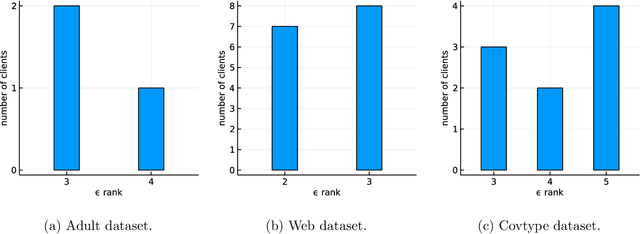
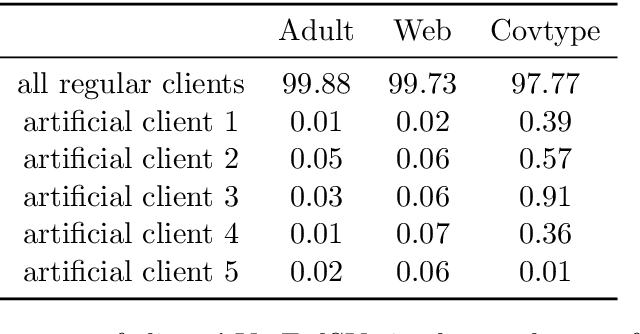
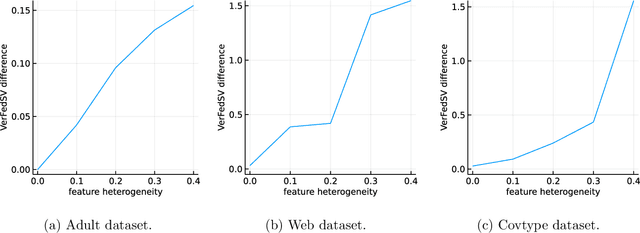
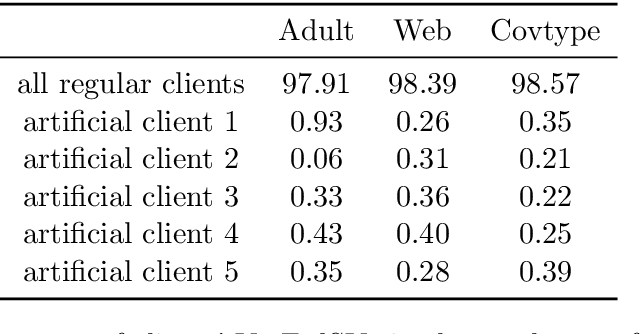
Federated learning is a popular technology for training machine learning models on distributed data sources without sharing data. Vertical federated learning or feature-based federated learning applies to the cases that different data sources share the same sample ID space but differ in feature space. To ensure the data owners' long-term engagement, it is critical to objectively assess the contribution from each data source and recompense them accordingly. The Shapley value (SV) is a provably fair contribution valuation metric originated from cooperative game theory. However, computing the SV requires extensively retraining the model on each subset of data sources, which causes prohibitively high communication costs in federated learning. We propose a contribution valuation metric called vertical federated Shapley value (VerFedSV) based on SV. We show that VerFedSV not only satisfies many desirable properties for fairness but is also efficient to compute, and can be adapted to both synchronous and asynchronous vertical federated learning algorithms. Both theoretical analysis and extensive experimental results verify the fairness, efficiency, and adaptability of VerFedSV.
Improving Fairness for Data Valuation in Federated Learning
Sep 19, 2021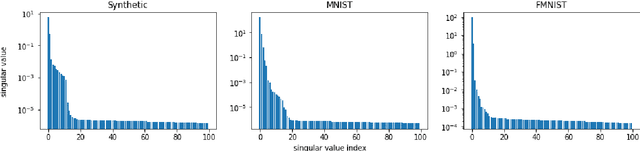
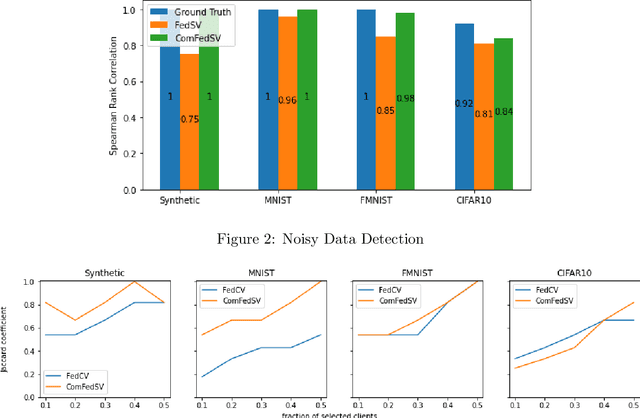
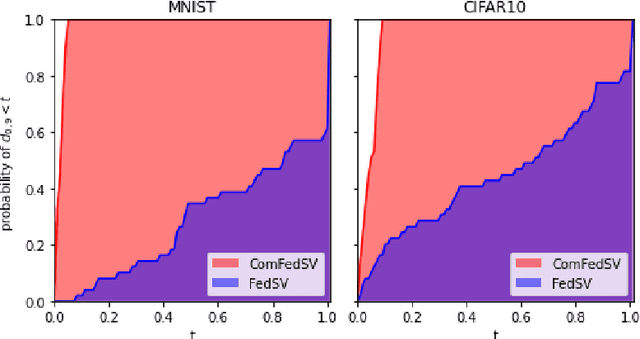
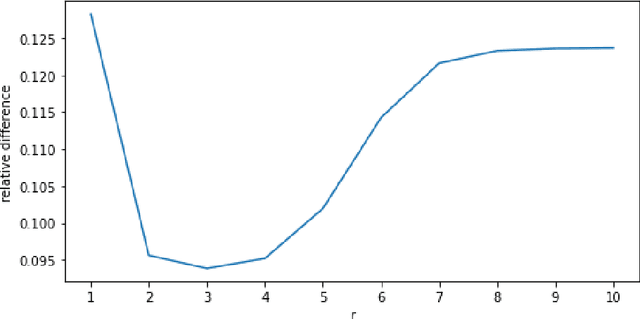
Federated learning is an emerging decentralized machine learning scheme that allows multiple data owners to work collaboratively while ensuring data privacy. The success of federated learning depends largely on the participation of data owners. To sustain and encourage data owners' participation, it is crucial to fairly evaluate the quality of the data provided by the data owners and reward them correspondingly. Federated Shapley value, recently proposed by Wang et al. [Federated Learning, 2020], is a measure for data value under the framework of federated learning that satisfies many desired properties for data valuation. However, there are still factors of potential unfairness in the design of federated Shapley value because two data owners with the same local data may not receive the same evaluation. We propose a new measure called completed federated Shapley value to improve the fairness of federated Shapley value. The design depends on completing a matrix consisting of all the possible contributions by different subsets of the data owners. It is shown under mild conditions that this matrix is approximately low-rank by leveraging concepts and tools from optimization. Both theoretical analysis and empirical evaluation verify that the proposed measure does improve fairness in many circumstances.
Online mirror descent and dual averaging: keeping pace in the dynamic case
Jun 03, 2020
Online mirror descent (OMD) and dual averaging (DA) are two fundamental algorithms for online convex optimization. They are known to have very similar (or even identical) performance guarantees in most scenarios when a \emph{fixed} learning rate is used. However, for \emph{dynamic} learning rates OMD is provably inferior to DA. It is known that, with a dynamic learning rate, OMD can suffer linear regret, even in common settings such as prediction with expert advice. This hints that the relationship between OMD and DA is not fully understood at present. In this paper, we modify the OMD algorithm by a simple technique that we call stabilization. We give essentially the same abstract regret bound for stabilized OMD and DA by modifying the classical OMD convergence analysis in a careful and modular way, yielding proofs that we believe to be clean and flexible. Simple corollaries of these bounds show that OMD with stabilization and DA enjoy the same performance guarantees in many applications even under dynamic learning rates. We also shed some light on the similarities between OMD and DA and show simple conditions under which stabilized OMD and DA generate the same iterates.