 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLower Bounds for Private Estimation of Gaussian Covariance Matrices under All Reasonable Parameter Regimes
Apr 26, 2024We prove lower bounds on the number of samples needed to privately estimate the covariance matrix of a Gaussian distribution. Our bounds match existing upper bounds in the widest known setting of parameters. Our analysis relies on the Stein-Haff identity, an extension of the classical Stein's identity used in previous fingerprinting lemma arguments.
Searching for Optimal Per-Coordinate Step-sizes with Multidimensional Backtracking
Jun 05, 2023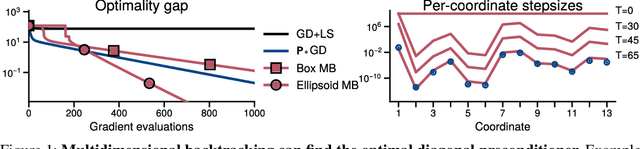


The backtracking line-search is an effective technique to automatically tune the step-size in smooth optimization. It guarantees similar performance to using the theoretically optimal step-size. Many approaches have been developed to instead tune per-coordinate step-sizes, also known as diagonal preconditioners, but none of the existing methods are provably competitive with the optimal per-coordinate stepsizes. We propose multidimensional backtracking, an extension of the backtracking line-search to find good diagonal preconditioners for smooth convex problems. Our key insight is that the gradient with respect to the step-sizes, also known as hypergradients, yields separating hyperplanes that let us search for good preconditioners using cutting-plane methods. As black-box cutting-plane approaches like the ellipsoid method are computationally prohibitive, we develop an efficient algorithm tailored to our setting. Multidimensional backtracking is provably competitive with the best diagonal preconditioner and requires no manual tuning.
Regret Bounds without Lipschitz Continuity: Online Learning with Relative-Lipschitz Losses
Oct 22, 2020In online convex optimization (OCO), Lipschitz continuity of the functions is commonly assumed in order to obtain sublinear regret. Moreover, many algorithms have only logarithmic regret when these functions are also strongly convex. Recently, researchers from convex optimization proposed the notions of "relative Lipschitz continuity" and "relative strong convexity". Both of the notions are generalizations of their classical counterparts. It has been shown that subgradient methods in the relative setting have performance analogous to their performance in the classical setting. In this work, we consider OCO for relative Lipschitz and relative strongly convex functions. We extend the known regret bounds for classical OCO algorithms to the relative setting. Specifically, we show regret bounds for the follow the regularized leader algorithms and a variant of online mirror descent. Due to the generality of these methods, these results yield regret bounds for a wide variety of OCO algorithms. Furthermore, we further extend the results to algorithms with extra regularization such as regularized dual averaging.
Online mirror descent and dual averaging: keeping pace in the dynamic case
Jun 03, 2020
Online mirror descent (OMD) and dual averaging (DA) are two fundamental algorithms for online convex optimization. They are known to have very similar (or even identical) performance guarantees in most scenarios when a \emph{fixed} learning rate is used. However, for \emph{dynamic} learning rates OMD is provably inferior to DA. It is known that, with a dynamic learning rate, OMD can suffer linear regret, even in common settings such as prediction with expert advice. This hints that the relationship between OMD and DA is not fully understood at present. In this paper, we modify the OMD algorithm by a simple technique that we call stabilization. We give essentially the same abstract regret bound for stabilized OMD and DA by modifying the classical OMD convergence analysis in a careful and modular way, yielding proofs that we believe to be clean and flexible. Simple corollaries of these bounds show that OMD with stabilization and DA enjoy the same performance guarantees in many applications even under dynamic learning rates. We also shed some light on the similarities between OMD and DA and show simple conditions under which stabilized OMD and DA generate the same iterates.