 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Gradient Descent and Sign Descent for Linear Bigram Models under Zipf's Law
May 25, 2025Recent works have highlighted optimization difficulties faced by gradient descent in training the first and last layers of transformer-based language models, which are overcome by optimizers such as Adam. These works suggest that the difficulty is linked to the heavy-tailed distribution of words in text data, where the frequency of the $k$th most frequent word $\pi_k$ is proportional to $1/k$, following Zipf's law. To better understand the impact of the data distribution on training performance, we study a linear bigram model for next-token prediction when the tokens follow a power law $\pi_k \propto 1/k^\alpha$ parameterized by the exponent $\alpha > 0$. We derive optimization scaling laws for deterministic gradient descent and sign descent as a proxy for Adam as a function of the exponent $\alpha$. Existing theoretical investigations in scaling laws assume that the eigenvalues of the data decay as a power law with exponent $\alpha > 1$. This assumption effectively makes the problem ``finite dimensional'' as most of the loss comes from a few of the largest eigencomponents. In comparison, we show that the problem is more difficult when the data have heavier tails. The case $\alpha = 1$ as found in text data is ``worst-case'' for gradient descent, in that the number of iterations required to reach a small relative error scales almost linearly with dimension. While the performance of sign descent also depends on the dimension, for Zipf-distributed data the number of iterations scales only with the square-root of the dimension, leading to a large improvement for large vocabularies.
Heavy-Tailed Class Imbalance and Why Adam Outperforms Gradient Descent on Language Models
Feb 29, 2024



Adam has been shown to outperform gradient descent in optimizing large language transformers empirically, and by a larger margin than on other tasks, but it is unclear why this happens. We show that the heavy-tailed class imbalance found in language modeling tasks leads to difficulties in the optimization dynamics. When training with gradient descent, the loss associated with infrequent words decreases slower than the loss associated with frequent ones. As most samples come from relatively infrequent words, the average loss decreases slowly with gradient descent. On the other hand, Adam and sign-based methods do not suffer from this problem and improve predictions on all classes. To establish that this behavior is indeed caused by class imbalance, we show empirically that it persist through different architectures and data types, on language transformers, vision CNNs, and linear models. We further study this phenomenon on a linear classification with cross-entropy loss, showing that heavy-tailed class imbalance leads to ill-conditioning, and that the normalization used by Adam can counteract it.
Searching for Optimal Per-Coordinate Step-sizes with Multidimensional Backtracking
Jun 05, 2023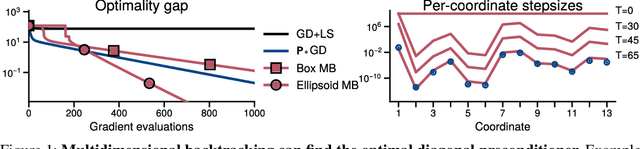


The backtracking line-search is an effective technique to automatically tune the step-size in smooth optimization. It guarantees similar performance to using the theoretically optimal step-size. Many approaches have been developed to instead tune per-coordinate step-sizes, also known as diagonal preconditioners, but none of the existing methods are provably competitive with the optimal per-coordinate stepsizes. We propose multidimensional backtracking, an extension of the backtracking line-search to find good diagonal preconditioners for smooth convex problems. Our key insight is that the gradient with respect to the step-sizes, also known as hypergradients, yields separating hyperplanes that let us search for good preconditioners using cutting-plane methods. As black-box cutting-plane approaches like the ellipsoid method are computationally prohibitive, we develop an efficient algorithm tailored to our setting. Multidimensional backtracking is provably competitive with the best diagonal preconditioner and requires no manual tuning.
Noise Is Not the Main Factor Behind the Gap Between SGD and Adam on Transformers, but Sign Descent Might Be
Apr 27, 2023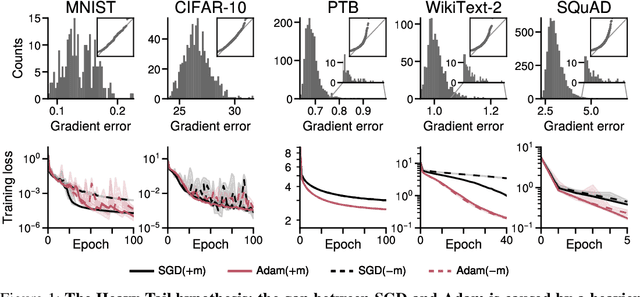
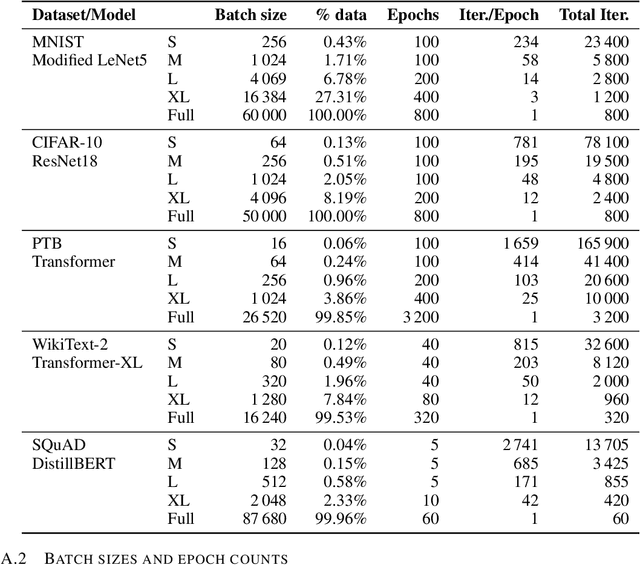
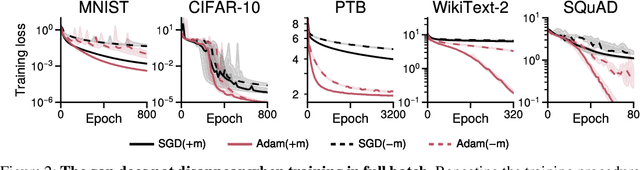
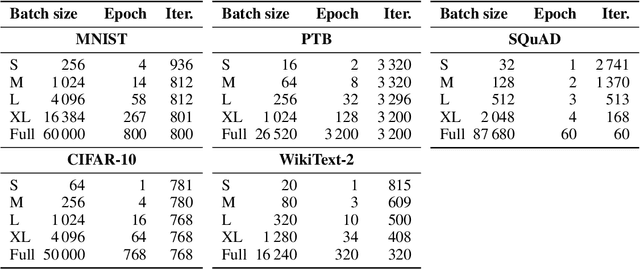
The success of the Adam optimizer on a wide array of architectures has made it the default in settings where stochastic gradient descent (SGD) performs poorly. However, our theoretical understanding of this discrepancy is lagging, preventing the development of significant improvements on either algorithm. Recent work advances the hypothesis that Adam and other heuristics like gradient clipping outperform SGD on language tasks because the distribution of the error induced by sampling has heavy tails. This suggests that Adam outperform SGD because it uses a more robust gradient estimate. We evaluate this hypothesis by varying the batch size, up to the entire dataset, to control for stochasticity. We present evidence that stochasticity and heavy-tailed noise are not major factors in the performance gap between SGD and Adam. Rather, Adam performs better as the batch size increases, while SGD is less effective at taking advantage of the reduction in noise. This raises the question as to why Adam outperforms SGD in the full-batch setting. Through further investigation of simpler variants of SGD, we find that the behavior of Adam with large batches is similar to sign descent with momentum.
Convergence Rates for the MAP of an Exponential Family and Stochastic Mirror Descent -- an Open Problem
Nov 12, 2021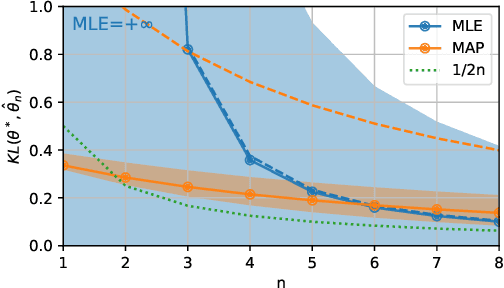
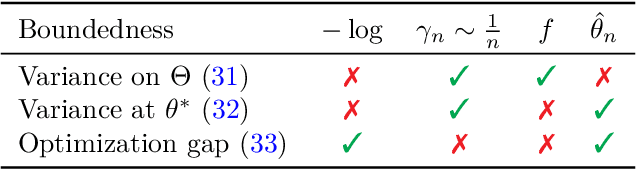
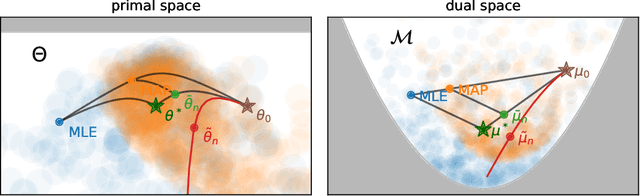
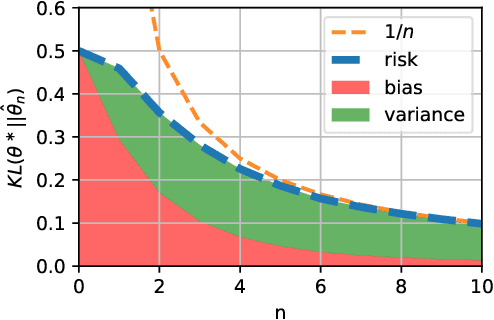
We consider the problem of upper bounding the expected log-likelihood sub-optimality of the maximum likelihood estimate (MLE), or a conjugate maximum a posteriori (MAP) for an exponential family, in a non-asymptotic way. Surprisingly, we found no general solution to this problem in the literature. In particular, current theories do not hold for a Gaussian or in the interesting few samples regime. After exhibiting various facets of the problem, we show we can interpret the MAP as running stochastic mirror descent (SMD) on the log-likelihood. However, modern convergence results do not apply for standard examples of the exponential family, highlighting holes in the convergence literature. We believe solving this very fundamental problem may bring progress to both the statistics and optimization communities.
Homeomorphic-Invariance of EM: Non-Asymptotic Convergence in KL Divergence for Exponential Families via Mirror Descent
Nov 02, 2020



Expectation maximization (EM) is the default algorithm for fitting probabilistic models with missing or latent variables, yet we lack a full understanding of its non-asymptotic convergence properties. Previous works show results along the lines of "EM converges at least as fast as gradient descent" by assuming the conditions for the convergence of gradient descent apply to EM. This approach is not only loose, in that it does not capture that EM can make more progress than a gradient step, but the assumptions fail to hold for textbook examples of EM like Gaussian mixtures. In this work we first show that for the common setting of exponential family distributions, viewing EM as a mirror descent algorithm leads to convergence rates in Kullback-Leibler (KL) divergence. Then, we show how the KL divergence is related to first-order stationarity via Bregman divergences. In contrast to previous works, the analysis is invariant to the choice of parametrization and holds with minimal assumptions. We also show applications of these ideas to local linear (and superlinear) convergence rates, generalized EM, and non-exponential family distributions.
Adaptive Gradient Methods Converge Faster with Over-Parameterization (and you can do a line-search)
Jun 11, 2020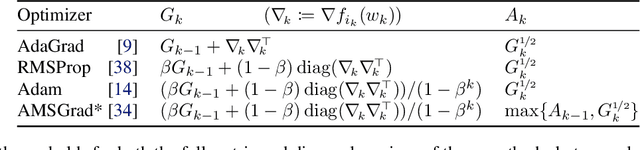
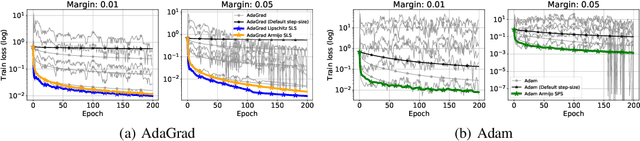

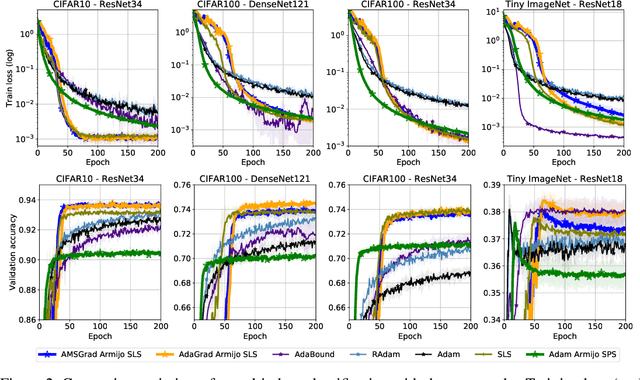
As adaptive gradient methods are typically used for training over-parameterized models capable of exactly fitting the data, we study their convergence in this interpolation setting. Under this assumption, we prove that constant step-size, zero-momentum variants of Adam and AMSGrad can converge to the minimizer at the O(1/T) rate for smooth, convex functions. When this assumption is only approximately satisfied, we show that these methods converge to a neighbourhood of the solution. On the other hand, we show that Adagrad is robust to the violation of interpolation and converges to the minimizer at the optimal rate. However, we demonstrate that even for simple, convex problems satisfying interpolation, the empirical performance of these methods heavily depends on the step-size and requires tuning. We alleviate this problem by making use of stochastic line-search methods (SLS) and Polyak's step-sizes (SPS) to help these methods adapt to the function's local smoothness. We prove that adaptive methods used in conjunction with these techniques do not require knowledge of problem-dependent constants and retain the convergence guarantees of their constant step-size counterparts. Experimentally, we show that using SLS or SPS consistently improves the convergence of adaptive methods across tasks; from binary classification with kernel mappings to classification with deep neural networks. Furthermore, our empirical results show that Adagrad equipped with SLS generalizes better than SGD.
BackPACK: Packing more into backprop
Feb 15, 2020


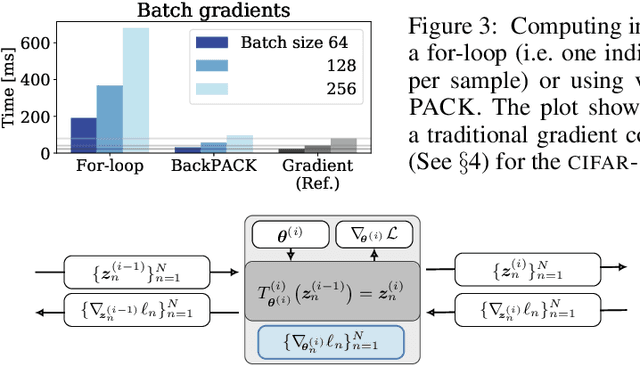
Automatic differentiation frameworks are optimized for exactly one thing: computing the average mini-batch gradient. Yet, other quantities such as the variance of the mini-batch gradients or many approximations to the Hessian can, in theory, be computed efficiently, and at the same time as the gradient. While these quantities are of great interest to researchers and practitioners, current deep-learning software does not support their automatic calculation. Manually implementing them is burdensome, inefficient if done naively, and the resulting code is rarely shared. This hampers progress in deep learning, and unnecessarily narrows research to focus on gradient descent and its variants; it also complicates replication studies and comparisons between newly developed methods that require those quantities, to the point of impossibility. To address this problem, we introduce BackPACK, an efficient framework built on top of PyTorch, that extends the backpropagation algorithm to extract additional information from first- and second-order derivatives. Its capabilities are illustrated by benchmark reports for computing additional quantities on deep neural networks, and an example application by testing several recent curvature approximations for optimization.
Limitations of the Empirical Fisher Approximation
May 29, 2019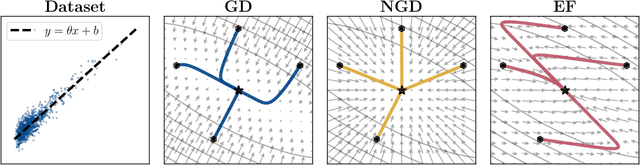

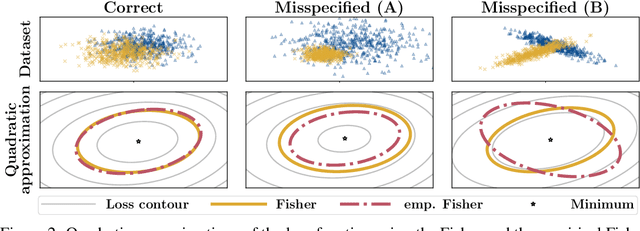
Natural gradient descent, which preconditions a gradient descent update with the Fisher information matrix of the underlying statistical model, is a way to capture partial second-order information. Several highly visible works have advocated an approximation known as the empirical Fisher, drawing connections between approximate second-order methods and heuristics like Adam. We dispute this argument by showing that the empirical Fisher---unlike the Fisher---does not generally capture second-order information. We further argue that the conditions under which the empirical Fisher approaches the Fisher (and the Hessian) are unlikely to be met in practice, and that, even on simple optimization problems, the pathologies of the empirical Fisher can have undesirable effects.
SLANG: Fast Structured Covariance Approximations for Bayesian Deep Learning with Natural Gradient
Nov 11, 2018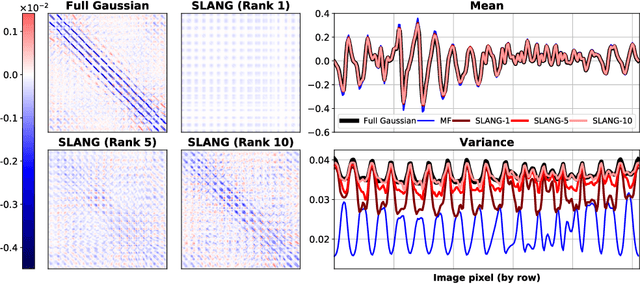
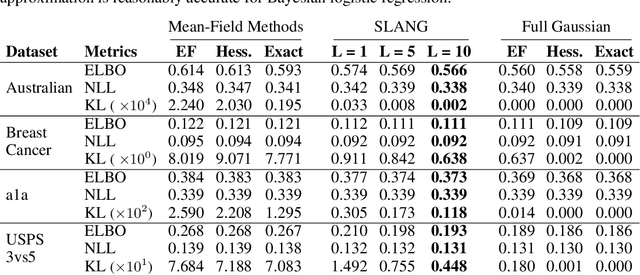
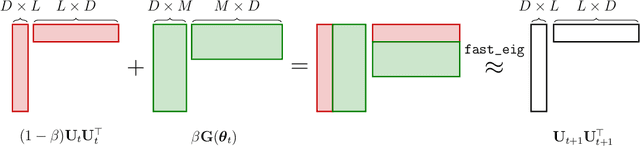
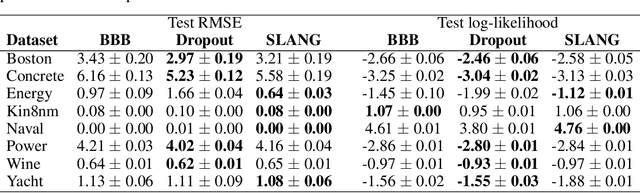
Uncertainty estimation in large deep-learning models is a computationally challenging task, where it is difficult to form even a Gaussian approximation to the posterior distribution. In such situations, existing methods usually resort to a diagonal approximation of the covariance matrix despite, the fact that these matrices are known to give poor uncertainty estimates. To address this issue, we propose a new stochastic, low-rank, approximate natural-gradient (SLANG) method for variational inference in large, deep models. Our method estimates a "diagonal plus low-rank" structure based solely on back-propagated gradients of the network log-likelihood. This requires strictly less gradient computations than methods that compute the gradient of the whole variational objective. Empirical evaluations on standard benchmarks confirm that SLANG enables faster and more accurate estimation of uncertainty than mean-field methods, and performs comparably to state-of-the-art methods.