 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLANG: Fast Structured Covariance Approximations for Bayesian Deep Learning with Natural Gradient
Paper and Code
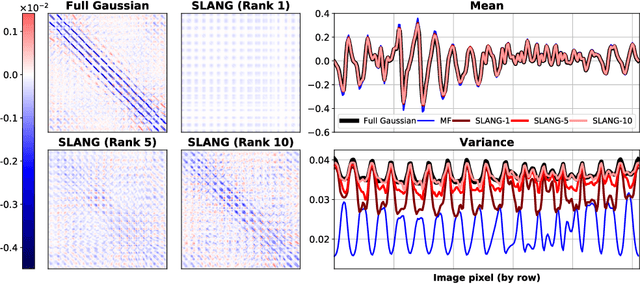
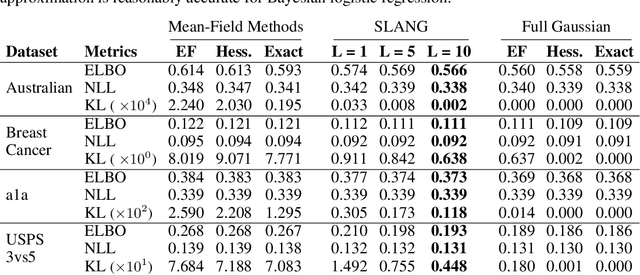
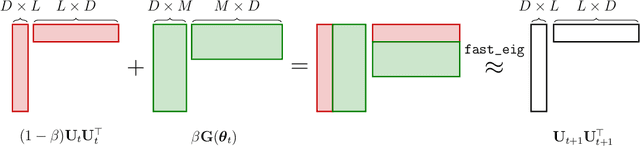
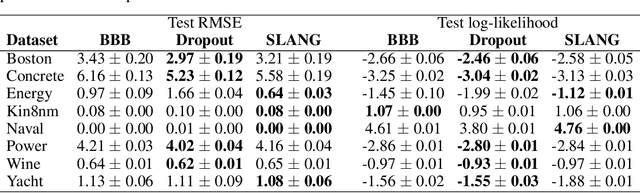
Uncertainty estimation in large deep-learning models is a computationally challenging task, where it is difficult to form even a Gaussian approximation to the posterior distribution. In such situations, existing methods usually resort to a diagonal approximation of the covariance matrix despite, the fact that these matrices are known to give poor uncertainty estimates. To address this issue, we propose a new stochastic, low-rank, approximate natural-gradient (SLANG) method for variational inference in large, deep models. Our method estimates a "diagonal plus low-rank" structure based solely on back-propagated gradients of the network log-likelihood. This requires strictly less gradient computations than methods that compute the gradient of the whole variational objective. Empirical evaluations on standard benchmarks confirm that SLANG enables faster and more accurate estimation of uncertainty than mean-field methods, and performs comparably to state-of-the-art methods.