 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTorchDriveEnv: A Reinforcement Learning Benchmark for Autonomous Driving with Reactive, Realistic, and Diverse Non-Playable Characters
May 07, 2024
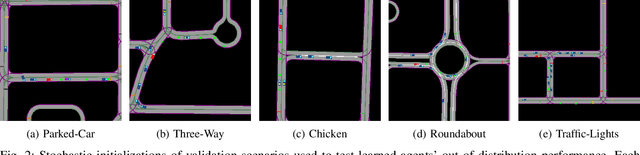
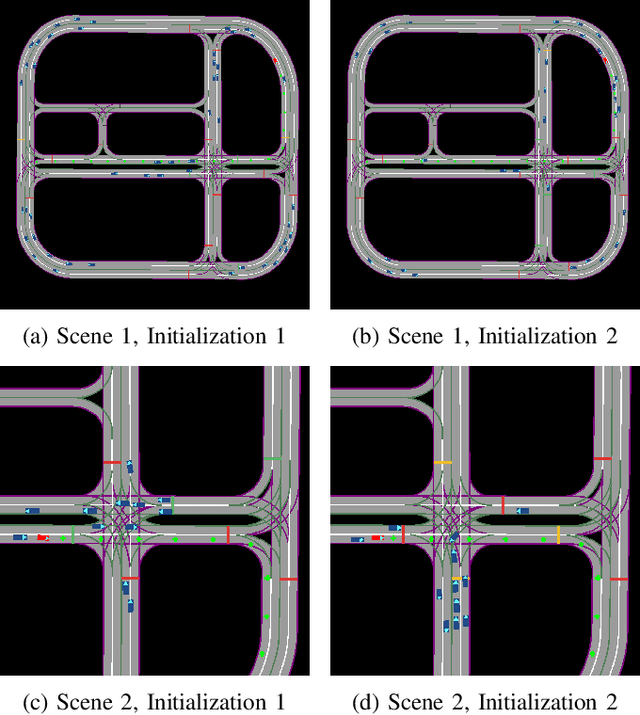
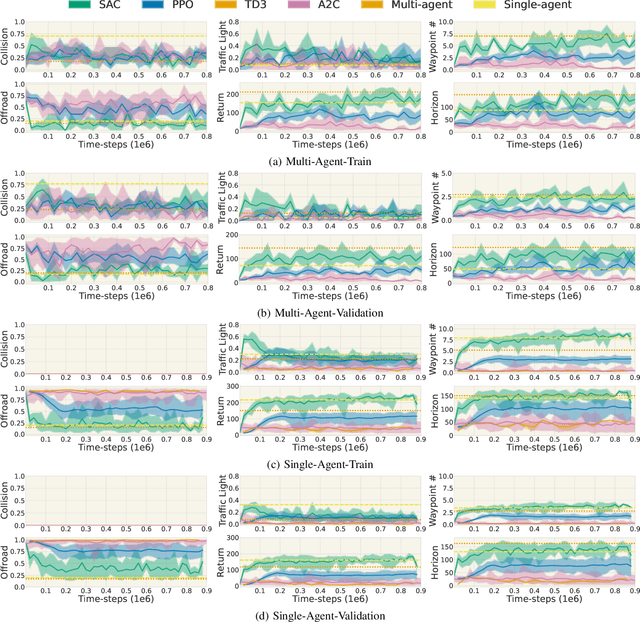
The training, testing, and deployment, of autonomous vehicles requires realistic and efficient simulators. Moreover, because of the high variability between different problems presented in different autonomous systems, these simulators need to be easy to use, and easy to modify. To address these problems we introduce TorchDriveSim and its benchmark extension TorchDriveEnv. TorchDriveEnv is a lightweight reinforcement learning benchmark programmed entirely in Python, which can be modified to test a number of different factors in learned vehicle behavior, including the effect of varying kinematic models, agent types, and traffic control patterns. Most importantly unlike many replay based simulation approaches, TorchDriveEnv is fully integrated with a state of the art behavioral simulation API. This allows users to train and evaluate driving models alongside data driven Non-Playable Characters (NPC) whose initializations and driving behavior are reactive, realistic, and diverse. We illustrate the efficiency and simplicity of TorchDriveEnv by evaluating common reinforcement learning baselines in both training and validation environments. Our experiments show that TorchDriveEnv is easy to use, but difficult to solve.
Nearest Neighbour Score Estimators for Diffusion Generative Models
Feb 12, 2024



Score function estimation is the cornerstone of both training and sampling from diffusion generative models. Despite this fact, the most commonly used estimators are either biased neural network approximations or high variance Monte Carlo estimators based on the conditional score. We introduce a novel nearest neighbour score function estimator which utilizes multiple samples from the training set to dramatically decrease estimator variance. We leverage our low variance estimator in two compelling applications. Training consistency models with our estimator, we report a significant increase in both convergence speed and sample quality. In diffusion models, we show that our estimator can replace a learned network for probability-flow ODE integration, opening promising new avenues of future research.
A Diffusion-Model of Joint Interactive Navigation
Sep 21, 2023



Simulation of autonomous vehicle systems requires that simulated traffic participants exhibit diverse and realistic behaviors. The use of prerecorded real-world traffic scenarios in simulation ensures realism but the rarity of safety critical events makes large scale collection of driving scenarios expensive. In this paper, we present DJINN - a diffusion based method of generating traffic scenarios. Our approach jointly diffuses the trajectories of all agents, conditioned on a flexible set of state observations from the past, present, or future. On popular trajectory forecasting datasets, we report state of the art performance on joint trajectory metrics. In addition, we demonstrate how DJINN flexibly enables direct test-time sampling from a variety of valuable conditional distributions including goal-based sampling, behavior-class sampling, and scenario editing.
Analyzing and Improving Greedy 2-Coordinate Updates for Equality-Constrained Optimization via Steepest Descent in the 1-Norm
Jul 03, 2023



We consider minimizing a smooth function subject to a summation constraint over its variables. By exploiting a connection between the greedy 2-coordinate update for this problem and equality-constrained steepest descent in the 1-norm, we give a convergence rate for greedy selection under a proximal Polyak-Lojasiewicz assumption that is faster than random selection and independent of the problem dimension $n$. We then consider minimizing with both a summation constraint and bound constraints, as arises in the support vector machine dual problem. Existing greedy rules for this setting either guarantee trivial progress only or require $O(n^2)$ time to compute. We show that bound- and summation-constrained steepest descent in the L1-norm guarantees more progress per iteration than previous rules and can be computed in only $O(n \log n)$ time.
Realistically distributing object placements in synthetic training data improves the performance of vision-based object detection models
May 24, 2023When training object detection models on synthetic data, it is important to make the distribution of synthetic data as close as possible to the distribution of real data. We investigate specifically the impact of object placement distribution, keeping all other aspects of synthetic data fixed. Our experiment, training a 3D vehicle detection model in CARLA and testing on KITTI, demonstrates a substantial improvement resulting from improving the object placement distribution.
Video Killed the HD-Map: Predicting Driving Behavior Directly From Drone Images
May 19, 2023The development of algorithms that learn behavioral driving models using human demonstrations has led to increasingly realistic simulations. In general, such models learn to jointly predict trajectories for all controlled agents by exploiting road context information such as drivable lanes obtained from manually annotated high-definition (HD) maps. Recent studies show that these models can greatly benefit from increasing the amount of human data available for training. However, the manual annotation of HD maps which is necessary for every new location puts a bottleneck on efficiently scaling up human traffic datasets. We propose a drone birdview image-based map (DBM) representation that requires minimal annotation and provides rich road context information. We evaluate multi-agent trajectory prediction using the DBM by incorporating it into a differentiable driving simulator as an image-texture-based differentiable rendering module. Our results demonstrate competitive multi-agent trajectory prediction performance when using our DBM representation as compared to models trained with rasterized HD maps.
Noise Is Not the Main Factor Behind the Gap Between SGD and Adam on Transformers, but Sign Descent Might Be
Apr 27, 2023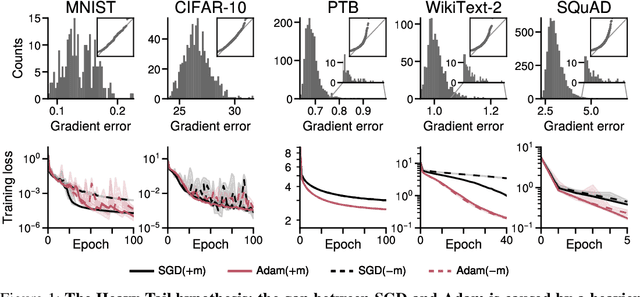
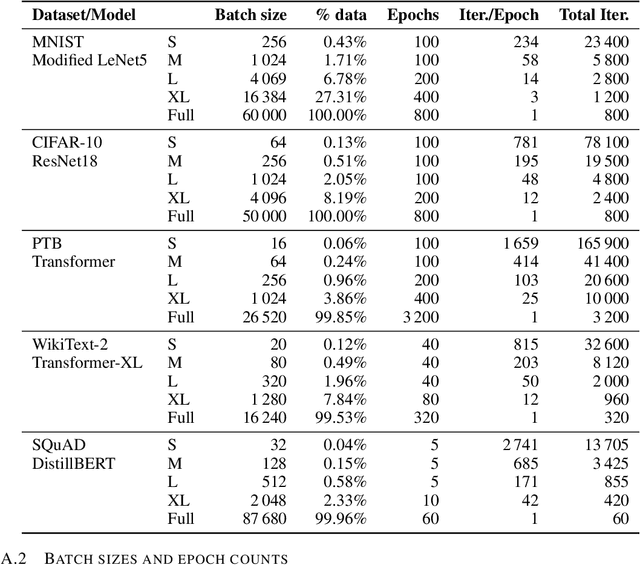
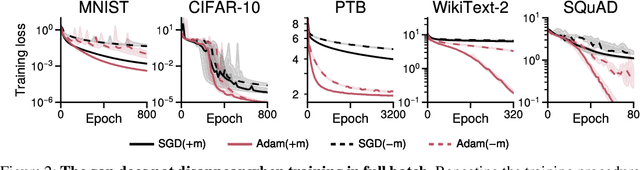
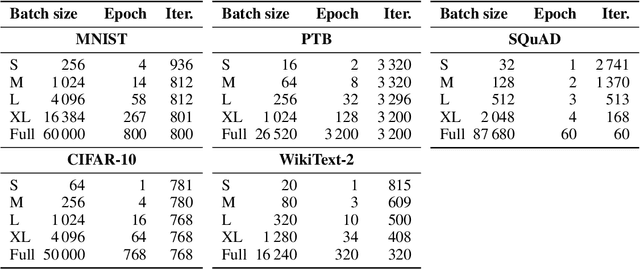
The success of the Adam optimizer on a wide array of architectures has made it the default in settings where stochastic gradient descent (SGD) performs poorly. However, our theoretical understanding of this discrepancy is lagging, preventing the development of significant improvements on either algorithm. Recent work advances the hypothesis that Adam and other heuristics like gradient clipping outperform SGD on language tasks because the distribution of the error induced by sampling has heavy tails. This suggests that Adam outperform SGD because it uses a more robust gradient estimate. We evaluate this hypothesis by varying the batch size, up to the entire dataset, to control for stochasticity. We present evidence that stochasticity and heavy-tailed noise are not major factors in the performance gap between SGD and Adam. Rather, Adam performs better as the batch size increases, while SGD is less effective at taking advantage of the reduction in noise. This raises the question as to why Adam outperforms SGD in the full-batch setting. Through further investigation of simpler variants of SGD, we find that the behavior of Adam with large batches is similar to sign descent with momentum.
Target-based Surrogates for Stochastic Optimization
Feb 06, 2023



We consider minimizing functions for which it is expensive to compute the (possibly stochastic) gradient. Such functions are prevalent in reinforcement learning, imitation learning and adversarial training. Our target optimization framework uses the (expensive) gradient computation to construct surrogate functions in a target space (e.g. the logits output by a linear model for classification) that can be minimized efficiently. This allows for multiple parameter updates to the model, amortizing the cost of gradient computation. In the full-batch setting, we prove that our surrogate is a global upper-bound on the loss, and can be (locally) minimized using a black-box optimization algorithm. We prove that the resulting majorization-minimization algorithm ensures convergence to a stationary point of the loss. Next, we instantiate our framework in the stochastic setting and propose the $SSO$ algorithm, which can be viewed as projected stochastic gradient descent in the target space. This connection enables us to prove theoretical guarantees for $SSO$ when minimizing convex functions. Our framework allows the use of standard stochastic optimization algorithms to construct surrogates which can be minimized by any deterministic optimization method. To evaluate our framework, we consider a suite of supervised learning and imitation learning problems. Our experiments indicate the benefits of target optimization and the effectiveness of $SSO$.
Vehicle Type Specific Waypoint Generation
Aug 09, 2022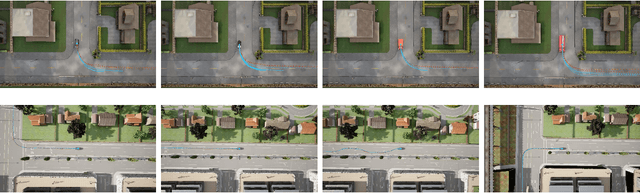
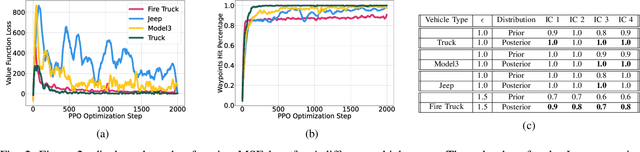
We develop a generic mechanism for generating vehicle-type specific sequences of waypoints from a probabilistic foundation model of driving behavior. Many foundation behavior models are trained on data that does not include vehicle information, which limits their utility in downstream applications such as planning. Our novel methodology conditionally specializes such a behavior predictive model to a vehicle-type by utilizing byproducts of the reinforcement learning algorithms used to produce vehicle specific controllers. We show how to compose a vehicle specific value function estimate with a generic probabilistic behavior model to generate vehicle-type specific waypoint sequences that are more likely to be physically plausible then their vehicle-agnostic counterparts.
Improved Policy Optimization for Online Imitation Learning
Jul 29, 2022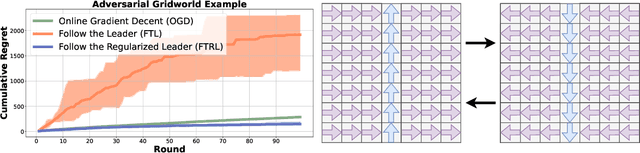
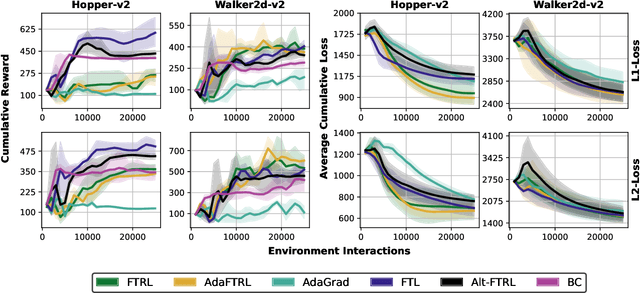
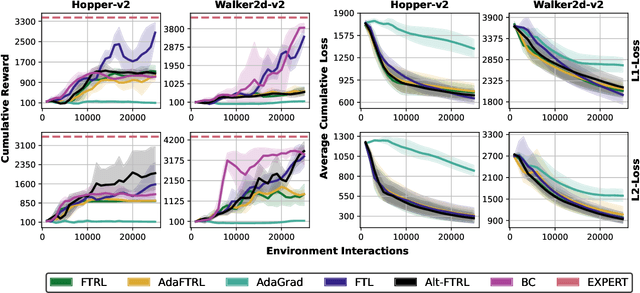
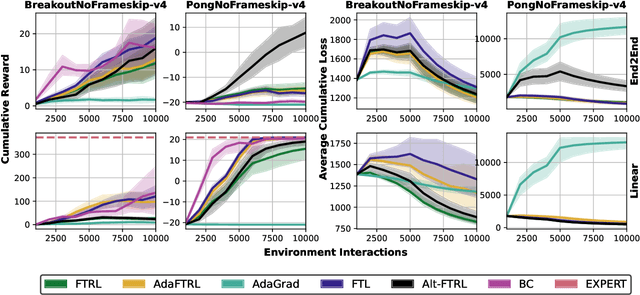
We consider online imitation learning (OIL), where the task is to find a policy that imitates the behavior of an expert via active interaction with the environment. We aim to bridge the gap between the theory and practice of policy optimization algorithms for OIL by analyzing one of the most popular OIL algorithms, DAGGER. Specifically, if the class of policies is sufficiently expressive to contain the expert policy, we prove that DAGGER achieves constant regret. Unlike previous bounds that require the losses to be strongly-convex, our result only requires the weaker assumption that the losses be strongly-convex with respect to the policy's sufficient statistics (not its parameterization). In order to ensure convergence for a wider class of policies and losses, we augment DAGGER with an additional regularization term. In particular, we propose a variant of Follow-the-Regularized-Leader (FTRL) and its adaptive variant for OIL and develop a memory-efficient implementation, which matches the memory requirements of FTL. Assuming that the loss functions are smooth and convex with respect to the parameters of the policy, we also prove that FTRL achieves constant regret for any sufficiently expressive policy class, while retaining $O(\sqrt{T})$ regret in the worst-case. We demonstrate the effectiveness of these algorithms with experiments on synthetic and high-dimensional control tasks.