 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Policy Optimization for Online Imitation Learning
Paper and Code
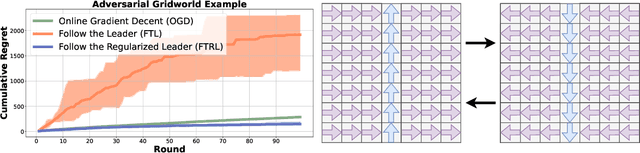
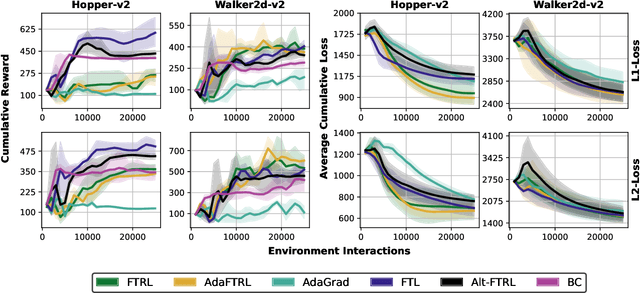
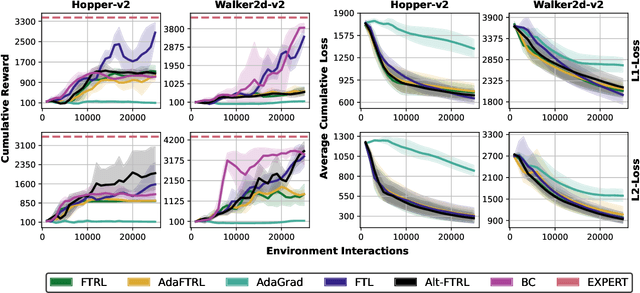
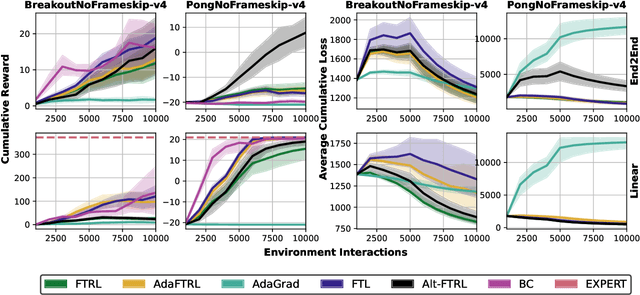
We consider online imitation learning (OIL), where the task is to find a policy that imitates the behavior of an expert via active interaction with the environment. We aim to bridge the gap between the theory and practice of policy optimization algorithms for OIL by analyzing one of the most popular OIL algorithms, DAGGER. Specifically, if the class of policies is sufficiently expressive to contain the expert policy, we prove that DAGGER achieves constant regret. Unlike previous bounds that require the losses to be strongly-convex, our result only requires the weaker assumption that the losses be strongly-convex with respect to the policy's sufficient statistics (not its parameterization). In order to ensure convergence for a wider class of policies and losses, we augment DAGGER with an additional regularization term. In particular, we propose a variant of Follow-the-Regularized-Leader (FTRL) and its adaptive variant for OIL and develop a memory-efficient implementation, which matches the memory requirements of FTL. Assuming that the loss functions are smooth and convex with respect to the parameters of the policy, we also prove that FTRL achieves constant regret for any sufficiently expressive policy class, while retaining $O(\sqrt{T})$ regret in the worst-case. We demonstrate the effectiveness of these algorithms with experiments on synthetic and high-dimensional control tasks.