 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECLeKTic: a Novel Challenge Set for Evaluation of Cross-Lingual Knowledge Transfer
Feb 28, 2025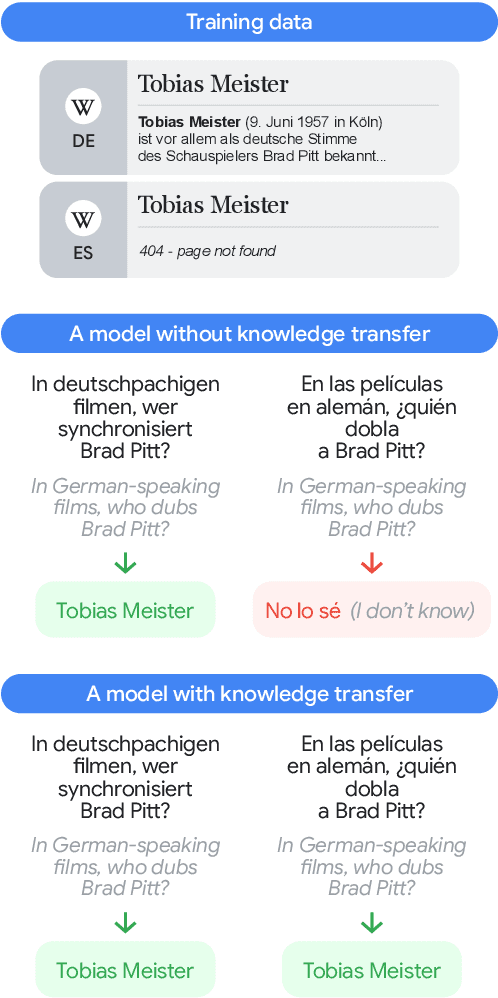
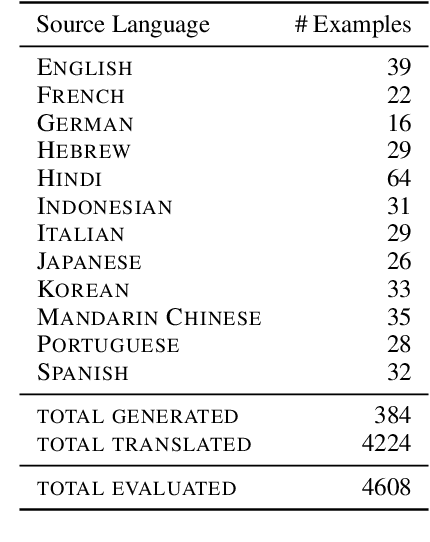
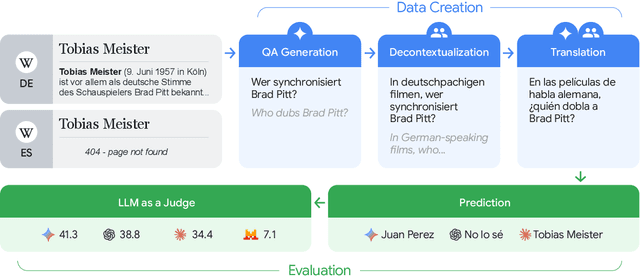
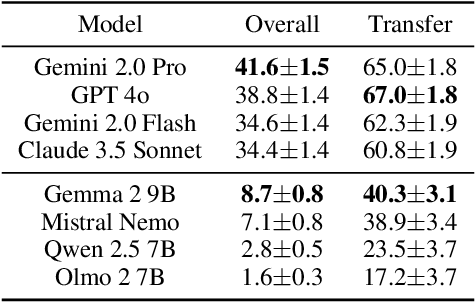
To achieve equitable performance across languages, multilingual large language models (LLMs) must be able to abstract knowledge beyond the language in which it was acquired. However, the current literature lacks reliable ways to measure LLMs' capability of cross-lingual knowledge transfer. To that end, we present ECLeKTic, a multilingual closed-book QA (CBQA) dataset that Evaluates Cross-Lingual Knowledge Transfer in a simple, black-box manner. We detected information with uneven coverage across languages by controlling for presence and absence of Wikipedia articles in 12 languages. We generated knowledge-seeking questions in a source language, for which the answer appears in a relevant Wikipedia article and translated them to all other 11 languages, for which the respective Wikipedias lack equivalent articles. Assuming that Wikipedia reflects the prominent knowledge in the LLM's training data, to solve ECLeKTic's CBQA task the model is required to transfer knowledge between languages. Experimenting with 8 LLMs, we show that SOTA models struggle to effectively share knowledge across, languages even if they can predict the answer well for queries in the same language the knowledge was acquired in.
A Natural Bias for Language Generation Models
Dec 19, 2022



After just a few hundred training updates, a standard probabilistic model for language generation has likely not yet learnt many semantic or syntactic rules of natural language, which inherently makes it difficult to estimate the right probability distribution over next tokens. Yet around this point, these models have identified a simple, loss-minimising behaviour: to output the unigram distribution of the target training corpus. The use of such a crude heuristic raises the question: Rather than wasting precious compute resources and model capacity for learning this strategy at early training stages, can we initialise our models with this behaviour? Here, we show that we can effectively endow our model with a separate module that reflects unigram frequency statistics as prior knowledge. Standard neural language generation architectures offer a natural opportunity for implementing this idea: by initialising the bias term in a model's final linear layer with the log-unigram distribution. Experiments in neural machine translation demonstrate that this simple technique: (i) improves learning efficiency; (ii) achieves better overall performance; and (iii) appears to disentangle strong frequency effects, encouraging the model to specialise in non-frequency-related aspects of language.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
Ethical and social risks of harm from Language Models
Dec 08, 2021
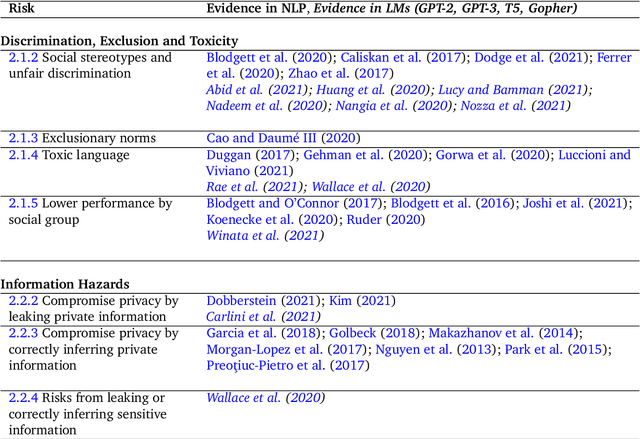
This paper aims to help structure the risk landscape associated with large-scale Language Models (LMs). In order to foster advances in responsible innovation, an in-depth understanding of the potential risks posed by these models is needed. A wide range of established and anticipated risks are analysed in detail, drawing on multidisciplinary expertise and literature from computer science, linguistics, and social sciences. We outline six specific risk areas: I. Discrimination, Exclusion and Toxicity, II. Information Hazards, III. Misinformation Harms, V. Malicious Uses, V. Human-Computer Interaction Harms, VI. Automation, Access, and Environmental Harms. The first area concerns the perpetuation of stereotypes, unfair discrimination, exclusionary norms, toxic language, and lower performance by social group for LMs. The second focuses on risks from private data leaks or LMs correctly inferring sensitive information. The third addresses risks arising from poor, false or misleading information including in sensitive domains, and knock-on risks such as the erosion of trust in shared information. The fourth considers risks from actors who try to use LMs to cause harm. The fifth focuses on risks specific to LLMs used to underpin conversational agents that interact with human users, including unsafe use, manipulation or deception. The sixth discusses the risk of environmental harm, job automation, and other challenges that may have a disparate effect on different social groups or communities. In total, we review 21 risks in-depth. We discuss the points of origin of different risks and point to potential mitigation approaches. Lastly, we discuss organisational responsibilities in implementing mitigations, and the role of collaboration and participation. We highlight directions for further research, particularly on expanding the toolkit for assessing and evaluating the outlined risks in LMs.
You should evaluate your language model on marginal likelihood over tokenisations
Sep 21, 2021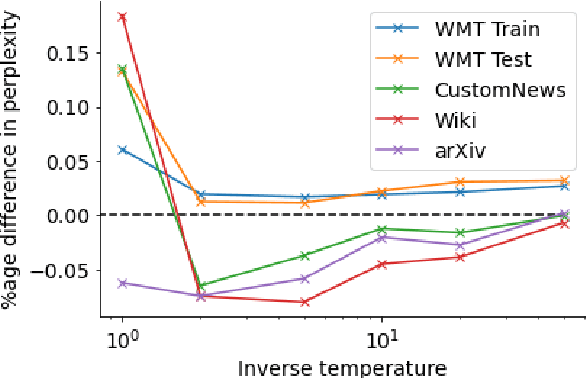
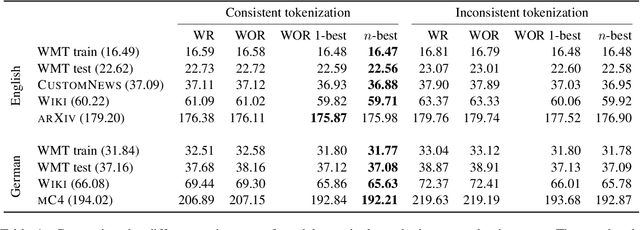
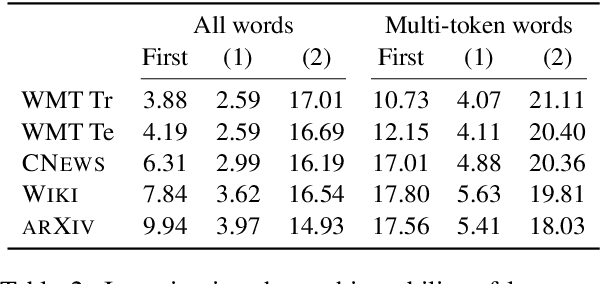
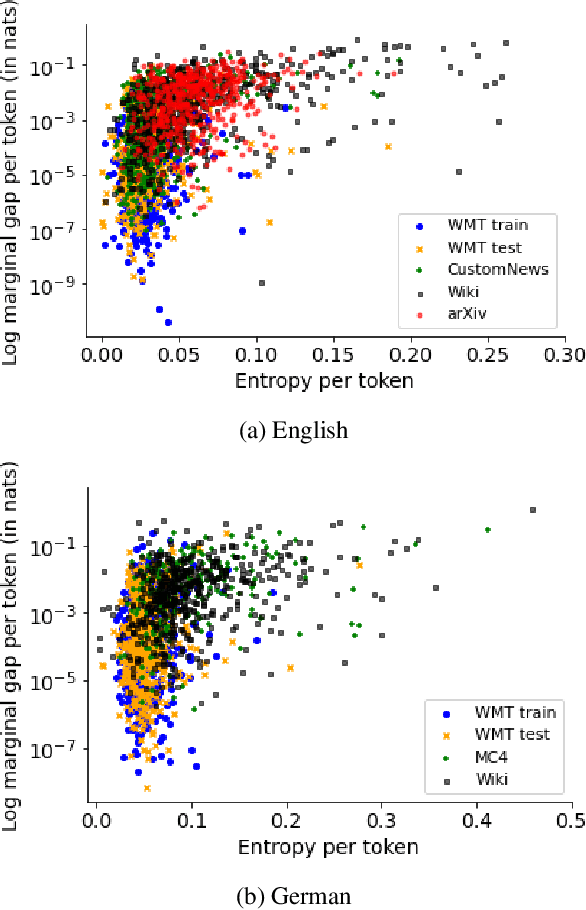
Neural language models typically tokenise input text into sub-word units to achieve an open vocabulary. The standard approach is to use a single canonical tokenisation at both train and test time. We suggest that this approach is unsatisfactory and may bottleneck our evaluation of language model performance. Using only the one-best tokenisation ignores tokeniser uncertainty over alternative tokenisations, which may hurt model out-of-domain performance. In this paper, we argue that instead, language models should be evaluated on their marginal likelihood over tokenisations. We compare different estimators for the marginal likelihood based on sampling, and show that it is feasible to estimate the marginal likelihood with a manageable number of samples. We then evaluate pretrained English and German language models on both the one-best-tokenisation and marginal perplexities, and show that the marginal perplexity can be significantly better than the one best, especially on out-of-domain data. We link this difference in perplexity to the tokeniser uncertainty as measured by tokeniser entropy. We discuss some implications of our results for language model training and evaluation, particularly with regard to tokenisation robustness.
Pretraining the Noisy Channel Model for Task-Oriented Dialogue
Mar 18, 2021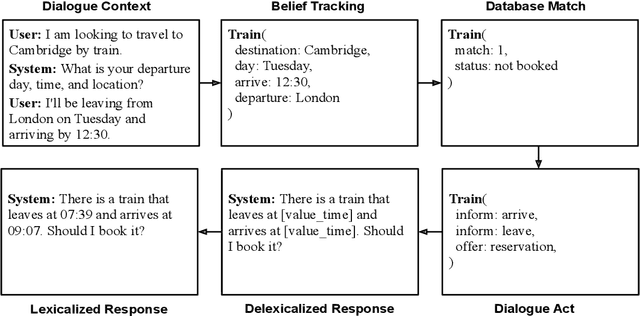



Direct decoding for task-oriented dialogue is known to suffer from the explaining-away effect, manifested in models that prefer short and generic responses. Here we argue for the use of Bayes' theorem to factorize the dialogue task into two models, the distribution of the context given the response, and the prior for the response itself. This approach, an instantiation of the noisy channel model, both mitigates the explaining-away effect and allows the principled incorporation of large pretrained models for the response prior. We present extensive experiments showing that a noisy channel model decodes better responses compared to direct decoding and that a two stage pretraining strategy, employing both open-domain and task-oriented dialogue data, improves over randomly initialized models.
Probing Emergent Semantics in Predictive Agents via Question Answering
Jun 01, 2020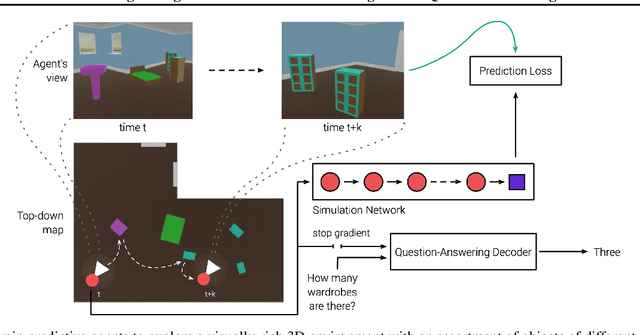

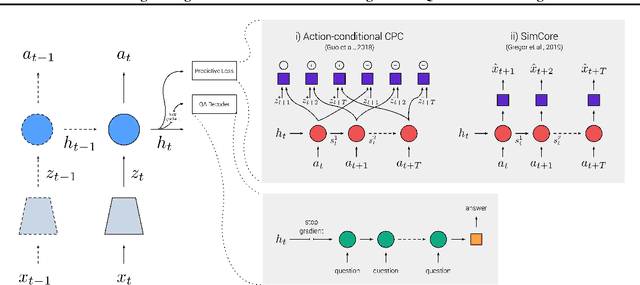
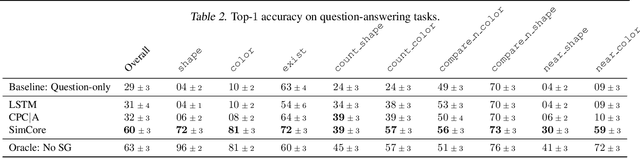
Recent work has shown how predictive modeling can endow agents with rich knowledge of their surroundings, improving their ability to act in complex environments. We propose question-answering as a general paradigm to decode and understand the representations that such agents develop, applying our method to two recent approaches to predictive modeling -action-conditional CPC (Guo et al., 2018) and SimCore (Gregor et al., 2019). After training agents with these predictive objectives in a visually-rich, 3D environment with an assortment of objects, colors, shapes, and spatial configurations, we probe their internal state representations with synthetic (English) questions, without backpropagating gradients from the question-answering decoder into the agent. The performance of different agents when probed this way reveals that they learn to encode factual, and seemingly compositional, information about objects, properties and spatial relations from their physical environment. Our approach is intuitive, i.e. humans can easily interpret responses of the model as opposed to inspecting continuous vectors, and model-agnostic, i.e. applicable to any modeling approach. By revealing the implicit knowledge of objects, quantities, properties and relations acquired by agents as they learn, question-conditional agent probing can stimulate the design and development of stronger predictive learning objectives.
Syntactic Structure Distillation Pretraining For Bidirectional Encoders
May 27, 2020
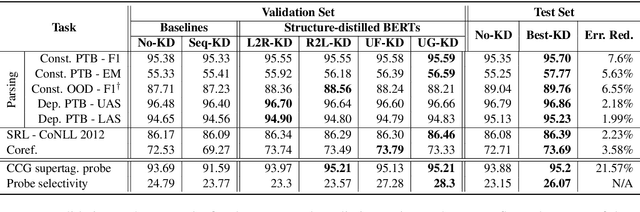
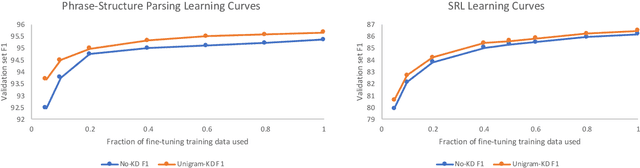
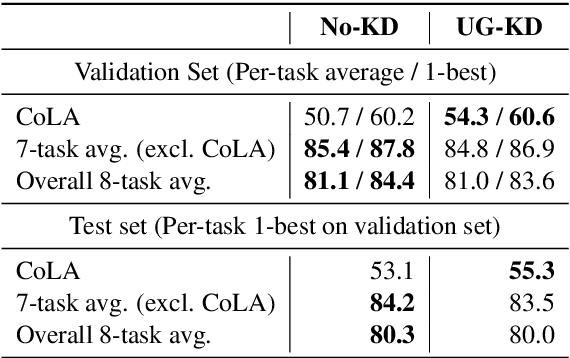
Textual representation learners trained on large amounts of data have achieved notable success on downstream tasks; intriguingly, they have also performed well on challenging tests of syntactic competence. Given this success, it remains an open question whether scalable learners like BERT can become fully proficient in the syntax of natural language by virtue of data scale alone, or whether they still benefit from more explicit syntactic biases. To answer this question, we introduce a knowledge distillation strategy for injecting syntactic biases into BERT pretraining, by distilling the syntactically informative predictions of a hierarchical---albeit harder to scale---syntactic language model. Since BERT models masked words in bidirectional context, we propose to distill the approximate marginal distribution over words in context from the syntactic LM. Our approach reduces relative error by 2-21% on a diverse set of structured prediction tasks, although we obtain mixed results on the GLUE benchmark. Our findings demonstrate the benefits of syntactic biases, even in representation learners that exploit large amounts of data, and contribute to a better understanding of where syntactic biases are most helpful in benchmarks of natural language understanding.
Neural Generative Rhetorical Structure Parsing
Sep 24, 2019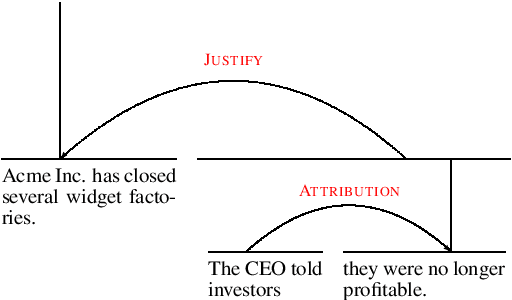



Rhetorical structure trees have been shown to be useful for several document-level tasks including summarization and document classification. Previous approaches to RST parsing have used discriminative models; however, these are less sample efficient than generative models, and RST parsing datasets are typically small. In this paper, we present the first generative model for RST parsing. Our model is a document-level RNN grammar (RNNG) with a bottom-up traversal order. We show that, for our parser's traversal order, previous beam search algorithms for RNNGs have a left-branching bias which is ill-suited for RST parsing. We develop a novel beam search algorithm that keeps track of both structure- and word-generating actions without exhibiting this branching bias and results in absolute improvements of 6.8 and 2.9 on unlabelled and labelled F1 over previous algorithms. Overall, our generative model outperforms a discriminative model with the same features by 2.6 F1 points and achieves performance comparable to the state-of-the-art, outperforming all published parsers from a recent replication study that do not use additional training data.
Scalable Syntax-Aware Language Models Using Knowledge Distillation
Jun 14, 2019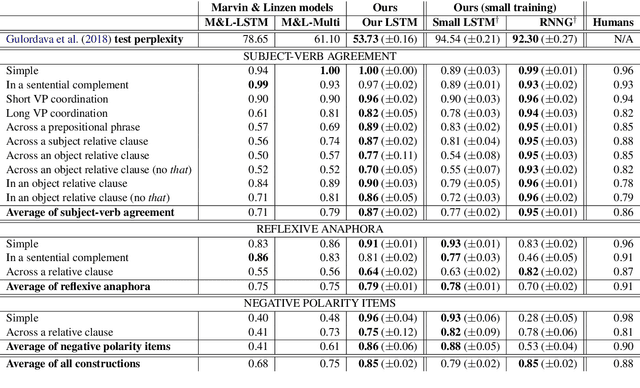
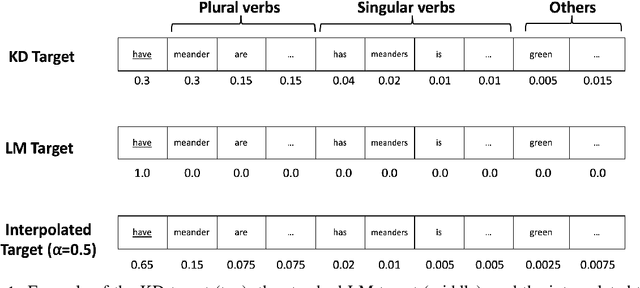
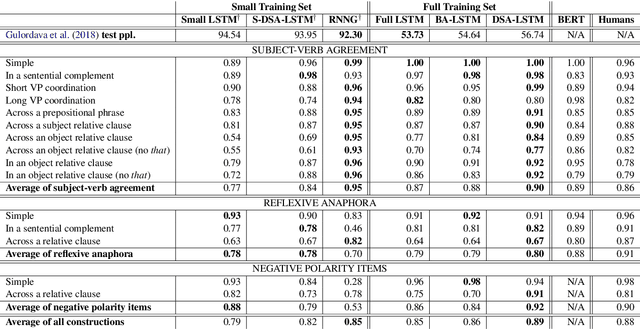
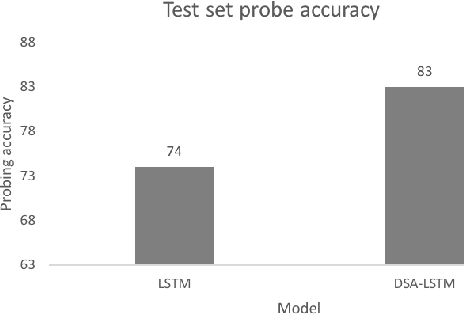
Prior work has shown that, on small amounts of training data, syntactic neural language models learn structurally sensitive generalisations more successfully than sequential language models. However, their computational complexity renders scaling difficult, and it remains an open question whether structural biases are still necessary when sequential models have access to ever larger amounts of training data. To answer this question, we introduce an efficient knowledge distillation (KD) technique that transfers knowledge from a syntactic language model trained on a small corpus to an LSTM language model, hence enabling the LSTM to develop a more structurally sensitive representation of the larger training data it learns from. On targeted syntactic evaluations, we find that, while sequential LSTMs perform much better than previously reported, our proposed technique substantially improves on this baseline, yielding a new state of the art. Our findings and analysis affirm the importance of structural biases, even in models that learn from large amounts of data.