 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining the Noisy Channel Model for Task-Oriented Dialogue
Paper and Code
Mar 18, 2021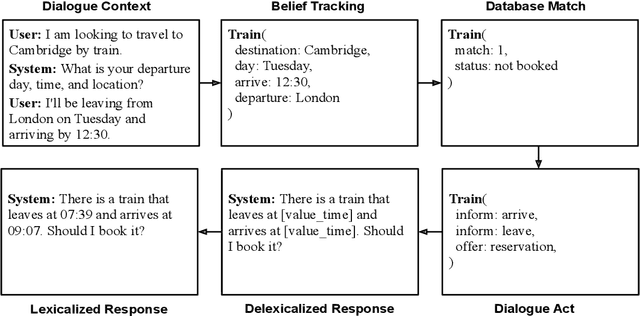



Direct decoding for task-oriented dialogue is known to suffer from the explaining-away effect, manifested in models that prefer short and generic responses. Here we argue for the use of Bayes' theorem to factorize the dialogue task into two models, the distribution of the context given the response, and the prior for the response itself. This approach, an instantiation of the noisy channel model, both mitigates the explaining-away effect and allows the principled incorporation of large pretrained models for the response prior. We present extensive experiments showing that a noisy channel model decodes better responses compared to direct decoding and that a two stage pretraining strategy, employing both open-domain and task-oriented dialogue data, improves over randomly initialized models.